
حق چاپ 2021 نویسندگان TF-Agents.
شروع کنید
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش یک راهنمای گام به گام در مورد نحوه استفاده از کتابخانه TF-Agents برای مشکلات راهزنان متنی است که در آن کنشها (بازوها) ویژگیهای خاص خود را دارند، مانند فهرستی از فیلمهای نشاندادهشده توسط ویژگیها (ژانر، سال انتشار، ...).
پيش نياز
فرض بر این است که خواننده تا حدودی با کتابخانه راهزن از TF-نمایندگی آشنا است، به طور خاص، از طریق کار آموزش برای راهزنان در TF-نمایندگی قبل از خواندن این آموزش است.
راهزنان چند مسلح با ویژگی های بازو
در تنظیمات "کلاسیک" متنی راهزنان چند مسلح، یک عامل در هر مرحله زمانی یک بردار زمینه (معروف به مشاهده) دریافت می کند و باید از مجموعه محدودی از اقدامات شماره گذاری شده (بازوها) انتخاب کند تا پاداش تجمعی خود را به حداکثر برساند.
حال سناریویی را در نظر بگیرید که در آن یک نماینده به کاربر توصیه می کند فیلم بعدی را تماشا کند. هر بار که باید تصمیمی گرفته شود، نماینده اطلاعاتی در مورد کاربر (سابقه تماشا، اولویت ژانر، و غیره) و همچنین فهرست فیلمهایی را که میتواند انتخاب کند، به عنوان زمینه دریافت میکند.
ما می توانید سعی کنید به تدوین و فرموله این مشکل را با در اختیار داشتن اطلاعات کاربران به عنوان متن و بازوها می شود movie_1, movie_2, ..., movie_K ، اما این رویکرد تا به کاستی های متعدد:
- تعداد اکشنها باید تمام فیلمهای موجود در سیستم باشد و اضافه کردن یک فیلم جدید دشوار است.
- نماینده باید برای هر فیلم یک مدل یاد بگیرد.
- شباهت بین فیلم ها در نظر گرفته نمی شود.
بهجای شمارهگذاری فیلمها، میتوانیم کار شهودیتری انجام دهیم: میتوانیم فیلمهایی را با مجموعهای از ویژگیها از جمله ژانر، طول، بازیگران، رتبهبندی، سال و غیره نمایش دهیم. مزایای این رویکرد بسیار زیاد است:
- تعمیم در بین فیلم ها
- عامل فقط یک تابع پاداش را می آموزد که پاداش را با ویژگی های کاربر و فیلم مدل می کند.
- به راحتی می توانید از سیستم حذف کنید یا فیلم های جدید را به سیستم معرفی کنید.
در این تنظیمات جدید، حتی لازم نیست تعداد اقدامات در هر مرحله زمانی یکسان باشد.
راهزنان هر بازو در ماموران TF
مجموعه TF-Agents Bandit به گونهای طراحی شده است که میتوان از آن برای کیف دستی نیز استفاده کرد. محیط های per-arm وجود دارد و همچنین اکثر سیاست ها و عوامل می توانند در حالت per-arm عمل کنند.
قبل از اینکه به کدنویسی یک مثال بپردازیم، به واردات ضروری نیاز داریم.
نصب و راه اندازی
pip install tf-agents
واردات
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
پارامترها - با خیال راحت در اطراف بازی کنید
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
یک محیط ساده برای هر بازو
محیط اتفاقی ثابت، توضیح داد: در سایر آموزش ، یک همتا در هر بازو.
برای مقداردهی اولیه محیط per-arm، باید توابعی را تعریف کرد که تولید می کنند
- جهانی و ویژگی های هر بازو: این توابع هیچ پارامترهای ورودی و تولید تک (جهانی و یا هر بازو) یک بردار ویژگی زمانی که به نام.
- پاداش: این تابع را به عنوان پارامتر الحاق جهانی و یک بردار ویژگی در هر بازو، و تولید یک پاداش است. اساساً این عملکردی است که عامل باید "حدس بزند". در اینجا شایان ذکر است که در مورد هر بازو، تابع پاداش برای هر بازو یکسان است. این یک تفاوت اساسی با حالت راهزن کلاسیک است، که در آن عامل باید توابع پاداش را برای هر بازو به طور مستقل تخمین بزند.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
اکنون ما برای مقداردهی اولیه محیط خود مجهز شده ایم.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
در زیر می توانیم بررسی کنیم که این محیط چه چیزی تولید می کند.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
می بینیم که مشخصات مشاهده یک فرهنگ لغت با دو عنصر است:
- یکی با کلید
'global': این بخش مفهوم جهانی است، با شکل تطبیق پارامترGLOBAL_DIM. - یکی با کلید
'per_arm': این متن در هر بازو است و شکل آن است[NUM_ACTIONS, PER_ARM_DIM]. این قسمت جایگاهی برای ویژگی های بازو برای هر بازو در یک مرحله زمانی است.
نماینده LinUCB
عامل LinUCB الگوریتم Bandit با نام یکسان را پیاده سازی می کند، که پارامتر تابع پاداش خطی را تخمین می زند و در عین حال یک بیضی اطمینان را در اطراف تخمین حفظ می کند. نماینده بازویی را انتخاب می کند که بالاترین پاداش مورد انتظار تخمین زده شده را دارد، با این فرض که پارامتر در بیضی اطمینان قرار دارد.
ایجاد یک عامل مستلزم دانش مشاهده و مشخصات عمل است. هنگام تعریف عامل، ما تنظیم پارامتر بولی accepts_per_arm_features به مجموعه ای True .
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
جریان داده های آموزشی
این بخش نگاهی اجمالی به مکانیک چگونگی تبدیل ویژگی های هر بازو از سیاست به آموزش می دهد. به راحتی به بخش بعدی (تعریف معیار پشیمانی) بروید و در صورت علاقه بعداً به اینجا بازگردید.
ابتدا اجازه دهید نگاهی به مشخصات داده در عامل بیندازیم. training_data_spec صفت مشخص عامل چه عناصر و ساختار داده های آموزشی باید داشته باشد.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
اگر ما یک نگاه هم به observation بخشی از تنظیمات، ما می بینیم که آن را شامل هر بازو از ویژگی های!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
چه اتفاقی برای ویژگی های هر بازو افتاد؟ برای پاسخ به این سوال، ابتدا توجه داشته باشید که زمانی که قطار عامل LinUCB، آن را در هر بازو از ویژگی های تمام سلاح نیاز نیست، بلکه تنها کسانی که از بازوی انتخاب نیاز دارد. از این رو، آن را حس می به رها کردن تانسور از شکل [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] ، به عنوان آن بسیار بی فایده است، به خصوص اگر تعدادی از اقدامات بزرگ است.
اما باز هم ویژگی های هر بازوی بازوی انتخابی باید جایی باشد! برای این منظور، ما مطمئن شوید که از فروشگاه های سیاست LinUCB از ویژگی های این بازوی انتخاب در policy_info زمینه داده های آموزشی:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
ما از شکل که دیدن chosen_arm_features فیلد فقط از بردار ویژگی از یک دست، و خواهد شد که بازوی انتخاب شده است. توجه داشته باشید که policy_info ، و با آن chosen_arm_features ، بخشی از داده های آموزشی است، که ما از بازرسی آموزش تنظیمات داده را دیدم، و در نتیجه آن را در زمان آموزش در دسترس است.
تعریف متریک پشیمانی
قبل از شروع حلقه آموزشی، چند توابع کاربردی را تعریف می کنیم که به محاسبه پشیمانی نماینده ما کمک می کند. این توابع به تعیین پاداش مورد انتظار بهینه با توجه به مجموعه اقدامات (با ویژگی های بازوی آنها) و پارامتر خطی که از عامل پنهان است کمک می کند.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
اکنون همه ما آماده راه اندازی حلقه آموزش راهزن هستیم. درایور زیر مراقب انتخاب اقدامات با استفاده از خط مشی، ذخیره پاداش اقدامات انتخابی در بافر پخش مجدد، محاسبه متریک پشیمانی از پیش تعریف شده و اجرای مرحله آموزش عامل است.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
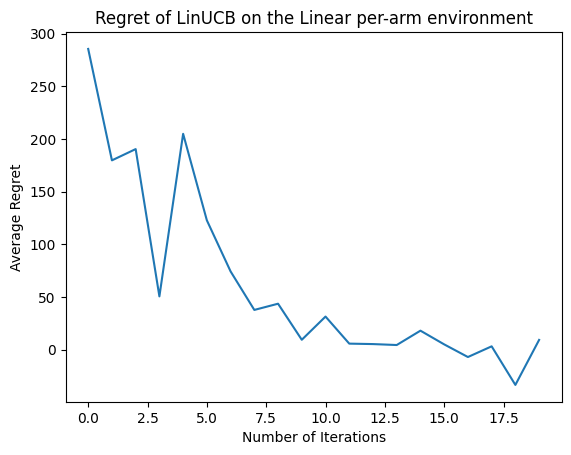
حالا نتیجه را ببینیم. اگر همه چیز را به درستی انجام دهیم، عامل میتواند تابع پاداش خطی را به خوبی تخمین بزند، و بنابراین سیاست میتواند اقداماتی را انتخاب کند که پاداش مورد انتظار آنها نزدیک به پاداش بهینه باشد. این با متریک پشیمانی تعریف شده در بالا نشان داده می شود که پایین می آید و به صفر نزدیک می شود.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
بعد چه می شود؟
در این مثال اجرا در کدهای ما که در آن شما می توانید از عوامل دیگر را نیز انتخاب کنید، از جمله عامل اپسیلون-حریص عصبی .