
কপিরাইট 2021 টিএফ-এজেন্ট লেখক।
এবার শুরু করা যাক
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি প্রাসঙ্গিক দস্যুদের সমস্যাগুলির জন্য TF-এজেন্ট লাইব্রেরি ব্যবহার করার জন্য একটি ধাপে ধাপে নির্দেশিকা যেখানে অ্যাকশন (আর্ম) এর নিজস্ব বৈশিষ্ট্য রয়েছে, যেমন বৈশিষ্ট্যগুলির দ্বারা উপস্থাপিত চলচ্চিত্রগুলির তালিকা (শৈলী, মুক্তির বছর, ...)।
পূর্বশর্ত
ধারণা করা হয় পাঠক মেমরি-এজেন্টস ডাকাত লাইব্রেরির সাথে কিছুটা পরিচিত, বিশেষ করে, এর মাধ্যমে কাজ করেছে মেমরি-এজেন্ট এবং ডাকাত জন্য টিউটোরিয়াল এই টিউটোরিয়াল পড়ার আগে।
আর্ম বৈশিষ্ট্য সহ বহু-সশস্ত্র দস্যু
"ক্লাসিক" কনটেক্সচুয়াল মাল্টি-আর্মড দস্যুদের সেটিং-এ, একজন এজেন্ট প্রতিটি সময় ধাপে একটি প্রসঙ্গ ভেক্টর (ওরফে পর্যবেক্ষণ) পায় এবং সংখ্যাযুক্ত ক্রিয়াগুলির (আর্ম) একটি সীমাবদ্ধ সেট থেকে বেছে নিতে হয় যাতে তার ক্রমবর্ধমান পুরস্কারটি সর্বাধিক করা যায়।
এখন সেই পরিস্থিতি বিবেচনা করুন যেখানে একজন এজেন্ট একজন ব্যবহারকারীকে পরবর্তী সিনেমা দেখার জন্য সুপারিশ করেন। প্রতিবার সিদ্ধান্ত নেওয়ার সময়, এজেন্ট প্রসঙ্গ হিসাবে ব্যবহারকারীর সম্পর্কে কিছু তথ্য (দেখার ইতিহাস, জেনার পছন্দ, ইত্যাদি...), সেইসাথে বেছে নেওয়া সিনেমাগুলির তালিকা গ্রহণ করে।
আমরা প্রসঙ্গ হিসাবে ব্যবহারকারীর তথ্য না থাকার এই সমস্যা প্রণয়ন চেষ্টা করে দেখতে পারেন এবং অস্ত্র হবে movie_1, movie_2, ..., movie_K , কিন্তু এই পদ্ধতির একাধিক ভুলত্রুটি রয়েছে:
- অ্যাকশনের সংখ্যা সিস্টেমের সমস্ত সিনেমা হতে হবে এবং একটি নতুন সিনেমা যোগ করা কষ্টকর।
- এজেন্টকে প্রতিটি সিনেমার জন্য একটি মডেল শিখতে হবে।
- সিনেমার মধ্যে সাদৃশ্য বিবেচনা করা হয় না।
সিনেমার সংখ্যার পরিবর্তে, আমরা আরও স্বজ্ঞাত কিছু করতে পারি: আমরা জেনার, দৈর্ঘ্য, কাস্ট, রেটিং, বছর, ইত্যাদি সহ বৈশিষ্ট্যগুলির একটি সেট সহ চলচ্চিত্রগুলিকে উপস্থাপন করতে পারি। এই পদ্ধতির সুবিধাগুলি বহুগুণে:
- সিনেমা জুড়ে সাধারণীকরণ।
- এজেন্ট শুধুমাত্র একটি পুরষ্কার ফাংশন শিখে যা মডেল ব্যবহারকারী এবং চলচ্চিত্র বৈশিষ্ট্যগুলির সাথে পুরস্কৃত করে।
- সিস্টেম থেকে সরানো, বা নতুন সিনেমা চালু করা সহজ।
এই নতুন সেটিংয়ে, প্রতিটি ধাপে অ্যাকশনের সংখ্যাও একই হতে হবে না।
TF-এজেন্টদের প্রতি-বাহু দস্যু
টিএফ-এজেন্টস ব্যান্ডিট স্যুটটি তৈরি করা হয়েছে যাতে কেউ এটি প্রতি-হাতের ক্ষেত্রেও ব্যবহার করতে পারে। প্রতি-বাহু পরিবেশ রয়েছে, এবং বেশিরভাগ নীতি এবং এজেন্ট প্রতি-আর্ম মোডে কাজ করতে পারে।
আমরা একটি উদাহরণ কোডিং করার আগে, আমাদের প্রয়োজনীয় আমদানি প্রয়োজন।
স্থাপন
pip install tf-agents
আমদানি
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
পরামিতি -- চারপাশে খেলতে নির্দ্বিধায়
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
একটি সাধারণ প্রতি-বাহু পরিবেশ
নিশ্চল সম্ভাব্যতার সূত্রাবলি পরিবেশ, অন্যান্য ব্যাখ্যা টিউটোরিয়াল , প্রতি-হাতি সহযোগীর হয়েছে।
প্রতি-বাহু পরিবেশ শুরু করতে, একজনকে এমন ফাংশন সংজ্ঞায়িত করতে হবে যা উৎপন্ন করে
- বিশ্বব্যাপী এবং প্রতি-হাতি বৈশিষ্ট্য: এই ফাংশন কোন ইনপুট প্যারামিটার আছে এবং যখন নামক একটি একক (গ্লোবাল অথবা প্রতি-হাতি) বৈশিষ্ট্য ভেক্টর উৎপন্ন।
- পুরস্কৃত: এই ফাংশনটি একটি বিশ্বব্যাপী এবং প্রতি-হাতি বৈশিষ্ট্য ভেক্টরের সংযুক্তকরণের প্যারামিটার হিসাবে নেয় এবং একটি পুরস্কার জেনারেট করে। মূলত এটি এমন ফাংশন যা এজেন্টকে "অনুমান" করতে হবে। এখানে এটি লক্ষণীয় যে প্রতি-বাহুর ক্ষেত্রে পুরস্কারের কার্যকারিতা প্রতিটি বাহুতে অভিন্ন। এটি ক্লাসিক দস্যু কেস থেকে একটি মৌলিক পার্থক্য, যেখানে এজেন্টকে প্রতিটি হাতের জন্য পুরষ্কার ফাংশন স্বাধীনভাবে অনুমান করতে হয়।
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
এখন আমরা আমাদের পরিবেশ শুরু করতে সজ্জিত।
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
নীচে আমরা এই পরিবেশটি কী উত্পাদন করে তা পরীক্ষা করতে পারি।
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -9., -4., -3., 3., 5., -9., 6., -5., 4., -8., -6.,
-1., -7., -5., 7., 8., 2., 5., -8., 0., -4., 4.,
-1., -1., -4., 6., 8., 6., 9., -5., -1., -1., 2.,
5., -1., -8., 1., 0., 0., 5.],
[ 5., 7., 0., 3., -8., -7., -5., -2., -8., -7., -7.,
-8., 5., -3., 5., 4., -5., 2., -6., -10., -4., -2.,
2., -1., -1., 8., -7., 7., 2., -3., -10., -1., -4.,
-7., 3., 4., 8., -2., 9., 5.],
[ -6., -2., -1., -1., 6., -3., 4., 9., 2., -2., 3.,
1., 0., -7., 5., 5., -8., -4., 5., 7., -10., -4.,
5., 6., 8., -10., 7., -1., -8., -8., -6., -6., 4.,
-10., -8., 3., 8., -9., -5., 8.],
[ -1., 8., -8., -7., 9., 2., -6., 8., 4., -2., 1.,
8., -4., 3., 1., -6., -9., 3., -5., 7., -9., 6.,
6., -3., 1., 2., -1., 3., 7., 4., -8., 1., 1.,
3., -4., 1., -4., -5., -9., 4.],
[ -9., 8., 9., -8., 2., 9., -1., -9., -1., 9., -8.,
-4., 1., 1., 9., 6., -6., -10., -6., 2., 6., -4.,
-7., -2., -7., -8., -4., 5., -6., -1., 8., -3., -7.,
4., -9., -9., 6., -9., 6., -2.],
[ 0., -6., -5., -8., -10., 2., -4., 9., 9., -1., 5.,
-7., -1., -3., -10., -10., 3., -2., -7., -9., -4., -8.,
-4., -1., 7., -2., -4., -4., 9., 2., -2., -8., 6.,
5., -4., 7., 0., 6., -3., 2.],
[ 8., 5., 3., 5., 9., 4., -10., -5., -4., -4., -5.,
3., 5., -4., 9., -2., -7., -6., -2., -8., -7., -10.,
0., -2., 3., 1., -10., -8., 3., 9., -5., -6., 1.,
-7., -1., 3., -7., -2., 1., -1.],
[ 3., 9., 8., 6., -2., 9., 9., 7., 0., 5., -5.,
6., 9., 3., 2., 9., 4., -1., -3., 3., -1., -4.,
-9., -1., -3., 8., 0., 4., -1., 4., -3., 4., -5.,
-3., -6., -4., 7., -9., -7., -1.],
[ 5., -1., 9., -5., 8., 7., -7., -5., 0., -4., -5.,
6., -3., -1., 7., 3., -7., -9., 6., 4., 9., 6.,
-3., 3., -2., -6., -4., -7., -5., -6., -2., -1., -9.,
-4., -9., -2., -7., -6., -3., 6.],
[ -7., 1., -8., 1., -8., -9., 5., 1., -4., -2., -5.,
3., -1., -4., -4., 5., 0., -10., -4., -1., -5., 3.,
8., -5., -4., -10., -8., -6., -10., -1., -6., 1., 7.,
8., 6., -2., -4., -9., 7., -1.],
[ -2., 3., 8., -5., 0., 5., 8., -5., 6., -8., 5.,
8., -5., -5., -5., -10., 4., 8., -4., -7., 4., -6.,
-9., -8., -5., 4., -1., -2., -7., -10., -6., -8., -6.,
3., 1., 6., 9., 6., -8., -3.],
[ 9., -6., -2., -10., 2., -8., 8., -7., -5., 8., -10.,
4., -5., 9., 7., 9., -2., -9., -5., -2., 9., 0.,
-6., 2., 4., 6., -7., -4., -5., -7., -8., -8., 8.,
-7., -1., -5., 0., -7., 7., -6.],
[ -1., -3., 1., 8., 4., 7., -1., -8., -4., 6., 9.,
5., -10., 4., -4., 5., -2., 0., 3., 4., 3., -5.,
-2., 7., 4., -4., -9., 9., -6., -5., -8., 4., -10.,
-6., 3., 0., 6., -10., 4., 3.],
[ 8., 8., -5., 0., -7., 5., -6., -8., 2., -3., -5.,
5., 0., 6., -10., 3., -4., 1., -8., -9., 6., -5.,
5., -10., 1., 0., 3., 5., 2., -9., -6., 9., 7.,
9., -10., 4., -4., -10., -5., 1.],
[ 8., 3., -5., -2., -8., -6., 6., -7., 8., 1., -8.,
0., -2., 3., -6., 0., -10., 6., -8., -2., -5., 4.,
-1., -9., -7., 3., -1., -4., -1., -10., -3., -7., -3.,
4., -7., -6., -1., 9., -3., 2.],
[ 8., 7., 6., -5., -3., 0., 1., -2., 0., -3., 9.,
-8., 5., 1., 1., 1., -5., 4., -4., 0., -4., -3.,
7., -10., 3., 6., 4., 5., 2., -7., 0., -3., -5.,
2., -6., 4., 5., 8., -1., -3.],
[ 8., -9., -4., 8., -2., 9., 5., 5., -3., -4., 0.,
-5., 5., -2., -10., -4., -3., 5., 8., 6., -2., -2.,
-1., -8., -5., -9., 1., -1., 5., 6., 4., 9., -5.,
6., -2., 7., -7., -9., 4., 2.],
[ 2., 4., 6., 2., 6., -6., -2., 5., 8., 1., 3.,
8., 6., 9., -3., -1., 4., 7., -5., 7., 0., -10.,
9., -6., -4., -7., 1., -2., -2., 3., -1., 2., 5.,
8., 4., -9., 1., -4., 9., 6.],
[ -8., -5., 9., 3., 9., -10., -8., 3., -8., 0., -4.,
-8., -3., -4., -3., 0., 8., 3., -10., 7., 7., -3.,
8., 4., -3., 9., 3., 7., 2., 7., -8., -3., -4.,
-7., 3., -9., -10., 2., 5., 7.],
[ 5., -7., -8., 6., -8., 1., -8., 4., 2., 6., -6.,
-5., 4., -1., 3., -8., -3., 6., 5., -5., 1., -7.,
8., -10., 8., 1., 3., 7., 2., 2., -1., 1., -3.,
7., 1., 6., -6., 0., -9., 6.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 5., -6., 4., ..., -3., 3., 4.],
[-5., -6., -4., ..., 3., 4., -4.],
[ 1., -1., 5., ..., -1., -3., 1.],
...,
[ 3., 3., -5., ..., 4., 4., 0.],
[ 5., 1., -3., ..., -2., -2., -3.],
[-6., 4., 2., ..., 4., 5., -5.]],
[[-5., -3., 1., ..., -2., -1., 1.],
[ 1., 4., -1., ..., -1., -4., -4.],
[ 4., -6., 5., ..., 2., -2., 4.],
...,
[ 0., 4., -4., ..., -1., -3., 1.],
[ 3., 4., 5., ..., -5., -2., -2.],
[ 0., 4., -3., ..., 5., 1., 3.]],
[[-2., -6., -6., ..., -6., 1., -5.],
[ 4., 5., 5., ..., 1., 4., -4.],
[ 0., 0., -3., ..., -5., 0., -2.],
...,
[-3., -1., 4., ..., 5., -2., 5.],
[-3., -6., -2., ..., 3., 1., -5.],
[ 5., -3., -5., ..., -4., 4., -5.]],
...,
[[ 4., 3., 0., ..., 1., -6., 4.],
[-5., -3., 5., ..., 0., -1., -5.],
[ 0., 4., 3., ..., -2., 1., -3.],
...,
[-5., -2., -5., ..., -5., -5., -2.],
[-2., 5., 4., ..., -2., -2., 2.],
[-1., -4., 4., ..., -5., 2., -3.]],
[[-1., -4., 4., ..., -3., -5., 4.],
[-4., -6., -2., ..., -1., -6., 0.],
[ 0., 0., 5., ..., 4., -4., 0.],
...,
[ 2., 3., 5., ..., -6., -5., 5.],
[-5., -5., 2., ..., 0., 4., -2.],
[ 4., -5., -4., ..., -5., -5., -1.]],
[[ 3., 0., 2., ..., 2., 1., -3.],
[-5., -4., 3., ..., -6., 0., -2.],
[-4., -5., 3., ..., -6., -3., 0.],
...,
[-6., -6., 4., ..., -1., -5., -2.],
[-4., 3., -1., ..., 1., 4., 4.],
[ 5., 2., 2., ..., -3., 1., -4.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-130.17787 344.98013 371.39893 75.433975 396.35742
-176.46881 56.62174 -158.03278 491.3239 -156.10696
-1.0527252 -264.42285 22.356699 -395.89832 125.951546
142.99467 -322.3012 -24.547596 -159.47539 -44.123775 ], shape=(20,), dtype=float32)
আমরা দেখতে পাচ্ছি যে পর্যবেক্ষণ স্পেক দুটি উপাদান সহ একটি অভিধান:
- কী দিয়ে এক
'global': এই গ্লোবাল প্রসঙ্গ অংশ, পরামিতি মিলে আকৃতি সঙ্গেGLOBAL_DIM। - কী দিয়ে এক
'per_arm': এই প্রতি-হাতি প্রসঙ্গ, এবং তার আকৃতি হয়[NUM_ACTIONS, PER_ARM_DIM]। এই অংশটি একটি সময়ের ধাপে প্রতিটি বাহুর জন্য বাহু বৈশিষ্ট্যের স্থানধারক।
LinUCB এজেন্ট
LinUCB এজেন্ট অভিন্ন নামযুক্ত ব্যান্ডিট অ্যালগরিদম প্রয়োগ করে, যা রৈখিক পুরস্কার ফাংশনের পরামিতি অনুমান করে এবং অনুমানের চারপাশে একটি আত্মবিশ্বাস উপবৃত্তাকার বজায় রাখে। এজেন্ট সেই বাহুটি বেছে নেয় যার সর্বোচ্চ আনুমানিক প্রত্যাশিত পুরষ্কার রয়েছে, অনুমান করে যে প্যারামিটারটি আত্মবিশ্বাসের উপবৃত্তের মধ্যে রয়েছে।
একটি এজেন্ট তৈরি করার জন্য পর্যবেক্ষণের জ্ঞান এবং কর্মের স্পেসিফিকেশন প্রয়োজন। যখন এজেন্ট সংজ্ঞা, আমরা সেট বুলিয়ান প্যারামিটার accepts_per_arm_features সেট True ।
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
প্রশিক্ষণ তথ্য প্রবাহ
পলিসি থেকে ট্রেনিং পর্যন্ত প্রতি-বাহু বৈশিষ্ট্যগুলি কীভাবে যায় তার মেকানিক্সের মধ্যে এই বিভাগটি এক ঝলক দেখায়। নির্দ্বিধায় পরবর্তী বিভাগে যান (অনুশোচনা মেট্রিক সংজ্ঞায়িত করা) এবং আগ্রহী হলে পরে এখানে ফিরে আসুন।
প্রথমে, আমাদের এজেন্টের ডেটা স্পেসিফিকেশনের দিকে নজর দেওয়া যাক। training_data_spec এজেন্ট নির্দিষ্ট করে কি উপাদান এবং গঠন প্রশিক্ষণ তথ্য আছে উচিত অ্যাট্রিবিউট।
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
আমরা যদি পুরো বিষয়টা বিস্তারিত বিবেচনা আছে observation বৈশিষ্ট অংশ, আমরা দেখতে যে এটা প্রতি-হাতি বৈশিষ্ট্য ধারণ করে না!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
প্রতি বাহু বৈশিষ্ট্য কি ঘটেছে? এই প্রশ্নের উত্তর দিতে, প্রথমে আমরা মনে রাখবেন যে যখন LinUCB এজেন্ট ট্রেন, এটা সব অস্ত্র প্রতি-হাতি বৈশিষ্ট্য প্রয়োজন নেই, এটি শুধুমাত্র মনোনীত বাহু সেই প্রয়োজন। অত: পর, এটা আকৃতি টেন্সর ড্রপ জ্ঞান করে তোলে [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM] , যেমন এটা খুবই অযথা, বিশেষ করে যদি কর্মের সংখ্যা বড়।
কিন্তু তবুও, বাছাই করা বাহুগুলির প্রতি-বাহু বৈশিষ্ট্যগুলি কোথাও থাকতে হবে! এই শেষ, আমরা নিশ্চিত যে LinUCB নীতি দোকানে মধ্যে মনোনীত বাহু বৈশিষ্ট্য policy_info প্রশিক্ষণ ডেটার ক্ষেত্র:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
আমরা আকৃতি থেকে দেখতে chosen_arm_features ক্ষেত্রের একটি বাহুর শুধুমাত্র বৈশিষ্ট্য ভেক্টর আছে, এবং যে মনোনীত বাহু হবে। লক্ষ্য করুন policy_info , এবং এটি সঙ্গে chosen_arm_features হিসাবে আমরা প্রশিক্ষণ ডেটা বৈশিষ্ট পরিদর্শন থেকে দেখে, প্রশিক্ষণ ডেটা অংশ, এবং এইভাবে এটি প্রশিক্ষণের সময় পাওয়া যাবে।
অনুশোচনা মেট্রিক সংজ্ঞায়িত করা
প্রশিক্ষণ লুপ শুরু করার আগে, আমরা কিছু ইউটিলিটি ফাংশন সংজ্ঞায়িত করি যা আমাদের এজেন্টের অনুশোচনা গণনা করতে সাহায্য করে। এই ফাংশনগুলি কর্মের সেট (তাদের বাহু বৈশিষ্ট্য দ্বারা প্রদত্ত) এবং এজেন্টের কাছ থেকে লুকানো রৈখিক পরামিতি প্রদত্ত সর্বোত্তম প্রত্যাশিত পুরষ্কার নির্ধারণ করতে সহায়তা করে।
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
এখন আমরা আমাদের দস্যু প্রশিক্ষণ লুপ শুরু করার জন্য প্রস্তুত। নীচের ড্রাইভার নীতিটি ব্যবহার করে ক্রিয়াগুলি বেছে নেওয়া, রিপ্লে বাফারে নির্বাচিত অ্যাকশনের পুরষ্কার সংরক্ষণ, পূর্বনির্ধারিত অনুশোচনা মেট্রিক গণনা করা এবং এজেন্টের প্রশিক্ষণ পদক্ষেপ চালানোর যত্ন নেয়।
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmp/ipykernel_12052/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
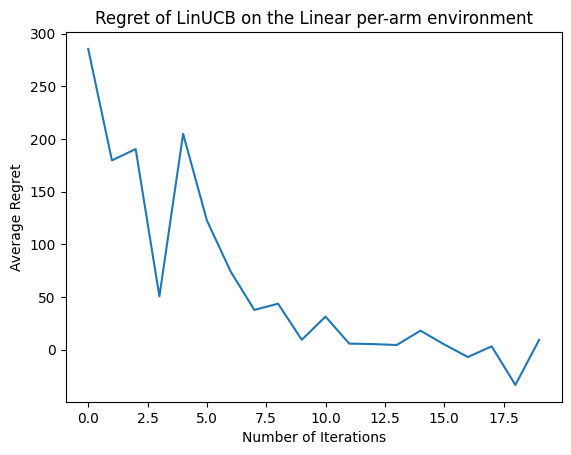
এবার ফলাফল দেখা যাক। আমরা যদি সবকিছু ঠিকঠাক করে থাকি, তাহলে এজেন্ট লিনিয়ার রিওয়ার্ড ফাংশনটি ভালোভাবে অনুমান করতে সক্ষম হয় এবং এইভাবে নীতিটি এমন অ্যাকশন বেছে নিতে পারে যার প্রত্যাশিত পুরষ্কারটি সর্বোত্তমটির কাছাকাছি। এটি আমাদের উপরোক্ত সংজ্ঞায়িত অনুশোচনা মেট্রিক দ্বারা নির্দেশিত হয়, যা নিচে নেমে শূন্যের কাছাকাছি চলে যায়।
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
এরপর কি?
উপরোক্ত উদাহরণে হয় বাস্তবায়িত আমাদের কোডবেস যেখানে ভাল হিসাবে আপনি সহ অন্যান্য এজেন্ট থেকে চয়ন করতে পারেন, নিউরাল Epsilon-লোলুপ এজেন্ট ।