
कॉपीराइट 2020 टीएफ-एजेंट लेखक।
शुरू हो जाओ
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
सेट अप
यदि आपने निम्नलिखित निर्भरताएँ स्थापित नहीं की हैं, तो चलाएँ:
pip install tf-agents
आयात
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
परिचय
मल्टी-आर्म्ड बैंडिट समस्या (एमएबी) सुदृढीकरण सीखने का एक विशेष मामला है: एक एजेंट पर्यावरण की कुछ स्थिति को देखकर कुछ कार्रवाई करके पर्यावरण में पुरस्कार एकत्र करता है। सामान्य आरएल और एमएबी के बीच मुख्य अंतर यह है कि एमएबी में, हम मानते हैं कि एजेंट द्वारा की गई कार्रवाई पर्यावरण की अगली स्थिति को प्रभावित नहीं करती है। इसलिए, एजेंट राज्य परिवर्तन, पिछले कार्यों के लिए क्रेडिट पुरस्कार, या इनाम-समृद्ध राज्यों को प्राप्त करने के लिए "आगे की योजना" का मॉडल नहीं बनाते हैं।
अन्य आरएल डोमेन में के रूप में, एक एमएबी एजेंट के लक्ष्य के लिए एक नीति को मिल रहा है कि एकत्र संभव हो उतना पुरस्कार के रूप में। हालांकि, यह एक गलती होगी कि हमेशा उस कार्रवाई का फायदा उठाने की कोशिश करें जो उच्चतम इनाम का वादा करती है, क्योंकि तब एक मौका है कि अगर हम पर्याप्त खोज नहीं करते हैं तो हम बेहतर कार्यों से चूक जाते हैं। यह मुख्य समस्या में (एमएबी) को हल किया जा करने के लिए, अक्सर अन्वेषण अत्यधिक दोहन दुविधा कहा जाता है।
दस्यु वातावरण, नीतियों, और एमएबी के लिए एजेंटों की उपनिर्देशिका में पाया जा सकता tf_agents / डाकुओं ।
वातावरण
TF-एजेंटों में, पर्यावरण वर्ग, वर्तमान स्थिति के बारे में जानकारी देने की भूमिका में कार्य करता है (इस अवलोकन या संदर्भ में कहा जाता है), इनपुट के रूप में एक कार्रवाई प्राप्त एक राज्य संक्रमण प्रदर्शन, और एक इनाम outputting। यह वर्ग किसी एपिसोड के समाप्त होने पर रीसेट करने का भी ध्यान रखता है, ताकि एक नया एपिसोड शुरू हो सके। यह एक फोन करके महसूस किया है reset समारोह जब एक राज्य के रूप में प्रकरण के "अंतिम" लेबल किया गया है।
अधिक जानकारी के लिए, TF-एजेंटों वातावरण ट्यूटोरियल ।
जैसा कि ऊपर उल्लेख किया गया है, एमएबी सामान्य आरएल से अलग है कि क्रियाएं अगले अवलोकन को प्रभावित नहीं करती हैं। एक और अंतर यह है कि डाकुओं में, कोई "एपिसोड" नहीं होते हैं: हर बार कदम एक नए अवलोकन के साथ शुरू होता है, पिछले समय के चरणों से स्वतंत्र।
यकीन है कि टिप्पणियों स्वतंत्र और अमूर्त दूर आर एल एपिसोड की अवधारणा के लिए कर रहे हैं बनाने के लिए हम में से उपवर्गों परिचय PyEnvironment और TFEnvironment : BanditPyEnvironment और BanditTFEnvironment । ये वर्ग दो निजी सदस्य कार्यों को उजागर करते हैं जिन्हें उपयोगकर्ता द्वारा कार्यान्वित किया जाना बाकी है:
@abc.abstractmethod
def _observe(self):
तथा
@abc.abstractmethod
def _apply_action(self, action):
_observe समारोह एक अवलोकन देता है। फिर, नीति इस अवलोकन के आधार पर कोई कार्रवाई चुनती है। _apply_action एक इनपुट के रूप कि कार्रवाई प्राप्त करता है, और इसी पुरस्कार देता है। इन निजी सदस्य कार्यों कार्यों के द्वारा कहा जाता है reset और step , क्रमशः।
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
अंतरिम सार वर्ग औजार ऊपर PyEnvironment के _reset और _step कार्य करता है और उजागर करता सार कार्यों _observe और _apply_action उपवर्गों द्वारा कार्यान्वित किया जाना है।
एक साधारण उदाहरण पर्यावरण वर्ग
निम्न वर्ग एक बहुत ही सरल वातावरण देता है जिसके लिए अवलोकन -2 और 2 के बीच एक यादृच्छिक पूर्णांक है, 3 संभावित क्रियाएं हैं (0, 1, 2), और इनाम कार्रवाई और अवलोकन का उत्पाद है।
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
अब हम इस वातावरण का उपयोग अवलोकन प्राप्त करने और अपने कार्यों के लिए पुरस्कार प्राप्त करने के लिए कर सकते हैं।
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
टीएफ वातावरण
एक उपवर्गीकरण द्वारा एक डाकू पर्यावरण को परिभाषित कर सकते BanditTFEnvironment इसी तरह आर एल वातावरण के लिए, या, एक एक को परिभाषित कर सकते BanditPyEnvironment और साथ लपेट TFPyEnvironment । सादगी के लिए, हम इस ट्यूटोरियल में बाद वाले विकल्प के साथ जाते हैं।
tf_environment = tf_py_environment.TFPyEnvironment(environment)
नीतियों
एक डाकू समस्या में एक नीति एक आर एल समस्या के रूप में एक ही तरह से काम करता है: यह एक कार्रवाई (या कार्यों की एक वितरण) प्रदान करता है इनपुट के रूप में एक अवलोकन दिया।
अधिक जानकारी के लिए, TF-एजेंटों नीति ट्यूटोरियल ।
एक एक बना सकते हैं: वातावरण के साथ ही, एक ऐसी नीति के निर्माण के लिए दो तरीके हैं PyPolicy और साथ लपेट TFPyPolicy , या सीधे एक बनाने TFPolicy । यहां हम प्रत्यक्ष विधि के साथ जाने का चुनाव करते हैं।
चूंकि यह उदाहरण काफी सरल है, हम इष्टतम नीति को मैन्युअल रूप से परिभाषित कर सकते हैं। कार्रवाई केवल अवलोकन के संकेत पर निर्भर करती है, 0 कब नकारात्मक है और 2 कब सकारात्मक है।
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
अब हम पर्यावरण से एक अवलोकन का अनुरोध कर सकते हैं, नीति को एक क्रिया चुनने के लिए बुला सकते हैं, फिर पर्यावरण इनाम का उत्पादन करेगा:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
जिस तरह से दस्यु वातावरण को लागू किया जाता है, यह सुनिश्चित करता है कि हर बार जब हम एक कदम उठाते हैं, तो हमें न केवल हमारे द्वारा की गई कार्रवाई के लिए इनाम मिलता है, बल्कि अगला अवलोकन भी मिलता है।
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
एजेंटों
अब जब हमारे पास दस्यु वातावरण और दस्यु नीतियां हैं, तो यह दस्यु एजेंटों को भी परिभाषित करने का समय है, जो प्रशिक्षण नमूनों के आधार पर नीति को बदलने का ध्यान रखते हैं।
दस्यु एजेंटों के लिए एपीआई आर एल एजेंटों की है कि से अलग नहीं है: एजेंट बस को लागू करने की जरूरत है _initialize और _train विधियों, और परिभाषित एक policy और एक collect_policy ।
एक अधिक जटिल वातावरण
इससे पहले कि हम अपने दस्यु एजेंट को लिखें, हमारे पास ऐसा वातावरण होना चाहिए जिसका पता लगाना थोड़ा कठिन हो। बातें सिर्फ एक छोटा सा को मसाले के लिए, अगले वातावरण या तो हमेशा दे देंगे reward = observation * action या reward = -observation * action । यह तब तय किया जाएगा जब पर्यावरण शुरू किया जाएगा।
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
एक अधिक जटिल नीति
अधिक जटिल वातावरण के लिए अधिक जटिल नीति की आवश्यकता होती है। हमें ऐसी नीति की आवश्यकता है जो अंतर्निहित पर्यावरण के व्यवहार का पता लगा सके। ऐसी तीन स्थितियां हैं जिनसे नीति को निपटने की आवश्यकता है:
- एजेंट को अभी तक पता नहीं चला है कि पर्यावरण का कौन सा संस्करण चल रहा है।
- एजेंट ने पाया कि परिवेश का मूल संस्करण चल रहा है।
- एजेंट ने पाया कि परिवेश का फ़्लिप किया गया संस्करण चल रहा है।
हम एक परिभाषित tf_variable नामित _situation में यह जानकारी मूल्यों के रूप में एन्कोड स्टोर करने के लिए [0, 2] , तो नीति व्यवहार तदनुसार बनाते हैं।
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
एजेंट
अब उस एजेंट को परिभाषित करने का समय है जो पर्यावरण के संकेत का पता लगाता है और नीति को उचित रूप से निर्धारित करता है।
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
उपरोक्त कोड में, एजेंट नीति को परिभाषित करता है, और चर situation एजेंट और नीति के द्वारा साझा किया जाता है।
इसके अलावा, पैरामीटर experience की _train समारोह एक प्रक्षेपवक्र है:
ट्रेजेकटोरीज़
TF-एजेंटों में, trajectories tuples है कि पिछले कदम उठाए से नमूने शामिल नाम हैं। फिर इन नमूनों का उपयोग एजेंट द्वारा नीति को प्रशिक्षित और अद्यतन करने के लिए किया जाता है। आरएल में, प्रक्षेपवक्र में वर्तमान स्थिति, अगली स्थिति और वर्तमान प्रकरण समाप्त हो गया है या नहीं, इसके बारे में जानकारी होनी चाहिए। चूंकि दस्यु दुनिया में हमें इन चीजों की आवश्यकता नहीं है, हम एक प्रक्षेपवक्र बनाने के लिए एक सहायक कार्य स्थापित करते हैं:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
एक एजेंट को प्रशिक्षण
अब हमारे दस्यु एजेंट को प्रशिक्षित करने के लिए सभी टुकड़े तैयार हैं।
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
आउटपुट से कोई भी देख सकता है कि दूसरे चरण के बाद (जब तक कि पहले चरण में अवलोकन 0 नहीं था), पॉलिसी सही तरीके से कार्रवाई का चयन करती है और इस प्रकार एकत्र किया गया इनाम हमेशा गैर-नकारात्मक होता है।
एक वास्तविक प्रासंगिक दस्यु उदाहरण
शेष ट्यूटोरियल में, हम पहले से लागू किया का उपयोग वातावरण और एजेंटों TF-एजेंटों डाकू पुस्तकालय की।
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
रैखिक भुगतान कार्यों के साथ स्थिर स्टोकेस्टिक पर्यावरण
इस उदाहरण में प्रयुक्त वातावरण है StationaryStochasticPyEnvironment । यह वातावरण अवलोकन (संदर्भ) देने के लिए पैरामीटर ए (आमतौर पर शोर) फ़ंक्शन के रूप में लेता है, और प्रत्येक हाथ के लिए एक (शोर भी) फ़ंक्शन लेता है जो दिए गए अवलोकन के आधार पर इनाम की गणना करता है। हमारे उदाहरण में, हम एक डी-डायमेंशनल क्यूब से समान रूप से संदर्भ का नमूना लेते हैं, और इनाम फ़ंक्शन संदर्भ के रैखिक कार्य हैं, साथ ही कुछ गाऊसी शोर भी हैं।
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
लिनयूसीबी एजेंट
औजार नीचे एजेंट LinUCB एल्गोरिथ्म।
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
पछतावा मीट्रिक
डाकू 'सबसे महत्वपूर्ण मीट्रिक अफसोस, एजेंट द्वारा एकत्र इनाम और पर्यावरण के इनाम कार्यों की पहुंच न हो दैवज्ञ नीति की उम्मीद इनाम के बीच अंतर के रूप में गणना है। RegretMetric इस प्रकार एक baseline_reward_fn समारोह है कि एक अवलोकन दिया सबसे अच्छा प्राप्त की उम्मीद इनाम की गणना करता है की जरूरत है। हमारे उदाहरण के लिए, हमें पर्यावरण के लिए पहले से परिभाषित इनाम कार्यों के अधिकतम नो-शोर समकक्ष लेने की आवश्यकता है।
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
प्रशिक्षण
अब हमने ऊपर बताए गए सभी घटकों को एक साथ रखा है: पर्यावरण, नीति और एजेंट। हम एक ड्राइवर की मदद से पर्यावरण और उत्पादन प्रशिक्षण डेटा पर नीति चलाते हैं, और डेटा पर एजेंट को प्रशिक्षित।
ध्यान दें कि दो पैरामीटर हैं जो एक साथ उठाए गए कदमों की संख्या को निर्दिष्ट करते हैं। num_iterations निर्दिष्ट करता है कि कितनी बार हम ट्रेनर पाश चलाने के लिए, जबकि चालक ले जाएगा steps_per_loop यात्रा प्रति चरणों। इन दोनों मापदंडों को रखने के पीछे मुख्य कारण यह है कि कुछ ऑपरेशन प्रति पुनरावृत्ति किए जाते हैं, जबकि कुछ हर कदम पर चालक द्वारा किए जाते हैं। उदाहरण के लिए, एजेंट की train समारोह केवल यात्रा प्रति एक बार कहा जाता है। यहां ट्रेड-ऑफ यह है कि यदि हम अधिक बार प्रशिक्षण लेते हैं तो हमारी नीति "नए सिरे" है, दूसरी ओर, बड़े बैचों में प्रशिक्षण अधिक समय कुशल हो सकता है।
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
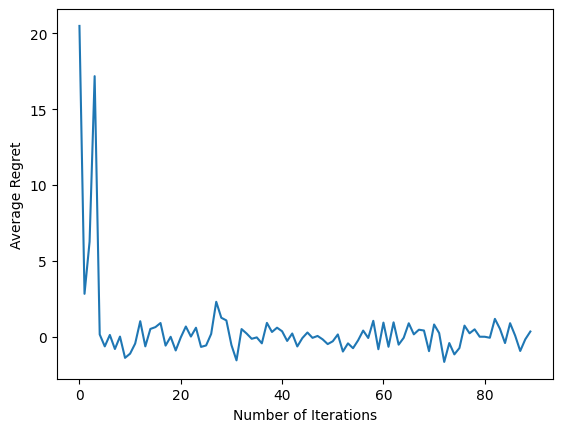
अंतिम कोड स्निपेट चलाने के बाद, परिणामी प्लॉट (उम्मीद है) से पता चलता है कि औसत अफसोस कम हो रहा है क्योंकि एजेंट को प्रशिक्षित किया जाता है और नीति यह पता लगाने में बेहतर होती है कि अवलोकन को देखते हुए सही कार्रवाई क्या है।
आगे क्या होगा?
अधिक काम कर रहे उदाहरण देखने के लिए, कृपया देखें डाकुओं / एजेंट / उदाहरण निर्देशिका है कि विभिन्न एजेंटों और वातावरण के लिए तैयार-टू-रन उदाहरण।
TF-Agents पुस्तकालय प्रति-हाथ सुविधाओं के साथ बहु-सशस्त्र डाकुओं को संभालने में भी सक्षम है। इसके लिए हम प्रति हाथ दस्यु के लिए पाठक उल्लेख ट्यूटोरियल ।