
Copyright 2020 Autores de TF-Agents.
Empezar
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Configuración
Si no ha instalado las siguientes dependencias, ejecute:
pip install tf-agents
Importaciones
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
Introducción
El problema del bandido de armas múltiples (MAB) es un caso especial de aprendizaje por refuerzo: un agente recolecta recompensas en un entorno tomando algunas acciones después de observar algún estado del entorno. La principal diferencia entre RL general y MAB es que en MAB, asumimos que la acción tomada por el agente no influye en el siguiente estado del medio ambiente. Por lo tanto, los agentes no modelan las transiciones de estado, no atribuyen recompensas a acciones pasadas ni "planifican con anticipación" para llegar a estados ricos en recompensas.
Al igual que en otros dominios RL, el objetivo de un agente de MAB es encontrar una política que se acumula tanta recompensa como sea posible. Sin embargo, sería un error intentar siempre explotar la acción que promete la mayor recompensa, porque entonces existe la posibilidad de que perdamos mejores acciones si no exploramos lo suficiente. Este es el principal problema a resolver en (MAB), a menudo llamado el dilema de exploración de la explotación.
Ambientes Bandit, políticas, y agentes para MAB se pueden encontrar en los subdirectorios de tf_agents / bandidos .
Ambientes
En TF-agentes, la clase de entorno sirve la función de dar información sobre el estado actual (esto se llama observación o contexto), la recepción de una acción como entrada, la realización de una transición de estado, y la salida de una recompensa. Esta clase también se encarga de reiniciar cuando termina un episodio, para que pueda comenzar un nuevo episodio. Esto se realiza llamando a un reset función cuando un estado es etiquetado como "último" del episodio.
Para más detalles, ver los TF-Agentes entornos tutorial .
Como se mencionó anteriormente, MAB se diferencia del RL general en que las acciones no influyen en la siguiente observación. Otra diferencia es que en Bandits no hay "episodios": cada paso de tiempo comienza con una nueva observación, independientemente de los pasos de tiempo anteriores.
Para asegurarse de que las observaciones son independientes y a distancia abstracta del concepto de episodios RL, introducimos subclases de PyEnvironment y TFEnvironment : BanditPyEnvironment y BanditTFEnvironment . Estas clases exponen dos funciones miembro privadas que quedan por implementar por parte del usuario:
@abc.abstractmethod
def _observe(self):
y
@abc.abstractmethod
def _apply_action(self, action):
El _observe función devuelve una observación. Luego, la política elige una acción basada en esta observación. El _apply_action recibe esa acción como una entrada, y devuelve la recompensa correspondiente. Estas funciones miembro privadas son llamados por las funciones reset y step , respectivamente.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Los anteriores instrumentos provisionales clase abstracta PyEnvironment 's _reset y _step funciones y expone las funciones abstractas _observe y _apply_action a ser implementadas por las subclases.
Una clase de entorno de ejemplo simple
La siguiente clase da un entorno muy simple para el cual la observación es un número entero aleatorio entre -2 y 2, hay 3 acciones posibles (0, 1, 2) y la recompensa es el producto de la acción y la observación.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Ahora podemos usar este entorno para obtener observaciones y recibir recompensas por nuestras acciones.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Entornos TF
Se puede definir un entorno de bandido subclasificando BanditTFEnvironment , o, de manera similar a los entornos de RL, se puede definir un BanditPyEnvironment y se envuelve con TFPyEnvironment . En aras de la simplicidad, elegimos la última opción en este tutorial.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Políticas
Una política en un problema bandido funciona de la misma manera que en un problema de RL: proporciona una acción (o una distribución de acciones), dada una observación como entrada.
Para más detalles, ver el tutorial TF-Agentes Política .
Al igual que con los entornos, hay dos maneras de construir una política: se puede crear un PyPolicy y se envuelve con TFPyPolicy , o crear directamente una TFPolicy . Aquí elegimos ir con el método directo.
Dado que este ejemplo es bastante simple, podemos definir la política óptima manualmente. La acción solo depende del signo de la observación, 0 cuando es negativo y 2 cuando es positivo.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Ahora podemos solicitar una observación del entorno, llamar a la política para elegir una acción, luego el entorno generará la recompensa:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
La forma en que se implementan los entornos de bandidos garantiza que cada vez que damos un paso, no solo recibimos la recompensa por la acción que tomamos, sino también la siguiente observación.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Agentes
Ahora que tenemos entornos de bandidos y políticas de bandidos, es hora de definir también agentes bandidos, que se encargan de cambiar la política en base a muestras de entrenamiento.
El API para los agentes de bandidos no difiere del de los agentes RL: el agente sólo necesita para implementar el _initialize y _train métodos, y definir una policy y un collect_policy .
Un entorno más complicado
Antes de escribir nuestro agente bandido, necesitamos tener un entorno que sea un poco más difícil de entender. Para condimentar las cosas un poco, el siguiente entorno sea siempre dará reward = observation * action o reward = -observation * action . Esto se decidirá cuando se inicialice el entorno.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Una política más complicada
Un entorno más complicado requiere una política más complicada. Necesitamos una política que detecte el comportamiento del entorno subyacente. Hay tres situaciones que la política debe manejar:
- El agente no ha detectado saber todavía qué versión del entorno se está ejecutando.
- El agente detectó que se está ejecutando la versión original del entorno.
- El agente detectó que se está ejecutando la versión invertida del entorno.
Definimos una tf_variable llamado _situation para almacenar esta información codificada como valores en [0, 2] , a continuación, hacer que la política se comportan en consecuencia.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
El agente
Ahora es el momento de definir el agente que detecta la señal del entorno y establece la política de forma adecuada.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
En el código anterior, el agente define la política, y la variable situation es compartida por el agente y la política.
Además, el parámetro de experience de la _train función es una trayectoria:
Trayectorias
En la carretera TF-agentes, trajectories se nombran tuplas que contienen muestras de los pasos anteriores tomadas. Luego, el agente utiliza estas muestras para entrenar y actualizar la política. En RL, las trayectorias deben contener información sobre el estado actual, el siguiente estado y si el episodio actual ha terminado. Dado que en el mundo Bandit no necesitamos estas cosas, configuramos una función auxiliar para crear una trayectoria:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Capacitación de un agente
Ahora todas las piezas están listas para entrenar a nuestro agente bandido.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
A partir del resultado, se puede ver que después del segundo paso (a menos que la observación fuera 0 en el primer paso), la política elige la acción de la manera correcta y, por lo tanto, la recompensa recolectada siempre es no negativa.
Un verdadero ejemplo de bandido contextual
En el resto de este tutorial, usamos los pre-implementado ambientes y agentes de la biblioteca TF-Agentes Bandits.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Entorno estocástico estacionario con funciones de pago lineal
El entorno utilizado en este ejemplo es la StationaryStochasticPyEnvironment . Este entorno toma como parámetro una función (generalmente ruidosa) para dar observaciones (contexto), y para cada brazo toma una función (también ruidosa) que calcula la recompensa basada en la observación dada. En nuestro ejemplo, tomamos muestras del contexto de manera uniforme a partir de un cubo de dimensión d, y las funciones de recompensa son funciones lineales del contexto, más algo de ruido gaussiano.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
El agente de LinUCB
El agente de abajo implementa el LinUCB algoritmo.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Métrica de arrepentimiento
Métrica más importante bandidos es pesar, calculado como la diferencia entre el premio recogido por el agente y la recompensa esperada de una política de Oracle que tiene acceso a las funciones de recompensa del medio ambiente. El RegretMetric por lo tanto necesita una función baseline_reward_fn que calcula la mejor recompensa esperada alcanzable dada una observación. Para nuestro ejemplo, necesitamos tomar el máximo de los equivalentes sin ruido de las funciones de recompensa que ya definimos para el entorno.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Capacitación
Ahora reunimos todos los componentes que presentamos anteriormente: el medio ambiente, la política y el agente. Llevamos a cabo la política de los datos del entorno y de formación de salida con la ayuda de un conductor, y capacitar a los agentes sobre los datos.
Tenga en cuenta que hay dos parámetros que juntos especifican el número de pasos realizados. num_iterations especifica cuántas veces se corre el bucle de entrenador, mientras que el conductor se llevará a steps_per_loop pasos por iteración. La razón principal para mantener ambos parámetros es que algunas operaciones se realizan por iteración, mientras que otras las realiza el controlador en cada paso. Por ejemplo, el agente de train función sólo se llama una vez por iteración. La compensación aquí es que si entrenamos con más frecuencia, entonces nuestra política es "más fresca", por otro lado, la capacitación en lotes más grandes podría ser más eficiente en el tiempo.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
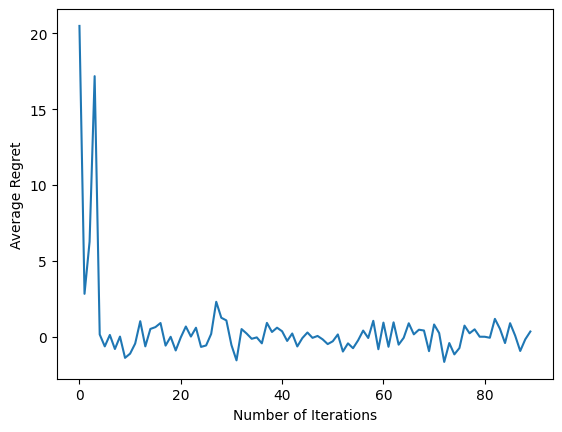
Después de ejecutar el último fragmento de código, la trama resultante (con suerte) muestra que el arrepentimiento promedio está disminuyendo a medida que se entrena al agente y la política mejora para determinar cuál es la acción correcta, dada la observación.
¿Que sigue?
Para ver ejemplos más trabajo, por favor ver el bandidos / agentes / Ejemplos directorio que tiene ejemplos listos para funcionar para diferentes agentes y entornos.
La biblioteca TF-Agents también es capaz de manejar bandidos de armas múltiples con funciones por brazo. A tal efecto, nos referimos al lector al bandido por el brazo tutorial .