
কপিরাইট 2020 টিএফ-এজেন্ট লেখক।
এবার শুরু করা যাক
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
সেটআপ
আপনি যদি নিম্নলিখিত নির্ভরতাগুলি ইনস্টল না করে থাকেন তবে চালান:
pip install tf-agents
আমদানি
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
ভূমিকা
মাল্টি-আর্মড ব্যান্ডিট সমস্যা (এমএবি) হল রিইনফোর্সমেন্ট লার্নিং এর একটি বিশেষ কেস: একজন এজেন্ট পরিবেশের কিছু অবস্থা পর্যবেক্ষণ করার পর কিছু পদক্ষেপ গ্রহণ করে পরিবেশে পুরস্কার সংগ্রহ করে। সাধারণ RL এবং MAB-এর মধ্যে প্রধান পার্থক্য হল যে MAB-তে, আমরা অনুমান করি যে এজেন্ট দ্বারা নেওয়া পদক্ষেপ পরিবেশের পরবর্তী অবস্থাকে প্রভাবিত করে না। অতএব, এজেন্টরা রাষ্ট্রীয় রূপান্তর, অতীত কর্মের জন্য ক্রেডিট পুরষ্কার বা পুরস্কার-সমৃদ্ধ রাজ্যে যাওয়ার জন্য "আগামী পরিকল্পনা" করে না।
অন্যান্য আরএল ডোমেইনের হিসেবে, একটি মিউনিসিপ্যাল এসোসিয়েশনের এজেন্ট লক্ষ্য একটি নীতি খুঁজে পেতে যে সংগ্রহ যতটা সম্ভব পুরস্কার হিসাবে। যাইহোক, সর্বদা সর্বোচ্চ পুরষ্কারের প্রতিশ্রুতি দেয় এমন ক্রিয়াকে কাজে লাগানোর চেষ্টা করা একটি ভুল হবে, কারণ তারপরে আমরা যথেষ্ট অন্বেষণ না করলে আমরা আরও ভাল ক্রিয়াগুলি মিস করার একটি সুযোগ রয়েছে। এই প্রধান সমস্যা (মিউনিসিপ্যাল এসোসিয়েশনের) সমাধান করা প্রায়শই অন্বেষণ-শোষণ উভয়সঙ্কট বলা হয়।
ডাকাত পরিবেশের, নীতি, এবং মিউনিসিপ্যাল এসোসিয়েশনের জন্য এজেন্ট সাবডিরেক্টরি খুঁজে পাওয়া যেতে পারে tf_agents / দস্যুরা ।
পরিবেশ
মেমরি-এজেন্ট, পরিবেশ বর্গ, বর্তমান অবস্থা সম্পর্কে তথ্য দেবার ভূমিকা তোলে (এই পর্যবেক্ষণ বা প্রসঙ্গ বলা হয়), ইনপুট হিসাবে একটি কর্ম গ্রহণ একটি রাষ্ট্র রূপান্তর করণ, এবং একটি পুরস্কার outputting। এই ক্লাসটি একটি পর্ব শেষ হলে পুনরায় সেট করার যত্ন নেয়, যাতে একটি নতুন পর্ব শুরু হতে পারে। এই কল করে নিরূপিত হয় reset ফাংশন একটি রাষ্ট্র হিসেবে পর্বের "সর্বশেষ" লেবেল করা হয়েছে।
অধিক বিবরণের জন্য, দেখুন মেমরি-এজেন্ট পরিবেশের টিউটোরিয়াল ।
উপরে উল্লিখিত হিসাবে, MAB সাধারণ RL থেকে আলাদা যে ক্রিয়াগুলি পরবর্তী পর্যবেক্ষণকে প্রভাবিত করে না। আরেকটি পার্থক্য হল দস্যুদের মধ্যে, কোন "পর্ব" নেই: প্রতিবার পদক্ষেপ একটি নতুন পর্যবেক্ষণের সাথে শুরু হয়, আগের সময়ের পদক্ষেপগুলি থেকে স্বাধীনভাবে।
নিশ্চিত পর্যবেক্ষণ স্বাধীন ও বিমূর্ত দূরে আরএল পর্বের ধারণা করছে করতে, আমরা এর উপশ্রেণী পরিচয় করিয়ে PyEnvironment এবং TFEnvironment : BanditPyEnvironment এবং BanditTFEnvironment । এই ক্লাস দুটি ব্যক্তিগত সদস্য ফাংশন প্রকাশ করে যা ব্যবহারকারীর দ্বারা প্রয়োগ করা বাকি থাকে:
@abc.abstractmethod
def _observe(self):
এবং
@abc.abstractmethod
def _apply_action(self, action):
_observe ফাংশন একটি পর্যবেক্ষণ ফেরৎ। তারপর, নীতি এই পর্যবেক্ষণের উপর ভিত্তি করে একটি পদক্ষেপ বেছে নেয়। _apply_action একটি ইনপুট হিসাবে এই ক্রিয়াটি পায়, এবং সংশ্লিষ্ট পুরস্কার প্রদান করে। এই ব্যক্তিগত সদস্য ফাংশন ফাংশন দ্বারা বলা হয় reset এবং step যথাক্রমে।
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
অন্তর্বর্তী বিমূর্ত বর্গ কার্যকরী উপরে PyEnvironment এর _reset এবং _step কার্যকারিতা ও অনাবৃত বিমূর্ত ফাংশন _observe এবং _apply_action উপশ্রেণী দ্বারা বাস্তবায়িত হবে।
একটি সহজ উদাহরণ পরিবেশ ক্লাস
নিম্নলিখিত শ্রেণীটি একটি খুব সাধারণ পরিবেশ দেয় যার জন্য পর্যবেক্ষণ হল -2 এবং 2 এর মধ্যে একটি এলোমেলো পূর্ণসংখ্যা, 3টি সম্ভাব্য ক্রিয়া (0, 1, 2) আছে এবং পুরস্কার হল কর্ম এবং পর্যবেক্ষণের গুণফল।
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
এখন আমরা পর্যবেক্ষণ পেতে এবং আমাদের কর্মের জন্য পুরস্কার পেতে এই পরিবেশ ব্যবহার করতে পারেন.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
TF পরিবেশ
এক subclassing দ্বারা একটি ডাকাত পরিবেশ বর্ণনা করতে পারেন BanditTFEnvironment একভাবে আরএল পরিবেশের সাথে, বা, এক বর্ণনা করতে পারেন BanditPyEnvironment এবং এটি মোড়ানো TFPyEnvironment । সরলতার জন্য, আমরা এই টিউটোরিয়ালে পরবর্তী বিকল্পটি নিয়ে যাই।
tf_environment = tf_py_environment.TFPyEnvironment(environment)
নীতিমালা
একটি ডাকাত সমস্যা একটি নীতিটি আরএল সমস্যা হিসেবে একই ভাবে কাজ করে: এটা একটি কর্ম (অথবা কর্মের একটি ডিস্ট্রিবিউশন) প্রদান করে ইনপুট হিসাবে একটি পর্যবেক্ষণ দেওয়া।
অধিক বিবরণের জন্য, দেখুন মেমরি-এজেন্ট নীতি টিউটোরিয়াল ।
এক একটি তৈরি করতে পারেন: পরিবেশের হিসাবে, সেখানে একটি নীতি গঠন করা দুটি উপায় আছে PyPolicy এবং এটি মোড়ানো TFPyPolicy , অথবা সরাসরি একটি তৈরি TFPolicy । এখানে আমরা সরাসরি পদ্ধতিতে যেতে নির্বাচন করি।
যেহেতু এই উদাহরণটি বেশ সহজ, আমরা ম্যানুয়ালি সর্বোত্তম নীতি নির্ধারণ করতে পারি। ক্রিয়াটি শুধুমাত্র পর্যবেক্ষণের চিহ্নের উপর নির্ভর করে, 0 কখন নেতিবাচক এবং 2 কখন ইতিবাচক।
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
এখন আমরা পরিবেশ থেকে একটি পর্যবেক্ষণের জন্য অনুরোধ করতে পারি, একটি কর্ম চয়ন করার জন্য নীতিতে কল করতে পারি, তারপর পরিবেশ পুরস্কারটি আউটপুট করবে:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
দস্যু পরিবেশগুলি যেভাবে বাস্তবায়িত হয় তা নিশ্চিত করে যে প্রতিবার আমরা একটি পদক্ষেপ নিই, আমরা যে পদক্ষেপটি নিয়েছি তার জন্য আমরা কেবল পুরস্কারই পাব না, পরবর্তী পর্যবেক্ষণও পাব।
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
এজেন্ট
এখন যেহেতু আমাদের দস্যু পরিবেশ এবং দস্যু নীতি রয়েছে, এখন দস্যু এজেন্টদের সংজ্ঞায়িত করার সময় এসেছে, যারা প্রশিক্ষণের নমুনার ভিত্তিতে নীতি পরিবর্তন করার যত্ন নেয়।
ডাকাত এজেন্ট জন্য API আরএল এজেন্ট চেয়ে আলাদা করে না: এজেন্ট মাত্র বাস্তবায়ন প্রয়োজন _initialize এবং _train পদ্ধতি, এবং সংজ্ঞায়িত একটি policy এবং একটি collect_policy ।
আরও জটিল পরিবেশ
আমরা আমাদের দস্যু এজেন্ট লিখার আগে, আমাদের এমন একটি পরিবেশ থাকতে হবে যা বের করা একটু কঠিন। জিনিস ঠিক একটি সামান্য বিট মসলা আপ, পরবর্তী পরিবেশ পারেন সবসময় দেব reward = observation * action বা reward = -observation * action । পরিবেশ শুরু হলে এ বিষয়ে সিদ্ধান্ত নেওয়া হবে।
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
একটি আরো জটিল নীতি
একটি আরও জটিল পরিবেশ একটি আরও জটিল নীতির জন্য কল করে। আমাদের এমন একটি নীতি দরকার যা অন্তর্নিহিত পরিবেশের আচরণ সনাক্ত করে। নীতিটি পরিচালনা করতে হবে এমন তিনটি পরিস্থিতি রয়েছে:
- পরিবেশের কোন সংস্করণ চলছে তা এজেন্ট এখনও সনাক্ত করতে পারেনি।
- এজেন্ট সনাক্ত করেছে যে পরিবেশের আসল সংস্করণ চলছে।
- এজেন্ট সনাক্ত করেছে যে পরিবেশের ফ্লিপড সংস্করণ চলছে৷
আমরা একটি সংজ্ঞায়িত tf_variable নামে _situation এই তথ্য মান হিসাবে এনকোডেড সঞ্চয় করতে [0, 2] , তারপর নীতি আচরণ তদনুসারে ভুলবেন না।
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
প্রতিনিধি
এখন সময় এসেছে সেই এজেন্টকে সংজ্ঞায়িত করার যেটি পরিবেশের চিহ্ন সনাক্ত করে এবং যথাযথভাবে নীতি নির্ধারণ করে।
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
উপরের কোড ইন, প্রতিনিধি নীতি নির্ধারণ, এবং পরিবর্তনশীল situation এজেন্ট এবং নীতি দ্বারা ভাগ করা হয়।
এছাড়াও, পরামিতি experience এর _train ফাংশন একটি গ্রহনক্ষত্রের নির্দিষ্ট আবক্র পথ হল:
ট্রাজেক্টোরিজ
মেমরি-এজেন্ট, trajectories tuples যে আগের পদক্ষেপ গ্রহণ থেকে নমুনা ধারণ নামকরণ করা হয়। এই নমুনাগুলি এজেন্ট দ্বারা প্রশিক্ষণ এবং নীতি আপডেট করার জন্য ব্যবহার করা হয়। RL-এ, ট্র্যাজেক্টোরিতে বর্তমান অবস্থা, পরবর্তী অবস্থা এবং বর্তমান পর্ব শেষ হয়েছে কিনা সে সম্পর্কে তথ্য থাকতে হবে। যেহেতু দস্যু জগতে আমাদের এই জিনিসগুলির প্রয়োজন নেই, আমরা একটি ট্র্যাজেক্টোরি তৈরি করতে একটি সহায়ক ফাংশন সেট আপ করি:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
একটি এজেন্ট প্রশিক্ষণ
এখন সব টুকরা আমাদের দস্যু এজেন্ট প্রশিক্ষণের জন্য প্রস্তুত.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
আউটপুট থেকে কেউ দেখতে পারে যে দ্বিতীয় ধাপের পরে (যদি না পর্যবেক্ষণটি প্রথম ধাপে 0 ছিল), নীতিটি সঠিক উপায়ে কাজটি বেছে নেয় এবং এইভাবে সংগৃহীত পুরষ্কার সবসময় অ-নেতিবাচক হয়।
একটি বাস্তব প্রাসঙ্গিক দস্যু উদাহরণ
এই টিউটোরিয়াল বাকি, আমরা প্রাক বাস্তবায়িত ব্যবহার পরিবেশের এবং এজেন্ট মেমরি-এজেন্ট ডাকাত লাইব্রেরির।
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
রৈখিক পেওফ ফাংশন সহ স্থির স্টোকাস্টিক পরিবেশ
এই উদাহরণে ব্যবহৃত পরিবেশ StationaryStochasticPyEnvironment । এই পরিবেশটি পর্যবেক্ষণ (প্রসঙ্গ) দেওয়ার জন্য একটি (সাধারণত কোলাহলপূর্ণ) ফাংশন প্যারামিটার হিসাবে নেয় এবং প্রতিটি বাহুতে একটি (এছাড়াও কোলাহলপূর্ণ) ফাংশন লাগে যা প্রদত্ত পর্যবেক্ষণের উপর ভিত্তি করে পুরষ্কার গণনা করে। আমাদের উদাহরণে, আমরা একটি ডি-ডাইমেনশনাল কিউব থেকে প্রসঙ্গটিকে অভিন্নভাবে নমুনা করি, এবং পুরস্কার ফাংশনগুলি হল প্রেক্ষাপটের রৈখিক ফাংশন এবং কিছু গাউসিয়ান শব্দ।
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
LinUCB এজেন্ট
কার্যকরী নিচে এজেন্ট LinUCB অ্যালগরিদম।
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
আক্ষেপ মেট্রিক
দস্যুরা 'সবচেয়ে গুরুত্বপূর্ণ মেট্রিক খেদ, প্রতিনিধি দ্বারা সংগৃহীত পুরস্কার ও পরিবেশ পুরস্কার ফাংশন অ্যাক্সেস আছে যে একটি ওরাকল নীতির প্রত্যাশিত প্রতিদান মধ্যে পার্থক্য হিসাবে গণনা করা হয়। RegretMetric এইভাবে একটি baseline_reward_fn ফাংশন যা একটি পর্যবেক্ষণ দেওয়া শ্রেষ্ঠ সাধনযোগ্য প্রত্যাশিত প্রতিদান হিসাব প্রয়োজন। আমাদের উদাহরণের জন্য, পরিবেশের জন্য আমরা ইতিমধ্যে সংজ্ঞায়িত পুরষ্কার ফাংশনগুলির নো-নোইজ সমতুল্য সর্বাধিক গ্রহণ করতে হবে।
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
প্রশিক্ষণ
এখন আমরা উপরে প্রবর্তিত সমস্ত উপাদান একসাথে রাখি: পরিবেশ, নীতি এবং এজেন্ট। আমরা একটি চালক সাহায্যে পরিবেশ এবং আউটপুট প্রশিক্ষণ ডেটার উপর নীতি চালানোর জন্য, এবং ডেটার উপর এজেন্ট প্রশিক্ষণ।
নোট করুন যে দুটি পরামিতি রয়েছে যা একসাথে নেওয়া পদক্ষেপের সংখ্যা নির্দিষ্ট করে। num_iterations নির্দিষ্ট করে কতবার আমরা প্রশিক্ষকের লুপ চালানো, যখন চালক নিতে হবে steps_per_loop পুনরাবৃত্তির প্রতি ধাপ। এই উভয় পরামিতি রাখার পিছনে প্রধান কারণ হল কিছু অপারেশন প্রতি পুনরাবৃত্তি করা হয়, যখন কিছু প্রতি ধাপে ড্রাইভার দ্বারা করা হয়। উদাহরণস্বরূপ, এজেন্টের train ফাংশন শুধুমাত্র পুনরাবৃত্তির প্রতি একবার বলা হয়। এখানে ট্রেড-অফ হল যে আমরা যদি প্রায়শই ট্রেনিং করি তবে আমাদের নীতি "নতুন" হয়, অন্যদিকে, বড় ব্যাচে প্রশিক্ষণ আরও বেশি সময় দক্ষ হতে পারে।
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
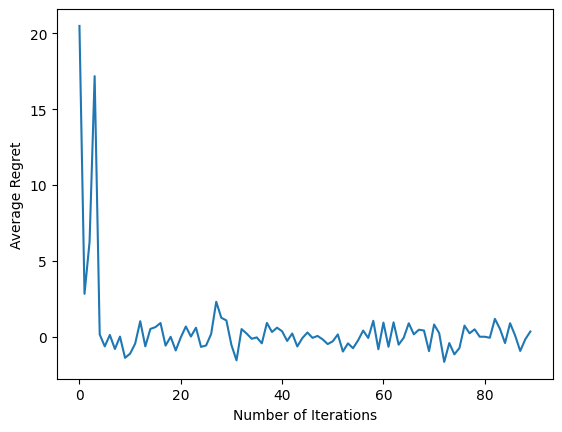
শেষ কোড স্নিপেটটি চালানোর পরে, ফলাফলের প্লট (আশা করা যায়) দেখায় যে এজেন্ট প্রশিক্ষিত হওয়ায় গড় অনুশোচনা কমে যাচ্ছে এবং পর্যবেক্ষণের ভিত্তিতে সঠিক পদক্ষেপ কী তা খুঁজে বের করার ক্ষেত্রে নীতিটি আরও ভাল হয়ে যায়।
এরপর কি?
আরো কাজ উদাহরণ দেখার জন্য, দয়া করে দেখুন দস্যুরা / এজেন্ট / উদাহরণ ডিরেক্টরি আছে বিভিন্ন এজেন্ট এবং পরিবেশের জন্য প্রস্তুত টু চালানোর উদাহরণ।
TF-এজেন্টস লাইব্রেরি প্রতি-বাহু বৈশিষ্ট্য সহ মাল্টি-আর্মড দস্যুদের পরিচালনা করতেও সক্ষম। তা করার জন্য, আমরা প্রতি-হাতি ডাকাত পাঠক পড়ুন টিউটোরিয়াল ।