
ลิขสิทธิ์ 2021 The TF-Agents Authors.
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทนำ
ตัวอย่างนี้แสดงให้เห็นว่าการฝึกอบรม หมวดหมู่ DQN (C51) ตัวแทนในสภาพแวดล้อมการใช้ห้องสมุด Cartpole ตัวแทนลุย
ให้แน่ใจว่าคุณจะดูผ่านที่ DQN กวดวิชา เป็นสิ่งที่จำเป็น บทช่วยสอนนี้จะถือว่าคุ้นเคยกับบทช่วยสอน DQN; โดยจะเน้นที่ความแตกต่างระหว่าง DQN และ C51 เป็นหลัก
ติดตั้ง
หากคุณยังไม่ได้ติดตั้ง tf-agents ให้รัน:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agentspip install pyglet
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import PIL.Image
import pyvirtualdisplay
import tensorflow as tf
from tf_agents.agents.categorical_dqn import categorical_dqn_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import categorical_q_network
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
ไฮเปอร์พารามิเตอร์
env_name = "CartPole-v1" # @param {type:"string"}
num_iterations = 15000 # @param {type:"integer"}
initial_collect_steps = 1000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 100000 # @param {type:"integer"}
fc_layer_params = (100,)
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
gamma = 0.99
log_interval = 200 # @param {type:"integer"}
num_atoms = 51 # @param {type:"integer"}
min_q_value = -20 # @param {type:"integer"}
max_q_value = 20 # @param {type:"integer"}
n_step_update = 2 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
สิ่งแวดล้อม
โหลดสภาพแวดล้อมเหมือนก่อน โดยหนึ่งรายการสำหรับการฝึกอบรมและอีกรายการสำหรับการประเมิน ที่นี่เราใช้ CartPole-v1 (เทียบกับ CartPole-v0 ในบทช่วยสอน DQN) ซึ่งมีรางวัลสูงสุดมากกว่า 500 มากกว่า 200
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
ตัวแทน
C51 เป็นอัลกอริธึม Q-learning ตาม DQN เช่นเดียวกับ DQN สามารถใช้ได้กับทุกสภาพแวดล้อมที่มีพื้นที่ดำเนินการแยกกัน
ความแตกต่างที่สำคัญระหว่าง C51 และ DQN ก็คือ แทนที่จะเพียงแค่ทำนายค่า Q สำหรับแต่ละคู่สถานะการกระทำ C51 จะทำนายแบบจำลองฮิสโตแกรมสำหรับการแจกแจงความน่าจะเป็นของค่า Q:
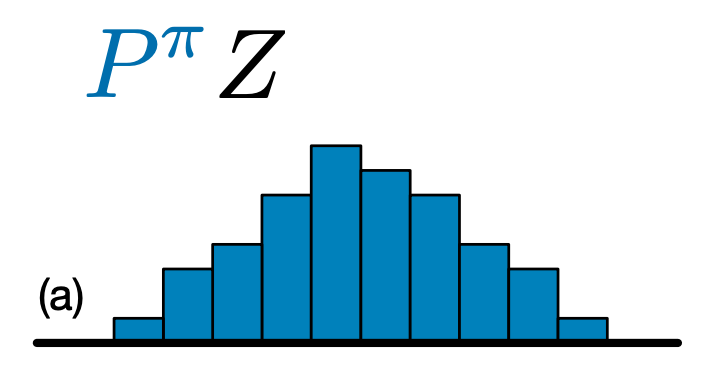
ด้วยการเรียนรู้การกระจายมากกว่าแค่ค่าที่คาดหวัง อัลกอริธึมสามารถคงความเสถียรมากขึ้นในระหว่างการฝึกอบรม ซึ่งนำไปสู่การปรับปรุงประสิทธิภาพขั้นสุดท้าย โดยเฉพาะอย่างยิ่งในสถานการณ์ที่มีการกระจายค่าแบบไบโมดัลหรือหลายรูปแบบ ซึ่งค่าเฉลี่ยเดียวไม่ได้ให้ภาพที่ถูกต้อง
เพื่อฝึกการแจกแจงความน่าจะเป็นมากกว่าค่า C51 ต้องทำการคำนวณการแจกแจงที่ซับซ้อนบางอย่างเพื่อคำนวณฟังก์ชันการสูญเสีย แต่ไม่ต้องกังวล ทั้งหมดนี้ดูแลคุณแล้วใน TF-Agents!
ในการสร้างตัวแทน C51 อันดับแรกเราต้องสร้าง CategoricalQNetwork API ที่ของ CategoricalQNetwork เป็นเช่นเดียวกับที่ของ QNetwork ยกเว้นว่ามีอาร์กิวเมนต์เพิ่มเติม num_atoms นี่แสดงถึงจำนวนจุดสนับสนุนในการประมาณการการกระจายความน่าจะเป็นของเรา (ภาพด้านบนประกอบด้วยจุดสนับสนุน 10 จุด แต่ละจุดแสดงด้วยแถบสีน้ำเงินแนวตั้ง) อย่างที่คุณทราบได้จากชื่อ จำนวนอะตอมเริ่มต้นคือ 51
categorical_q_net = categorical_q_network.CategoricalQNetwork(
train_env.observation_spec(),
train_env.action_spec(),
num_atoms=num_atoms,
fc_layer_params=fc_layer_params)
นอกจากนี้เรายังจำเป็นต้องมีการ optimizer ในการฝึกอบรมเครือข่ายที่เราเพิ่งสร้างและ train_step_counter ตัวแปรในการติดตามของจำนวนครั้งที่เครือข่ายได้รับการปรับปรุง
โปรดทราบว่าหนึ่งความแตกต่างอย่างมีนัยสำคัญอื่น ๆ จากวานิลลา DqnAgent คือตอนนี้เราจำเป็นต้องระบุ min_q_value และ max_q_value เป็นข้อโต้แย้ง สิ่งเหล่านี้ระบุค่าสูงสุดของการสนับสนุน (กล่าวอีกนัยหนึ่งคือที่สุดของ 51 อะตอมที่ด้านใดด้านหนึ่ง) ตรวจสอบให้แน่ใจว่าได้เลือกสิ่งเหล่านี้อย่างเหมาะสมสำหรับสภาพแวดล้อมเฉพาะของคุณ ในที่นี้เราใช้ -20 และ 20
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = categorical_dqn_agent.CategoricalDqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
categorical_q_network=categorical_q_net,
optimizer=optimizer,
min_q_value=min_q_value,
max_q_value=max_q_value,
n_step_update=n_step_update,
td_errors_loss_fn=common.element_wise_squared_loss,
gamma=gamma,
train_step_counter=train_step_counter)
agent.initialize()
หนึ่งสิ่งสุดท้ายที่จะต้องทราบก็คือว่าเรายังเพิ่มอาร์กิวเมนต์การปรับปรุงการใช้ n ขั้นตอนที่มี \(n\) = 2. ในขั้นตอนเดียว Q-การเรียนรู้ (\(n\) = 1) เราจะคำนวณผิดพลาดระหว่าง Q-ค่า ที่ขั้นตอนเวลาปัจจุบันและขั้นตอนถัดไปโดยใช้การย้อนกลับแบบขั้นตอนเดียว (ตามสมการความเหมาะสมของ Bellman) การส่งคืนแบบขั้นตอนเดียวถูกกำหนดเป็น:
\(G_t = R_{t + 1} + \gamma V(s_{t + 1})\)
ที่เรากำหนด \(V(s) = \max_a{Q(s, a)}\)
การปรับปรุง N-ขั้นตอนที่เกี่ยวข้องกับการขยายตัวฟังก์ชั่นขั้นตอนเดียวผลตอบแทนมาตรฐาน \(n\) ครั้ง:
\(G_t^n = R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + \dots + \gamma^n V(s_{t + n})\)
การปรับปรุง N-ขั้นตอนที่ช่วยให้ตัวแทนในการบูตจากต่อไปในอนาคตและมีความคุ้มค่าทางด้านขวาของ \(n\)การเรียนรู้นี้มักจะนำไปสู่การได้เร็วขึ้น
แม้ว่า C51 n และขั้นตอนการปรับปรุงมักจะรวมกับ replay จัดลำดับความสำคัญในรูปแบบหลักของ ตัวแทนเรนโบว์ เราเห็นไม่มีการปรับปรุงที่วัดได้จากการดำเนินการจัดลำดับความสำคัญการเล่นใหม่ นอกจากนี้ เราพบว่าเมื่อรวมเอเจนต์ C51 ของเราเข้ากับการอัปเดต n-step เพียงอย่างเดียว เอเจนต์ของเราจะทำงานได้ดีพอๆ กับเอเจนต์ Rainbow อื่นๆ ในตัวอย่างสภาพแวดล้อม Atari ที่เราได้ทดสอบ
ตัวชี้วัดและการประเมินผล
เมตริกที่ใช้บ่อยที่สุดในการประเมินนโยบายคือผลตอบแทนเฉลี่ย การคืนคือผลรวมของรางวัลที่ได้รับขณะดำเนินนโยบายในสภาพแวดล้อมสำหรับตอนหนึ่งๆ และโดยปกติแล้วเราจะเฉลี่ยสิ่งนี้ในช่วงสองสามตอน เราสามารถคำนวณผลตอบแทนเฉลี่ยได้ดังนี้
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
compute_avg_return(eval_env, random_policy, num_eval_episodes)
# Please also see the metrics module for standard implementations of different
# metrics.
20.0
การเก็บรวบรวมข้อมูล
เช่นเดียวกับในบทช่วยสอน DQN ให้ตั้งค่าบัฟเฟอร์การเล่นซ้ำและการรวบรวมข้อมูลเริ่มต้นด้วยนโยบายสุ่ม
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_capacity)
def collect_step(environment, policy):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
# Add trajectory to the replay buffer
replay_buffer.add_batch(traj)
for _ in range(initial_collect_steps):
collect_step(train_env, random_policy)
# This loop is so common in RL, that we provide standard implementations of
# these. For more details see the drivers module.
# Dataset generates trajectories with shape [BxTx...] where
# T = n_step_update + 1.
dataset = replay_buffer.as_dataset(
num_parallel_calls=3, sample_batch_size=batch_size,
num_steps=n_step_update + 1).prefetch(3)
iterator = iter(dataset)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/experimental/ops/counter.py:66: scan (from tensorflow.python.data.experimental.ops.scan_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.scan(...) instead WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/autograph/impl/api.py:382: ReplayBuffer.get_next (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=False) instead.
อบรมตัวแทน
วงการฝึกอบรมเกี่ยวข้องกับทั้งการรวบรวมข้อมูลจากสภาพแวดล้อมและการเพิ่มประสิทธิภาพเครือข่ายของตัวแทน ในระหว่างนี้ เราจะประเมินนโยบายของตัวแทนเป็นครั้งคราวเพื่อดูว่าเราเป็นอย่างไร
การดำเนินการต่อไปนี้จะใช้เวลา ~7 นาที
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few steps using collect_policy and save to the replay buffer.
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience)
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1:.2f}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/util/dispatch.py:206: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) step = 200: loss = 3.199000597000122 step = 400: loss = 2.083357810974121 step = 600: loss = 1.9901162385940552 step = 800: loss = 1.9055049419403076 step = 1000: loss = 1.7382612228393555 step = 1000: Average Return = 34.40 step = 1200: loss = 1.3624987602233887 step = 1400: loss = 1.548039197921753 step = 1600: loss = 1.4193217754364014 step = 1800: loss = 1.3339967727661133 step = 2000: loss = 1.1471226215362549 step = 2000: Average Return = 91.10 step = 2200: loss = 1.360352873802185 step = 2400: loss = 1.4253160953521729 step = 2600: loss = 0.9550995826721191 step = 2800: loss = 0.9822611808776855 step = 3000: loss = 1.0512573719024658 step = 3000: Average Return = 102.60 step = 3200: loss = 1.131516456604004 step = 3400: loss = 1.0834283828735352 step = 3600: loss = 0.8771724104881287 step = 3800: loss = 0.7854692935943604 step = 4000: loss = 0.7451740503311157 step = 4000: Average Return = 179.10 step = 4200: loss = 0.6963338851928711 step = 4400: loss = 0.8579068183898926 step = 4600: loss = 0.735978364944458 step = 4800: loss = 0.5723521709442139 step = 5000: loss = 0.6422518491744995 step = 5000: Average Return = 138.00 step = 5200: loss = 0.5242955684661865 step = 5400: loss = 0.869032621383667 step = 5600: loss = 0.7798122763633728 step = 5800: loss = 0.745892345905304 step = 6000: loss = 0.7540864944458008 step = 6000: Average Return = 155.80 step = 6200: loss = 0.6851651668548584 step = 6400: loss = 0.7417727112770081 step = 6600: loss = 0.7385923862457275 step = 6800: loss = 0.8823254108428955 step = 7000: loss = 0.6216408014297485 step = 7000: Average Return = 146.90 step = 7200: loss = 0.3905255198478699 step = 7400: loss = 0.5030156373977661 step = 7600: loss = 0.6326021552085876 step = 7800: loss = 0.6071780920028687 step = 8000: loss = 0.49069637060165405 step = 8000: Average Return = 332.70 step = 8200: loss = 0.7194125056266785 step = 8400: loss = 0.7707428932189941 step = 8600: loss = 0.42258384823799133 step = 8800: loss = 0.5215793251991272 step = 9000: loss = 0.6949542164802551 step = 9000: Average Return = 174.10 step = 9200: loss = 0.7312793731689453 step = 9400: loss = 0.5663323402404785 step = 9600: loss = 0.8518731594085693 step = 9800: loss = 0.5256152153015137 step = 10000: loss = 0.578148603439331 step = 10000: Average Return = 147.40 step = 10200: loss = 0.46965712308883667 step = 10400: loss = 0.5685954093933105 step = 10600: loss = 0.5819060802459717 step = 10800: loss = 0.792033851146698 step = 11000: loss = 0.5804982781410217 step = 11000: Average Return = 186.80 step = 11200: loss = 0.4973406195640564 step = 11400: loss = 0.33229681849479675 step = 11600: loss = 0.5267124176025391 step = 11800: loss = 0.585414469242096 step = 12000: loss = 0.6697092652320862 step = 12000: Average Return = 135.30 step = 12200: loss = 0.30732017755508423 step = 12400: loss = 0.490392804145813 step = 12600: loss = 0.28014713525772095 step = 12800: loss = 0.456543892621994 step = 13000: loss = 0.48237597942352295 step = 13000: Average Return = 182.70 step = 13200: loss = 0.5447070598602295 step = 13400: loss = 0.4602382481098175 step = 13600: loss = 0.5659506320953369 step = 13800: loss = 0.47906267642974854 step = 14000: loss = 0.4060840904712677 step = 14000: Average Return = 153.00 step = 14200: loss = 0.6457054018974304 step = 14400: loss = 0.4795544147491455 step = 14600: loss = 0.16895757615566254 step = 14800: loss = 0.5005109906196594 step = 15000: loss = 0.5339224338531494 step = 15000: Average Return = 165.10
การสร้างภาพ
พล็อต
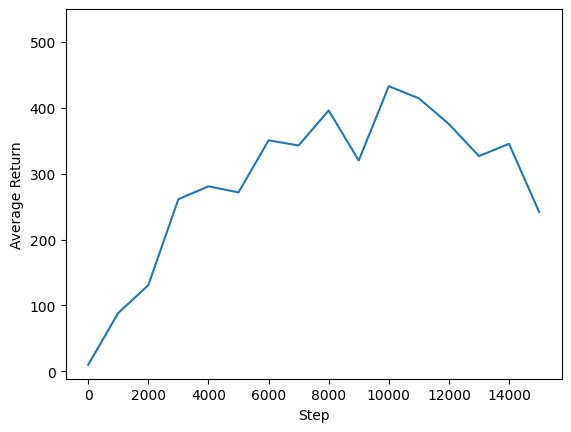
เราสามารถพล็อตผลตอบแทนเทียบกับขั้นตอนระดับโลกเพื่อดูประสิทธิภาพของตัวแทนของเรา ใน Cartpole-v1 สภาพแวดล้อมให้รางวัลของ +1 สำหรับขั้นตอนเวลาทุกการเข้าพักเสาขึ้นและเนื่องจากจำนวนสูงสุดของขั้นตอนคือ 500, ผลตอบแทนที่เป็นไปได้สูงสุดยังเป็น 500
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=550)
(19.485000991821288, 550.0)
วิดีโอ
เป็นประโยชน์ในการแสดงภาพประสิทธิภาพของเอเจนต์ด้วยการแสดงสภาพแวดล้อมในแต่ละขั้นตอน ก่อนที่เราจะทำอย่างนั้น ให้เราสร้างฟังก์ชันเพื่อฝังวิดีโอใน colab นี้ก่อน
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
โค้ดต่อไปนี้แสดงภาพนโยบายของเอเจนต์สำหรับบางตอน:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5646eec183c0] Warning: data is not aligned! This can lead to a speed loss
C51 มีแนวโน้มที่จะทำได้ดีกว่า DQN เล็กน้อยใน CartPole-v1 แต่ความแตกต่างระหว่างตัวแทนทั้งสองจะมีความสำคัญมากขึ้นเรื่อยๆ ในสภาพแวดล้อมที่ซับซ้อนมากขึ้น ตัวอย่างเช่น ในเบนช์มาร์ก Atari 2600 แบบเต็ม C51 แสดงให้เห็นถึงการปรับปรุงคะแนนเฉลี่ย 126% เหนือ DQN หลังจากการทำให้เป็นมาตรฐานโดยเทียบกับเอเจนต์แบบสุ่ม สามารถรับการปรับปรุงเพิ่มเติมได้โดยการรวมการอัปเดต n-step
สำหรับการดำน้ำลึกลงไปในขั้นตอนวิธี C51 ดู กระจายมุมมองในการเสริมสร้างการเรียนรู้ (2017)