
Copyright 2021 Gli autori degli agenti TF.
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
introduzione
Questo esempio mostra come addestrare un categoriale DQN (C51) agente sull'ambiente Cartpole utilizzando la libreria TF-Agenti.
Assicurati di prendere uno sguardo attraverso il tutorial di DQN come prerequisito. Questo tutorial presuppone la familiarità con il tutorial DQN; si concentrerà principalmente sulle differenze tra DQN e C51.
Impostare
Se non hai ancora installato tf-agent, esegui:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agentspip install pyglet
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import PIL.Image
import pyvirtualdisplay
import tensorflow as tf
from tf_agents.agents.categorical_dqn import categorical_dqn_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import categorical_q_network
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Iperparametri
env_name = "CartPole-v1" # @param {type:"string"}
num_iterations = 15000 # @param {type:"integer"}
initial_collect_steps = 1000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 100000 # @param {type:"integer"}
fc_layer_params = (100,)
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
gamma = 0.99
log_interval = 200 # @param {type:"integer"}
num_atoms = 51 # @param {type:"integer"}
min_q_value = -20 # @param {type:"integer"}
max_q_value = 20 # @param {type:"integer"}
n_step_update = 2 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
Ambiente
Carica l'ambiente come prima, con uno per la formazione e uno per la valutazione. Qui usiamo CartPole-v1 (contro CartPole-v0 nel tutorial DQN), che ha una ricompensa massima maggiore di 500 anziché 200.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agente
C51 è un algoritmo di Q-learning basato su DQN. Come DQN, può essere utilizzato in qualsiasi ambiente con uno spazio di azione discreto.
La principale differenza tra C51 e DQN è che invece di prevedere semplicemente il valore Q per ciascuna coppia stato-azione, C51 prevede un modello di istogramma per la distribuzione di probabilità del valore Q:
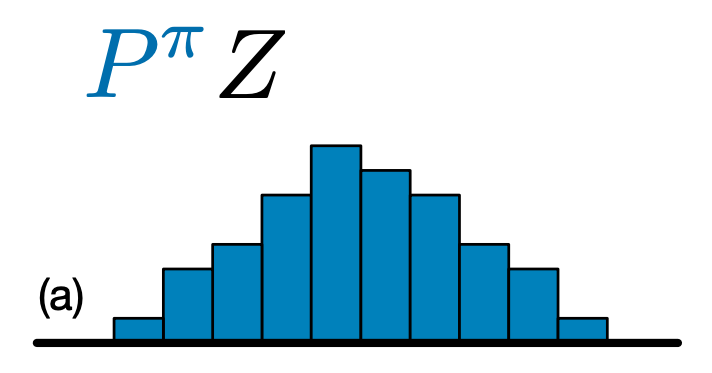
Imparando la distribuzione piuttosto che semplicemente il valore atteso, l'algoritmo è in grado di rimanere più stabile durante l'addestramento, portando a prestazioni finali migliorate. Ciò è particolarmente vero in situazioni con distribuzioni di valore bimodali o addirittura multimodali, in cui una singola media non fornisce un'immagine accurata.
Per allenarsi sulle distribuzioni di probabilità piuttosto che sui valori, C51 deve eseguire alcuni calcoli distributivi complessi per calcolare la sua funzione di perdita. Ma non preoccuparti, tutto questo è pensato per te in TF-Agents!
Per creare un agente di C51, abbiamo prima bisogno di creare un CategoricalQNetwork . L'API del CategoricalQNetwork è la stessa di quella del QNetwork , tranne che c'è un ulteriore argomento num_atoms . Questo rappresenta il numero di punti di supporto nelle nostre stime di distribuzione di probabilità. (L'immagine sopra include 10 punti di supporto, ciascuno rappresentato da una barra blu verticale.) Come puoi vedere dal nome, il numero predefinito di atomi è 51.
categorical_q_net = categorical_q_network.CategoricalQNetwork(
train_env.observation_spec(),
train_env.action_spec(),
num_atoms=num_atoms,
fc_layer_params=fc_layer_params)
Abbiamo anche bisogno di un optimizer per addestrare la rete che abbiamo appena creato, e un train_step_counter variabile per tenere traccia di quante volte è stata aggiornata la rete.
Si noti che un altra differenza significativa dalla vaniglia DqnAgent è che ora abbiamo bisogno di specificare min_q_value e max_q_value come argomenti. Questi specificano i valori più estremi del supporto (in altre parole, il più estremo dei 51 atomi su entrambi i lati). Assicurati di sceglierli in modo appropriato per il tuo ambiente particolare. Qui usiamo -20 e 20.
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = categorical_dqn_agent.CategoricalDqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
categorical_q_network=categorical_q_net,
optimizer=optimizer,
min_q_value=min_q_value,
max_q_value=max_q_value,
n_step_update=n_step_update,
td_errors_loss_fn=common.element_wise_squared_loss,
gamma=gamma,
train_step_counter=train_step_counter)
agent.initialize()
Un'ultima cosa da notare è che abbiamo aggiunto anche un argomento per gli aggiornamenti utilizzare n-step con \(n\) = 2. In single-step Q-learning (\(n\) = 1), si limita a calcolare l'errore tra i fattori Q al passaggio temporale corrente e al passaggio temporale successivo utilizzando il ritorno a passaggio singolo (basato sull'equazione di ottimalità Bellman). Il ritorno a passo singolo è definito come:
\(G_t = R_{t + 1} + \gamma V(s_{t + 1})\)
dove definiamo \(V(s) = \max_a{Q(s, a)}\).
Aggiornamenti N-passo comportano espandendo la funzione passo singolo ritorno standard di \(n\) volte:
\(G_t^n = R_{t + 1} + \gamma R_{t + 2} + \gamma^2 R_{t + 3} + \dots + \gamma^n V(s_{t + n})\)
Aggiornamenti N-step consentire all'agente di bootstrap da ulteriori in futuro, e con il giusto valore di \(n\), questo spesso porta ad imparare più velocemente.
Sebbene gli aggiornamenti C51 e n-passo sono spesso combinati con riproduzione prioritario per formare il nucleo della agente arcobaleno , abbiamo visto nessun miglioramento misurabile di attuare riproduzione priorità. Inoltre, troviamo che quando si combina il nostro agente C51 con gli aggiornamenti n-step da solo, il nostro agente si comporta come gli altri agenti Rainbow sul campione di ambienti Atari che abbiamo testato.
Metriche e valutazione
La metrica più comune utilizzata per valutare una polizza è il rendimento medio. Il rendimento è la somma delle ricompense ottenute durante l'esecuzione di una politica in un ambiente per un episodio e di solito ne facciamo una media su alcuni episodi. Possiamo calcolare la metrica del rendimento medio come segue.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
compute_avg_return(eval_env, random_policy, num_eval_episodes)
# Please also see the metrics module for standard implementations of different
# metrics.
20.0
Raccolta dati
Come nell'esercitazione DQN, imposta il buffer di riproduzione e la raccolta dati iniziale con il criterio casuale.
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_capacity)
def collect_step(environment, policy):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
# Add trajectory to the replay buffer
replay_buffer.add_batch(traj)
for _ in range(initial_collect_steps):
collect_step(train_env, random_policy)
# This loop is so common in RL, that we provide standard implementations of
# these. For more details see the drivers module.
# Dataset generates trajectories with shape [BxTx...] where
# T = n_step_update + 1.
dataset = replay_buffer.as_dataset(
num_parallel_calls=3, sample_batch_size=batch_size,
num_steps=n_step_update + 1).prefetch(3)
iterator = iter(dataset)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/experimental/ops/counter.py:66: scan (from tensorflow.python.data.experimental.ops.scan_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.scan(...) instead WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/autograph/impl/api.py:382: ReplayBuffer.get_next (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=False) instead.
Formazione dell'agente
Il ciclo di addestramento prevede sia la raccolta di dati dall'ambiente sia l'ottimizzazione delle reti dell'agente. Lungo la strada, valuteremo occasionalmente la politica dell'agente per vedere come stiamo andando.
L'esecuzione di quanto segue richiederà circa 7 minuti.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few steps using collect_policy and save to the replay buffer.
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience)
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1:.2f}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/util/dispatch.py:206: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) step = 200: loss = 3.199000597000122 step = 400: loss = 2.083357810974121 step = 600: loss = 1.9901162385940552 step = 800: loss = 1.9055049419403076 step = 1000: loss = 1.7382612228393555 step = 1000: Average Return = 34.40 step = 1200: loss = 1.3624987602233887 step = 1400: loss = 1.548039197921753 step = 1600: loss = 1.4193217754364014 step = 1800: loss = 1.3339967727661133 step = 2000: loss = 1.1471226215362549 step = 2000: Average Return = 91.10 step = 2200: loss = 1.360352873802185 step = 2400: loss = 1.4253160953521729 step = 2600: loss = 0.9550995826721191 step = 2800: loss = 0.9822611808776855 step = 3000: loss = 1.0512573719024658 step = 3000: Average Return = 102.60 step = 3200: loss = 1.131516456604004 step = 3400: loss = 1.0834283828735352 step = 3600: loss = 0.8771724104881287 step = 3800: loss = 0.7854692935943604 step = 4000: loss = 0.7451740503311157 step = 4000: Average Return = 179.10 step = 4200: loss = 0.6963338851928711 step = 4400: loss = 0.8579068183898926 step = 4600: loss = 0.735978364944458 step = 4800: loss = 0.5723521709442139 step = 5000: loss = 0.6422518491744995 step = 5000: Average Return = 138.00 step = 5200: loss = 0.5242955684661865 step = 5400: loss = 0.869032621383667 step = 5600: loss = 0.7798122763633728 step = 5800: loss = 0.745892345905304 step = 6000: loss = 0.7540864944458008 step = 6000: Average Return = 155.80 step = 6200: loss = 0.6851651668548584 step = 6400: loss = 0.7417727112770081 step = 6600: loss = 0.7385923862457275 step = 6800: loss = 0.8823254108428955 step = 7000: loss = 0.6216408014297485 step = 7000: Average Return = 146.90 step = 7200: loss = 0.3905255198478699 step = 7400: loss = 0.5030156373977661 step = 7600: loss = 0.6326021552085876 step = 7800: loss = 0.6071780920028687 step = 8000: loss = 0.49069637060165405 step = 8000: Average Return = 332.70 step = 8200: loss = 0.7194125056266785 step = 8400: loss = 0.7707428932189941 step = 8600: loss = 0.42258384823799133 step = 8800: loss = 0.5215793251991272 step = 9000: loss = 0.6949542164802551 step = 9000: Average Return = 174.10 step = 9200: loss = 0.7312793731689453 step = 9400: loss = 0.5663323402404785 step = 9600: loss = 0.8518731594085693 step = 9800: loss = 0.5256152153015137 step = 10000: loss = 0.578148603439331 step = 10000: Average Return = 147.40 step = 10200: loss = 0.46965712308883667 step = 10400: loss = 0.5685954093933105 step = 10600: loss = 0.5819060802459717 step = 10800: loss = 0.792033851146698 step = 11000: loss = 0.5804982781410217 step = 11000: Average Return = 186.80 step = 11200: loss = 0.4973406195640564 step = 11400: loss = 0.33229681849479675 step = 11600: loss = 0.5267124176025391 step = 11800: loss = 0.585414469242096 step = 12000: loss = 0.6697092652320862 step = 12000: Average Return = 135.30 step = 12200: loss = 0.30732017755508423 step = 12400: loss = 0.490392804145813 step = 12600: loss = 0.28014713525772095 step = 12800: loss = 0.456543892621994 step = 13000: loss = 0.48237597942352295 step = 13000: Average Return = 182.70 step = 13200: loss = 0.5447070598602295 step = 13400: loss = 0.4602382481098175 step = 13600: loss = 0.5659506320953369 step = 13800: loss = 0.47906267642974854 step = 14000: loss = 0.4060840904712677 step = 14000: Average Return = 153.00 step = 14200: loss = 0.6457054018974304 step = 14400: loss = 0.4795544147491455 step = 14600: loss = 0.16895757615566254 step = 14800: loss = 0.5005109906196594 step = 15000: loss = 0.5339224338531494 step = 15000: Average Return = 165.10
Visualizzazione
trame
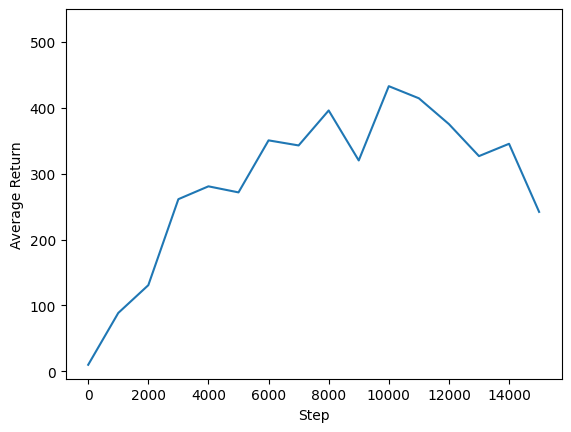
Possiamo tracciare il reso rispetto ai passaggi globali per vedere le prestazioni del nostro agente. In Cartpole-v1 , l'ambiente dà una taglia di +1 per ogni istante soggiorni polari, e poiché il numero massimo di passi è 500, il massimo rendimento possibile anche 500.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=550)
(19.485000991821288, 550.0)
Video
È utile visualizzare le prestazioni di un agente eseguendo il rendering dell'ambiente a ogni passaggio. Prima di farlo, creiamo prima una funzione per incorporare i video in questa colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Il codice seguente visualizza la politica dell'agente per alcuni episodi:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5646eec183c0] Warning: data is not aligned! This can lead to a speed loss
C51 tende a fare leggermente meglio di DQN su CartPole-v1, ma la differenza tra i due agenti diventa sempre più significativa in ambienti sempre più complessi. Ad esempio, sul benchmark completo dell'Atari 2600, C51 mostra un miglioramento medio del punteggio del 126% rispetto a DQN dopo la normalizzazione rispetto a un agente casuale. È possibile ottenere ulteriori miglioramenti includendo aggiornamenti in n passaggi.
Per un tuffo profondo nella algoritmo di C51, vedi Un Distribuzionale Prospettiva sulla Reinforcement Learning (2017) .