
Bản quyền 2021 Các tác giả TF-Agents.
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Giới thiệu
Ví dụ này cho thấy cách để đào tạo một mềm Diễn viên phê bình đại lý trên Minitaur môi trường.
Nếu bạn đã làm việc thông qua các DQN Colab này nên cảm thấy rất quen thuộc. Những thay đổi đáng chú ý bao gồm:
- Thay đổi tác nhân từ DQN sang SAC.
- Đào tạo trên Minitaur, một môi trường phức tạp hơn nhiều so với CartPole. Môi trường Minitaur nhằm đào tạo một robot bốn chân tiến lên phía trước.
- Sử dụng API TF-Agents Actor-Learner cho Học tập củng cố phân tán.
API hỗ trợ cả thu thập dữ liệu phân tán bằng cách sử dụng bộ đệm phát lại trải nghiệm và vùng chứa biến (máy chủ tham số) và đào tạo phân tán trên nhiều thiết bị. API được thiết kế rất đơn giản và theo mô-đun. Chúng tôi sử dụng Reverb cho cả đệm phát lại và chứa biến và TF DistributionStrategy API cho việc đào tạo phân phối trên GPU và TPUs.
Nếu bạn chưa cài đặt các phần phụ thuộc sau, hãy chạy:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Cài đặt
Đầu tiên, chúng tôi sẽ nhập các công cụ khác nhau mà chúng tôi cần.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Siêu tham số
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Môi trường
Các môi trường trong RL đại diện cho nhiệm vụ hoặc vấn đề mà chúng tôi đang cố gắng giải quyết. Môi trường tiêu chuẩn có thể dễ dàng tạo ra trong TF-Đại lý sử dụng suites . Chúng tôi có khác nhau suites cho tải môi trường từ các nguồn như OpenAI phòng tập thể dục, Atari, DM kiểm soát, vv cho một tên môi trường chuỗi.
Bây giờ hãy tải môi trường Minituar từ bộ Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

Trong môi trường này, mục tiêu của đặc vụ là đào tạo một chính sách sẽ điều khiển rô bốt Minitaur và khiến nó di chuyển về phía trước càng nhanh càng tốt. Các tập kéo dài 1000 bước và phần thưởng thu về sẽ là tổng phần thưởng trong suốt tập.
Hãy xem xét các thông tin môi trường cung cấp như một observation mà chính sách này sẽ sử dụng để tạo ra actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
Việc quan sát khá phức tạp. Chúng tôi nhận được 28 giá trị đại diện cho góc, vận tốc và mômen cho tất cả các động cơ. Đổi lại môi trường hy vọng 8 giá trị cho những hành động giữa [-1, 1] . Đây là những góc vận động mong muốn.
Thông thường chúng tôi tạo ra hai môi trường: một để thu thập dữ liệu trong quá trình đào tạo và một để đánh giá. Các môi trường được viết bằng python thuần túy và sử dụng các mảng numpy mà API Actor Learner trực tiếp sử dụng.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Chiến lược phân phối
Chúng tôi sử dụng API DistributionStrategy để cho phép chạy tính toán bước đào tạo trên nhiều thiết bị, chẳng hạn như nhiều GPU hoặc TPU sử dụng song song dữ liệu. Bước tàu:
- Nhận một loạt dữ liệu đào tạo
- Tách nó trên các thiết bị
- Tính toán bước tiến
- Tổng hợp và tính toán MEAN của tổn thất
- Tính toán bước lùi và thực hiện cập nhật biến gradient
Với API TF-Agents Learner và API DistributionStrategy, khá dễ dàng chuyển đổi giữa việc chạy bước đào tạo trên GPU (sử dụng MirroredStrategy) sang TPU (sử dụng TPUStrategy) mà không cần thay đổi bất kỳ logic đào tạo nào bên dưới.
Kích hoạt GPU
Nếu bạn muốn thử chạy trên GPU, trước tiên bạn cần bật GPU cho máy tính xách tay:
- Điều hướng đến Chỉnh sửa → Cài đặt Notebook
- Chọn GPU từ trình đơn thả xuống Trình tăng tốc phần cứng
Chọn một chiến lược
Sử dụng strategy_utils để tạo ra một chiến lược. Dưới mui xe, truyền tham số:
-
use_gpu = Falselợi nhuậntf.distribute.get_strategy(), trong đó sử dụng CPU -
use_gpu = Truelợi nhuậntf.distribute.MirroredStrategy(), trong đó sử dụng tất cả các GPU mà có thể nhìn thấy TensorFlow trên một máy
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Tất cả các biến và các đại lý cần phải được tạo ra dưới strategy.scope() , như bạn sẽ thấy bên dưới.
Đại lý
Để tạo một SAC Agent, trước tiên chúng ta cần tạo các mạng mà nó sẽ đào tạo. SAC là một đại lý phê bình diễn viên, vì vậy chúng tôi sẽ cần hai mạng lưới.
Các nhà phê bình sẽ cho chúng ta ước tính giá trị cho Q(s,a) . Nghĩa là, nó sẽ nhận dưới dạng đầu vào một quan sát và một hành động, và nó sẽ cung cấp cho chúng tôi ước tính về mức độ tốt của hành động đó đối với trạng thái đã cho.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Chúng tôi sẽ sử dụng nhà phê bình này để đào tạo một actor mạng mà sẽ cho phép chúng ta tạo ra những hành động đưa ra một quan sát.
Các ActorNetwork sẽ dự đoán các thông số cho một tanh-ép MultivariateNormalDiag phân phối. Phân phối này sau đó sẽ được lấy mẫu, điều kiện hóa quan sát hiện tại, bất cứ khi nào chúng ta cần tạo ra các hành động.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Với các mạng này, chúng ta có thể khởi tạo đại lý ngay bây giờ.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Replay Buffer
Để theo dõi các dữ liệu thu thập từ môi trường, chúng tôi sẽ sử dụng Reverb , một hệ thống phát lại hiệu quả, mở rộng, và dễ dàng sử dụng bởi Deepmind. Nó lưu trữ dữ liệu kinh nghiệm được thu thập bởi các Diễn viên và được Người học sử dụng trong quá trình đào tạo.
Trong hướng dẫn này, đây là ít quan trọng hơn max_size - nhưng trong một khung cảnh phân phối với bộ sưu tập và đào tạo async, có thể bạn sẽ muốn thử nghiệm với rate_limiters.SampleToInsertRatio , sử dụng một đâu đó samples_per_insert từ 2 đến 1000. Ví dụ:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Các bộ đệm phát lại được xây dựng bằng kỹ thuật mô tả tensors mà phải được lưu trữ, có thể được lấy từ các đại lý sử dụng tf_agent.collect_data_spec .
Kể từ khi Agent SAC cần cả hai hiện tại và quan sát tiếp theo để tính toán sự mất mát, chúng tôi đặt sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Bây giờ chúng ta tạo tập dữ liệu TensorFlow từ bộ đệm phát lại Reverb. Chúng tôi sẽ chuyển điều này cho Người học để lấy mẫu kinh nghiệm để đào tạo.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Chính sách
Trong TF-Đại lý, chính sách đại diện cho quan điểm tiêu chuẩn của chính sách trong RL: cho một time_step tạo ra một hành động hoặc một bản phân phối qua hành động. Phương pháp chính là policy_step = policy.step(time_step) nơi policy_step là một tên tuple PolicyStep(action, state, info) . Các policy_step.action là action được áp dụng đối với môi trường, state đại diện cho nhà nước cho stateful chính sách và (RNN) info có thể chứa thông tin phụ trợ như xác suất log của hành động.
Đại lý có hai chính sách:
-
agent.policy- Chính sách chính được sử dụng để đánh giá và triển khai. -
agent.collect_policy- Một chính sách thứ hai được sử dụng để thu thập dữ liệu.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Các chính sách có thể được tạo độc lập với các đại lý. Ví dụ, sử dụng tf_agents.policies.random_py_policy tạo một chính sách mà sẽ lựa chọn ngẫu nhiên một hành động cho mỗi time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Diễn viên
Tác nhân quản lý các tương tác giữa chính sách và môi trường.
- Các thành phần diễn viên chứa một thể hiện của môi trường (như
py_environment) và một bản sao của các biến chính sách. - Mỗi nhân viên Actor chạy một chuỗi các bước thu thập dữ liệu với các giá trị cục bộ của các biến chính sách.
- Cập nhật biến được thực hiện bằng một cách rõ ràng các trường hợp khách hàng chứa biến trong kịch bản đào tạo trước khi gọi
actor.run(). - Trải nghiệm quan sát được ghi vào bộ đệm phát lại trong mỗi bước thu thập dữ liệu.
Khi các Diễn viên chạy các bước thu thập dữ liệu, chúng chuyển các quỹ đạo của (trạng thái, hành động, phần thưởng) đến người quan sát, được lưu vào bộ nhớ cache và ghi chúng vào hệ thống phát lại Reverb.
Chúng tôi đang lưu trữ quỹ đạo cho khung [(t0, t1) (t1, t2) (t2, t3), ...] vì stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Chúng tôi tạo một Actor với chính sách ngẫu nhiên và thu thập kinh nghiệm để tạo vùng đệm phát lại.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Khởi tạo một Diễn viên với chính sách thu thập để thu thập thêm kinh nghiệm trong quá trình đào tạo.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Tạo một Tác nhân sẽ được sử dụng để đánh giá chính sách trong quá trình đào tạo. Chúng tôi vượt qua trong actor.eval_metrics(num_eval_episodes) để đăng nhập số liệu sau.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Người học
Thành phần Learner chứa tác nhân và thực hiện cập nhật bước gradient cho các biến chính sách bằng cách sử dụng dữ liệu trải nghiệm từ bộ đệm phát lại. Sau một hoặc nhiều bước huấn luyện, Người học có thể đẩy một tập giá trị biến mới vào vùng chứa biến.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Số liệu và Đánh giá
Chúng tôi instantiated Actor eval với actor.eval_metrics trên, mà tạo ra các số liệu phổ biến nhất được sử dụng trong đánh giá chính sách:
- Lợi tức trung bình. Lợi nhuận là tổng số phần thưởng nhận được khi chạy chính sách trong môi trường cho một tập và chúng tôi thường tính trung bình con số này qua một vài tập.
- Độ dài tập trung bình.
Chúng tôi điều hành Actor để tạo ra các chỉ số này.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Kiểm tra các mô-đun số liệu cho việc triển khai tiêu chuẩn khác của số liệu khác nhau.
Đào tạo đại lý
Vòng huấn luyện bao gồm cả việc thu thập dữ liệu từ môi trường và tối ưu hóa mạng của tác nhân. Trên đường đi, chúng tôi sẽ thỉnh thoảng đánh giá chính sách của đại lý để xem chúng tôi đang hoạt động như thế nào.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Hình dung
Lô đất
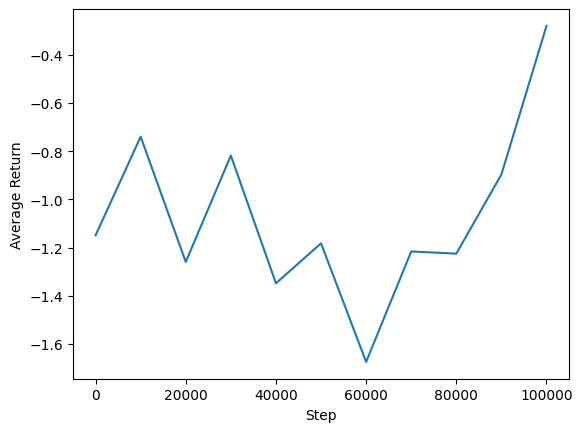
Chúng tôi có thể vẽ biểu đồ lợi nhuận trung bình so với các bước toàn cầu để xem hiệu suất của đại lý của chúng tôi. Trong Minitaur , hàm thưởng được dựa trên cách xa minitaur đi vào năm 1000 bước và phạt các tiêu hao năng lượng.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Video
Sẽ rất hữu ích nếu bạn hình dung hiệu suất của một tác nhân bằng cách hiển thị môi trường ở mỗi bước. Trước khi làm điều đó, trước tiên chúng ta hãy tạo một chức năng để nhúng video vào chuyên mục này.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Đoạn mã sau hiển thị chính sách của đại lý trong một vài tập:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)