
Telif Hakkı 2021 TF-Agents Yazarları.
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Tanıtım
Bu örnek gösterir nasıl bir tren Yumuşak Aktör Eleştirmen üzerinde ajan Minitaur ortamında.
Eğer aracılığıyla çalıştıysanız DQN CoLab bu çok tanıdık olması gerekir. Önemli değişiklikler şunları içerir:
- Aracıyı DQN'den SAC'ye değiştirme.
- CartPole'dan çok daha karmaşık bir ortam olan Minitaur eğitimi. Minitaur ortamı, ilerlemek için dört ayaklı bir robotu eğitmeyi amaçlıyor.
- Dağıtılmış Güçlendirme Öğrenimi için TF-Agents Actor-Learner API'sini kullanma.
API, hem bir deneyim tekrar arabelleği ve değişken kapsayıcı (parametre sunucusu) kullanarak dağıtılmış veri toplamayı hem de birden çok cihaz arasında dağıtılmış eğitimi destekler. API, çok basit ve modüler olacak şekilde tasarlanmıştır. Biz kullanan Reverb tekrar tampon ve değişken konteyner ve her ikisi için TF DistributionStrategy API GPU'ları ve TPU dağıtılan eğitim için.
Aşağıdaki bağımlılıkları yüklemediyseniz, çalıştırın:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Kurmak
İlk önce ihtiyacımız olan farklı araçları içe aktaracağız.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
hiperparametreler
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Çevre
RL'deki ortamlar, çözmeye çalıştığımız görevi veya sorunu temsil eder. Standart ortamlar kolayca kullanarak TF-Ajanlar oluşturulabilir suites . Farklı olan suites bir dize ortamı adı verilen, vb OpenAI Spor Salonu, Atari, DM Kontrol, gibi kaynaklardan ortamları yükleme için.
Şimdi Minituar ortamını Pybullet paketinden yükleyelim.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

Bu ortamda amaç, temsilcinin Minitaur robotunu kontrol edecek ve mümkün olduğunca hızlı ilerlemesini sağlayacak bir politika eğitmesidir. Bölümler 1000 adım sürer ve geri dönüş, bölüm boyunca ödüllerin toplamı olacaktır.
Bilgilere atalım ortamı bir şekilde sağlamaktadır observation politikası oluşturmak için kullanacağı actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
Gözlem oldukça karmaşıktır. Tüm motorlar için açıları, hızları ve torkları temsil eden 28 değer alıyoruz. Bunun karşılığında çevre arasındaki işlemler için 8 değerleri bekliyor [-1, 1] . Bunlar istenilen motor açılarıdır.
Genellikle iki ortam yaratırız: biri eğitim sırasında veri toplamak için, diğeri değerlendirme için. Ortamlar saf python ile yazılmıştır ve Actor Learner API'sinin doğrudan tükettiği numpy dizilerini kullanır.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Dağıtım stratejisi
Veri paralelliğini kullanarak birden çok GPU veya TPU gibi birden çok cihazda tren adımı hesaplamasının çalıştırılmasını sağlamak için DistributionStrategy API'sini kullanıyoruz. Tren adımı:
- Bir grup eğitim verisi alır
- Cihazlar arasında böler
- İleri adımı hesaplar
- Kaybın ORTALAMASINI toplar ve hesaplar
- Geri adımı hesaplar ve bir degrade değişken güncellemesi gerçekleştirir
TF-Agents Learner API ve DistributionStrategy API ile, tren adımını GPU'larda çalıştırma (MirroredStrategy kullanarak) ile TPU'lar (TPUStrategy kullanarak) arasında aşağıdaki eğitim mantığını değiştirmeden geçiş yapmak oldukça kolaydır.
GPU'yu etkinleştirme
Bir GPU üzerinde çalıştırmayı denemek istiyorsanız, öncelikle dizüstü bilgisayar için GPU'ları etkinleştirmeniz gerekir:
- Düzenle → Dizüstü Bilgisayar Ayarları'na gidin
- Donanım Hızlandırıcı açılır menüsünden GPU'yu seçin
Bir strateji seçmek
Kullanım strategy_utils bir strateji oluşturmak için. Kaputun altında, parametreyi geçerek:
-
use_gpu = Falsedönertf.distribute.get_strategy()CPU kullanır, -
use_gpu = Truedöndürürtf.distribute.MirroredStrategy()bir makinede TensorFlow görülebilir tüm GPU'larda kullanır
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Tüm değişkenler ve Ajanlar altında oluşturulan gereken strategy.scope() Aşağıda göreceğiniz gibi.
Ajan
Bir SAC Agent oluşturmak için öncelikle onun eğiteceği ağları oluşturmamız gerekiyor. SAC, aktör-eleştirmen bir ajandır, bu yüzden iki ağa ihtiyacımız olacak.
Eleştirmen bize değer tahminleri verecektir Q(s,a) . Yani girdi olarak bir gözlem ve bir eylem alacak ve bize o eylemin verilen durum için ne kadar iyi olduğuna dair bir tahmin verecektir.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Biz eğitmek için bu eleştirmen kullanacağı actor bize bir gözlem verilen eylemleri oluşturmasını sağlar ağı.
ActorNetwork bir tanh-ezilmiş parametrelerini tahmin edecektir MultivariateNormalDiag dağılımı. Bu dağılım daha sonra, eylemler üretmemiz gerektiğinde mevcut gözleme göre koşullandırılarak örneklenecektir.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Elimizde bu ağlarla, şimdi aracıyı somutlaştırabiliriz.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Tekrar arabelleği
Çevreden toplanan verilerin takip etmek amacıyla, kullanacağı Reverb , Deepmind etkin, genişletilebilir ve kolay kullanımlı yeniden oynatma sistemi. Aktörler tarafından toplanan ve Eğitim sırasında Öğrenci tarafından tüketilen deneyim verilerini depolar.
Bu eğitimde, bu daha az önemlidir max_size - ama zaman uyumsuz toplama ve eğitim ile dağıtılmış bir ortamda, muhtemelen deneme yapmak isteyecektir rate_limiters.SampleToInsertRatio Örneğin 2 ve 1000 arasında bir samples_per_insert bir yere kullanarak:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Tekrar tamponu kullanılarak maddesi elde edilebilir depolanacaksa tensörü tarif gözlük kullanılarak inşa edilir tf_agent.collect_data_spec .
SAC Ajan akımını ve kaybını hesaplamak için bir sonraki gözlem ikisine de ihtiyacı olduğundan, set sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Şimdi Reverb yeniden oynatma arabelleğinden bir TensorFlow veri kümesi oluşturuyoruz. Bunu, eğitim için örnek deneyimler için Öğrenciye ileteceğiz.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Politikalar
TF-Ajanlar olarak, politikaları RL içinde politikaların standart kavramını temsil: Belirli bir time_step bir eylem veya eylemleri üzerinde bir dağılım üretirler. Ana yöntem policy_step = policy.step(time_step) policy_step adlandırılmış başlık olur PolicyStep(action, state, info) . policy_step.action olan action ortamına tatbik edilecek, state durum bilgisi (GSA) politika ve için durumunu temsil eden info , örneğin eylemleri kaydı olasılıkları gibi yardımcı bilgi içerebilir.
Aracılar iki ilke içerir:
-
agent.policy- değerlendirme ve dağıtımda kullanılan ana politikası. -
agent.collect_policy- veri toplama için kullanılan bir ikinci politikası.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Politikalar aracılardan bağımsız olarak oluşturulabilir. Örneğin, kullanmak tf_agents.policies.random_py_policy rastgele her time_step için bir eylem seçecektir bir ilke oluşturmak için.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
aktörler
Aktör, bir politika ve bir çevre arasındaki etkileşimleri yönetir.
- Aktör bileşenleri (aynı ortamda bir örneğini ihtiva
py_environment) ve politika değişkenleri bir kopyasını. - Her Actor çalışanı, ilke değişkenlerinin yerel değerleri verilen bir dizi veri toplama adımı çalıştırır.
- Değişken güncellemeler çağırmadan önce açıkça antrenman komut değişken konteyner istemci örneği kullanılarak yapılır
actor.run(). - Gözlemlenen deneyim, her veri toplama adımında tekrar arabelleğine yazılır.
Aktörler veri toplama adımlarını yürütürken, yörüngeleri (durum, eylem, ödül) gözlemciye iletir, bu da onları önbelleğe alır ve Yankı tekrar sistemine yazar.
Biz çerçeveler için yörüngeleri saklıyoruz [(t0, t1) (t1, t2) (T2, T3), ...] çünkü stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Rastgele politikaya sahip bir Aktör oluşturuyoruz ve tekrar arabelleğini tohumlamak için deneyimler topluyoruz.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Eğitim sırasında daha fazla deneyim toplamak için toplama ilkesiyle bir Aktör örneği oluşturun.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Eğitim sırasında politikayı değerlendirmek için kullanılacak bir Aktör oluşturun. Biz geçmek actor.eval_metrics(num_eval_episodes) sonradan ölçümlerini günlüğe.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
öğrenciler
Öğrenci bileşeni, aracıyı içerir ve tekrar arabelleğindeki deneyim verilerini kullanarak ilke değişkenlerinde gradyan adım güncellemeleri gerçekleştirir. Bir veya daha fazla eğitim adımından sonra Öğrenci, değişken konteynerine yeni bir değişken değerleri kümesi gönderebilir.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Metrikler ve Değerlendirme
Biz birlikte eval Erkek Oyuncu örneği actor.eval_metrics politika değerlendirme sırasında en sık kullanılan ölçümleri oluşturur yukarıda:
- Ortalama getiri. Geri dönüş, bir bölümde bir ortamda bir ilke çalıştırırken elde edilen ödüllerin toplamıdır ve genellikle bunun ortalamasını birkaç bölüm üzerinden alırız.
- Ortalama bölüm uzunluğu.
Bu metrikleri oluşturmak için Aktör'ü çalıştırırız.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Check out ölçümlerini modülü farklı ölçümlerin diğer standart uygulamaları için.
Temsilciyi eğitmek
Eğitim döngüsü, hem ortamdan veri toplamayı hem de aracının ağlarını optimize etmeyi içerir. Yol boyunca, nasıl yaptığımızı görmek için ara sıra temsilcinin politikasını değerlendireceğiz.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
görselleştirme
araziler
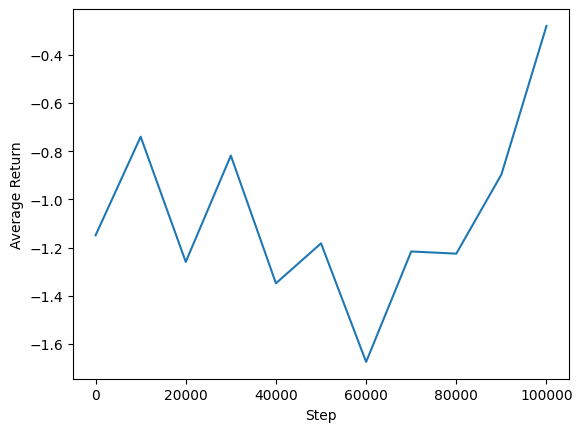
Temsilcimizin performansını görmek için ortalama getiri ile küresel adımların grafiğini çizebiliriz. In Minitaur , ödül fonksiyonu minitaur 1000 adımda yürür ve enerji harcanmasını cezalandırmaktadır ne kadar dayanmaktadır.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Videolar
Her adımda ortamı işleyerek bir aracının performansını görselleştirmek yararlıdır. Bunu yapmadan önce, videoları bu ortak çalışmaya gömmek için bir fonksiyon oluşturalım.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Aşağıdaki kod, aracının birkaç bölüm için politikasını görselleştirir:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)