
Copyright 2021 Gli autori degli agenti TF.
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
introduzione
Questo esempio mostra come addestrare un attore critico soft agente sul Minitaur ambiente.
Se avete lavorato attraverso il DQN Colab questo dovrebbe sentirsi molto familiare. I cambiamenti notevoli includono:
- Modifica dell'agente da DQN a SAC.
- Allenamento su Minitaur che è un ambiente molto più complesso di CartPole. L'ambiente Minitaur mira ad addestrare un robot quadrupede ad andare avanti.
- Utilizzo dell'API TF-Agents Actor-Learner per il Reinforcement Learning distribuito.
L'API supporta sia la raccolta di dati distribuiti utilizzando un buffer di riproduzione dell'esperienza e un contenitore variabile (server di parametri) sia l'addestramento distribuito su più dispositivi. L'API è progettata per essere molto semplice e modulare. Utilizziamo riverbero sia buffer di riproduzione e contenitore variabile e TF DistributionStrategy API per la formazione distribuita su GPU e TPU.
Se non hai installato le seguenti dipendenze, esegui:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Impostare
Per prima cosa importeremo i diversi strumenti di cui abbiamo bisogno.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Iperparametri
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Ambiente
Gli ambienti in RL rappresentano il compito o il problema che stiamo cercando di risolvere. Ambienti standard possono essere create facilmente in TF-agenti che usano suites . Abbiamo diverse suites per il caricamento di ambienti da fonti come l'OpenAI palestra, Atari, DM di controllo, ecc, dato un nome ambiente stringa.
Ora carichiamo l'ambiente Minituar dalla suite Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

In questo ambiente l'obiettivo è che l'agente formi una politica che controlli il robot Minitaur e lo faccia avanzare il più velocemente possibile. Gli episodi durano 1000 passaggi e il ritorno sarà la somma delle ricompense durante l'episodio.
Guardiamo le informazioni l'ambiente offre come un observation che la politica utilizzerà per generare actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
L'osservazione è abbastanza complessa. Riceviamo 28 valori che rappresentano gli angoli, le velocità e le coppie per tutti i motori. In cambio l'ambiente prevede 8 valori per le azioni tra [-1, 1] . Questi sono gli angoli motore desiderati.
Solitamente creiamo due ambienti: uno per la raccolta dei dati durante la formazione e uno per la valutazione. Gli ambienti sono scritti in puro Python e utilizzano array numpy, che l'API Actor Learner consuma direttamente.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Strategia di distribuzione
Utilizziamo l'API DistributionStrategy per consentire l'esecuzione del calcolo del passaggio del treno su più dispositivi come più GPU o TPU utilizzando il parallelismo dei dati. Il passo del treno:
- Riceve un batch di dati di allenamento
- Lo divide tra i dispositivi
- Calcola il passo in avanti
- Aggrega e calcola la MEDIA della perdita
- Calcola il passo indietro ed esegue un aggiornamento della variabile gradiente
Con l'API Learner di TF-Agents e l'API DistributionStrategy è abbastanza facile passare dall'esecuzione della fase di addestramento su GPU (utilizzando MirroredStrategy) a TPU (utilizzando TPUStrategy) senza modificare la logica di addestramento di seguito.
Abilitazione della GPU
Se vuoi provare a eseguire su una GPU, devi prima abilitare le GPU per il notebook:
- Vai a Modifica→Impostazioni notebook
- Seleziona GPU dal menu a discesa Acceleratore hardware
Scegliere una strategia
Utilizzare strategy_utils per generare una strategia. Sotto il cofano, passando il parametro:
-
use_gpu = Falsedichiarazionitf.distribute.get_strategy(), che utilizza CPU -
use_gpu = Truerestituiscetf.distribute.MirroredStrategy(), che utilizza tutte le GPU che sono visibili a tensorflow su una macchina
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Tutte le variabili e gli Agenti devono essere creati sotto strategy.scope() , come si vedrà di seguito.
Agente
Per creare un agente SAC, dobbiamo prima creare le reti che formerà. SAC è un agente critico-attore, quindi avremo bisogno di due reti.
Il critico ci darà stime di valore per Q(s,a) . Cioè, riceverà come input un'osservazione e un'azione, e ci darà una stima di quanto sia stata buona quell'azione per il dato stato.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Useremo questo critico per la formazione di un actor di rete che permetterà di generare le azioni indicate un'osservazione.
ActorNetwork predire i parametri per un tanh-schiacciata MultivariateNormalDiag distribuzione. Questa distribuzione verrà poi campionata, condizionata all'osservazione corrente, ogni volta che avremo bisogno di generare azioni.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Con queste reti a portata di mano ora possiamo creare un'istanza dell'agente.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Replay Buffer
Al fine di tenere traccia dei dati raccolti dall'ambiente, useremo riverbero , un sistema di riproduzione efficiente, estensibile, e di facile utilizzo da Deepmind. Memorizza i dati dell'esperienza raccolti dagli attori e consumati dallo studente durante la formazione.
In questo tutorial, questo è meno importante max_size - ma in un ambiente distribuito con la raccolta e la formazione asincrona, è probabilmente vorranno sperimentare con rate_limiters.SampleToInsertRatio , utilizzando un qualche samples_per_insert tra il 2 e il 1000. Ad esempio:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Buffer di riproduzione è costruito utilizzando specifiche descrivono i tensori che devono essere memorizzati, che possono essere ottenuti con l'agente utilizzando tf_agent.collect_data_spec .
Dal momento che la SAC agente ha bisogno sia la corrente e la successiva osservazione per calcolare la perdita, abbiamo impostato sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Ora generiamo un set di dati TensorFlow dal buffer di riproduzione di Reverb. Passeremo questo allo studente per provare le esperienze per la formazione.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Politiche
Nel TF-agenti, politiche rappresentano la nozione di serie di politiche in RL: dato un time_step produrre un'azione o una distribuzione su azioni. Il metodo principale è policy_step = policy.step(time_step) dove policy_step è una tupla di nome PolicyStep(action, state, info) . Il policy_step.action è l' action da applicare per l'ambiente, state rappresenta lo stato delle politiche stateful (RNN) e info possono contenere informazioni ausiliarie, come le probabilità di registro delle azioni.
Gli agenti contengono due criteri:
-
agent.policy- La politica principale che viene utilizzato per la valutazione e la distribuzione. -
agent.collect_policy- Un secondo criterio che viene utilizzato per la raccolta dei dati.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
I criteri possono essere creati indipendentemente dagli agenti. Ad esempio, utilizzare tf_agents.policies.random_py_policy per creare una politica che casualmente selezionare un'azione per ogni time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
attori
L'attore gestisce le interazioni tra una politica e un ambiente.
- I componenti Attore contengono un'istanza dell'ambiente (come
py_environment) e una copia delle variabili politiche. - Ogni lavoratore Actor esegue una sequenza di passaggi di raccolta dati dati i valori locali delle variabili della policy.
- Aggiornamenti variabili sono fatte in modo esplicito utilizzando l'istanza del client container variabile nello script di formazione prima di chiamare
actor.run(). - L'esperienza osservata viene scritta nel buffer di riproduzione in ogni passaggio di raccolta dati.
Mentre gli attori eseguono le fasi di raccolta dei dati, passano le traiettorie di (stato, azione, ricompensa) all'osservatore, che le memorizza nella cache e le scrive nel sistema di riproduzione Reverb.
Stiamo memorizzare le traiettorie di cornici [(T0, T1) (t1, t2) (t2, t3), ...], perché stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Creiamo un attore con la politica casuale e raccogliamo esperienze con cui seminare il buffer di replay.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Istanzia un attore con la politica di raccolta per raccogliere più esperienze durante la formazione.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Creare un attore che verrà utilizzato per valutare la politica durante la formazione. Passiamo in actor.eval_metrics(num_eval_episodes) per registrare le metriche più tardi.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
studenti
Il componente Learner contiene l'agente ed esegue gli aggiornamenti dei passaggi del gradiente alle variabili della policy utilizzando i dati dell'esperienza dal buffer di riproduzione. Dopo uno o più passaggi di formazione, lo studente può inviare un nuovo set di valori di variabili al contenitore delle variabili.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Metriche e valutazione
Abbiamo istanziato l'attore eval con actor.eval_metrics di cui sopra, che crea le metriche più comunemente utilizzati durante la valutazione delle politiche:
- Rendimento medio. Il rendimento è la somma delle ricompense ottenute durante l'esecuzione di una politica in un ambiente per un episodio e di solito ne facciamo una media su alcuni episodi.
- Durata media degli episodi.
Eseguiamo l'attore per generare queste metriche.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Controlla la modulo di metriche per le altre implementazioni standard di diverse metriche.
Formazione dell'agente
Il ciclo di addestramento prevede sia la raccolta di dati dall'ambiente sia l'ottimizzazione delle reti dell'agente. Lungo la strada, valuteremo occasionalmente la politica dell'agente per vedere come stiamo andando.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Visualizzazione
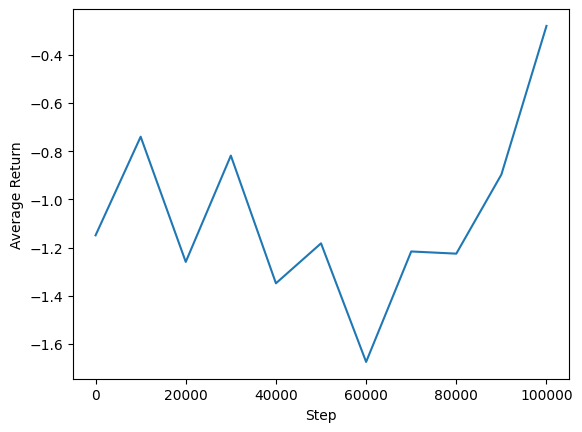
trame
Possiamo tracciare il rendimento medio rispetto ai passaggi globali per vedere le prestazioni del nostro agente. Nel Minitaur , la funzione di remunerazione si basa su quanto il Minitaur cammina in 1000 passi e penalizza il dispendio energetico.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Video
È utile visualizzare le prestazioni di un agente eseguendo il rendering dell'ambiente a ogni passaggio. Prima di farlo, creiamo prima una funzione per incorporare i video in questa colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Il codice seguente visualizza la politica dell'agente per alcuni episodi:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)