
Copyright 2021 Les auteurs TF-Agents.
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
introduction
Cet exemple montre comment former un acteur souple critique agent sur le Minitaur environnement.
Si vous avez travaillé à travers le DQN Colab cela devrait se sentir très familier. Les changements notables incluent :
- Modification de l'agent de DQN à SAC.
- Formation sur Minitaur qui est un environnement beaucoup plus complexe que CartPole. L'environnement Minitaur vise à entraîner un robot quadrupède à avancer.
- Utilisation de l'API Actor-Learner de TF-Agents pour l'apprentissage par renforcement distribué.
L'API prend en charge à la fois la collecte de données distribuée à l'aide d'un tampon de relecture d'expérience et d'un conteneur variable (serveur de paramètres) et la formation distribuée sur plusieurs appareils. L'API est conçue pour être très simple et modulaire. Nous utilisons Reverb pour les deux tampon de lecture et le conteneur variable et TF API DistributionStrategy pour la formation distribuée sur les GPU et PUT.
Si vous n'avez pas installé les dépendances suivantes, exécutez :
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
Installer
Nous allons d'abord importer les différents outils dont nous avons besoin.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Hyperparamètres
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Environnement
Les environnements dans RL représentent la tâche ou le problème que nous essayons de résoudre. Environnements standard peuvent être facilement créés en TF-agents en utilisant des suites . Nous avons différentes suites pour les environnements de chargement provenant de sources telles que le Gym OpenAI, Atari, contrôle DM, etc., étant donné un nom d'environnement de chaîne.
Chargeons maintenant l'environnement Minituar depuis la suite Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

Dans cet environnement, l'objectif est que l'agent forme une politique qui contrôlera le robot Minitaur et le fera avancer le plus rapidement possible. Les épisodes durent 1000 étapes et le retour sera la somme des récompenses tout au long de l'épisode.
Regardons les choses en regard sur l'information de l'environnement dispose d' une observation que la politique utilisera pour générer des actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
L'observation est assez complexe. Nous recevons 28 valeurs représentant les angles, vitesses et couples pour tous les moteurs. En retour , l'environnement prévoit 8 valeurs pour les actions entre [-1, 1] . Ce sont les angles de moteur souhaités.
Habituellement, nous créons deux environnements : un pour la collecte de données pendant la formation et un pour l'évaluation. Les environnements sont écrits en python pur et utilisent des tableaux numpy, que l'API Actor Learner consomme directement.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
Stratégie de distribution
Nous utilisons l'API DistributionStrategy pour permettre l'exécution du calcul de l'étape de train sur plusieurs appareils tels que plusieurs GPU ou TPU en utilisant le parallélisme des données. L'étape du train :
- Reçoit un lot de données d'entraînement
- Le répartit sur les appareils
- Calcule le pas en avant
- Agrége et calcule la MOYENNE de la perte
- Calcule le pas en arrière et effectue une mise à jour de la variable de gradient
Avec l'API Learner TF-Agents et l'API DistributionStrategy, il est assez facile de basculer entre l'exécution de l'étape d'entraînement sur les GPU (à l'aide de MirroredStrategy) aux TPU (à l'aide de TPUStrategy) sans modifier la logique d'entraînement ci-dessous.
Activer le GPU
Si vous voulez essayer de l'exécuter sur un GPU, vous devez d'abord activer les GPU pour le notebook :
- Accédez à Modifier → Paramètres de l'ordinateur portable
- Sélectionnez GPU dans la liste déroulante Accélérateur matériel
Choisir une stratégie
Utilisez strategy_utils pour générer une stratégie. Sous le capot, passage du paramètre :
-
use_gpu = Falserendementstf.distribute.get_strategy(), qui utilise CPU -
use_gpu = Truerendementstf.distribute.MirroredStrategy(), qui utilise tous les GPU qui sont visibles sur une machine tensorflow
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
Toutes les variables et les agents doivent être créés sous strategy.scope() , comme vous le verrez ci - dessous.
Agent
Pour créer un agent SAC, nous devons d'abord créer les réseaux qu'il formera. Le SAC est un agent acteur-critique, nous aurons donc besoin de deux réseaux.
La critique va nous donner des estimations de valeur pour Q(s,a) . C'est-à-dire qu'il recevra en entrée une observation et une action, et il nous donnera une estimation de la qualité de cette action pour l'état donné.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
Nous allons utiliser cette critique pour former un actor réseau qui nous permettra de générer des actions données d'observation.
Le ActorNetwork va prédire les paramètres pour un tanh-écrasé MultivariateNormalDiag distribution. Cette distribution sera ensuite échantillonnée, conditionnée à l'observation courante, chaque fois que nous aurons besoin de générer des actions.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
Avec ces réseaux à portée de main, nous pouvons maintenant instancier l'agent.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Tampon de relecture
Afin de garder une trace des données recueillies à partir de l'environnement, nous allons utiliser la réverbération , un système de lecture efficace, extensible et facile à utiliser par Deepmind. Il stocke les données d'expérience collectées par les Acteurs et consommées par l'Apprenant lors de la formation.
Dans ce tutoriel, il est moins important que max_size - mais dans un cadre distribué avec la collecte async et la formation, vous voudrez probablement expérimenter rate_limiters.SampleToInsertRatio , en utilisant un endroit de samples_per_insert entre 2 et 1000. Par exemple:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
Le tampon de lecture est construite en utilisant les spécifications décrivant les tenseurs qui doivent être stockées, qui peuvent être obtenus à partir de l'agent en utilisant tf_agent.collect_data_spec .
Étant donné que l'agent SAC a besoin à la fois le courant et la prochaine observation pour calculer la perte, nous avons mis en sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Nous générons maintenant un ensemble de données TensorFlow à partir du tampon de relecture Reverb. Nous transmettrons cela à l'apprenant pour qu'il échantillonne des expériences pour la formation.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Stratégies
Dans TF-agents, les politiques représentent la notion classique des politiques dans RL: étant donné un time_step produire une action ou d' une distribution sur actions. La principale méthode est policy_step = policy.step(time_step) où policy_step est un tuple nommé PolicyStep(action, state, info) . Le policy_step.action est une action à appliquer à l'environnement, l' state représente l'état des politiques stateful (RNN) et les info peuvent contenir des informations auxiliaires telles que les probabilités de journal des actions.
Les agents contiennent deux stratégies :
-
agent.policy- La politique principale qui est utilisée pour l' évaluation et le déploiement. -
agent.collect_policy- Une deuxième politique qui est utilisée pour la collecte de données.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Les politiques peuvent être créées indépendamment des agents. Par exemple, utiliser tf_agents.policies.random_py_policy pour créer une politique qui sélectionnera au hasard une action pour chaque time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Acteurs
L'acteur gère les interactions entre une politique et un environnement.
- Les composants Actor contiennent une instance de l'environnement (comme
py_environment) et une copie des variables politiques. - Chaque agent Actor exécute une séquence d'étapes de collecte de données en fonction des valeurs locales des variables de stratégie.
- Mises à jour variables sont effectuées en utilisant explicitement l'instance variable conteneur client dans le script de formation avant d' appeler
actor.run(). - L'expérience observée est écrite dans le tampon de relecture à chaque étape de collecte de données.
Au fur et à mesure que les acteurs exécutent les étapes de collecte de données, ils transmettent des trajectoires (état, action, récompense) à l'observateur, qui les met en cache et les écrit dans le système de relecture Reverb.
Nous nous stockons des trajectoires pour les cadres [(t0, t1) (t1, t2) (t2, t3), ...] parce que stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
Nous créons un acteur avec la politique aléatoire et collectons des expériences avec lesquelles semer le tampon de relecture.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Instanciez un acteur avec la politique de collecte pour recueillir plus d'expériences pendant la formation.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Créez un acteur qui sera utilisé pour évaluer la politique pendant la formation. Nous passons actor.eval_metrics(num_eval_episodes) pour enregistrer des métriques plus tard.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Apprenants
Le composant Apprenant contient l'agent et effectue des mises à jour par étapes de gradient pour les variables de stratégie à l'aide des données d'expérience du tampon de relecture. Après une ou plusieurs étapes de formation, l'apprenant peut pousser un nouvel ensemble de valeurs de variables vers le conteneur de variables.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
Métriques et évaluation
Nous instancié l'acteur eval avec actor.eval_metrics ci - dessus, ce qui crée des paramètres les plus couramment utilisés au cours de l' évaluation des politiques:
- Rendement moyen. Le retour est la somme des récompenses obtenues lors de l'exécution d'une politique dans un environnement pour un épisode, et nous en faisons généralement la moyenne sur quelques épisodes.
- Durée moyenne des épisodes.
Nous exécutons l'acteur pour générer ces métriques.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
Consultez le module de mesures pour d' autres implémentations standard de différentes mesures.
Formation de l'agent
La boucle d'apprentissage consiste à la fois à collecter les données de l'environnement et à optimiser les réseaux de l'agent. En cours de route, nous évaluerons occasionnellement la politique de l'agent pour voir comment nous nous débrouillons.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
Visualisation
Parcelles
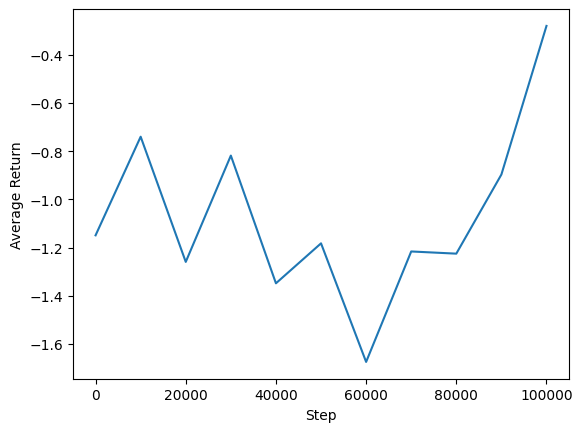
Nous pouvons tracer le rendement moyen par rapport aux étapes globales pour voir les performances de notre agent. En Minitaur , la fonction de récompense est basée sur la distance la marche Minitaur en 1000 pas et pénalisant la dépense d'énergie.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
Vidéos
Il est utile de visualiser les performances d'un agent en restituant l'environnement à chaque étape. Avant de faire cela, créons d'abord une fonction pour intégrer des vidéos dans ce colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Le code suivant visualise la politique de l'agent pour quelques épisodes :
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)