
حقوق الطبع والنشر 2021 The TF-Agents Authors.
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
مقدمة
هذا المثال يبين كيفية تدريب لينة ممثل الناقد عامل على Minitaur البيئة.
إذا كنت قد عملت خلال DQN Colab هذا ينبغي أن يشعر مألوفة للغاية. تشمل التغييرات الملحوظة ما يلي:
- تغيير الوكيل من DQN إلى SAC.
- التدريب على Minitaur وهي بيئة أكثر تعقيدًا بكثير من CartPole. تهدف بيئة Minitaur إلى تدريب روبوت رباعي الحركة على المضي قدمًا.
- استخدام واجهة برمجة تطبيقات TF-Agents Actor-Learner للتعلم المعزز الموزع.
تدعم واجهة برمجة التطبيقات (API) كلاً من جمع البيانات الموزعة باستخدام تجربة إعادة تشغيل المخزن المؤقت والحاوية المتغيرة (خادم المعلمات) والتدريب الموزع عبر أجهزة متعددة. تم تصميم واجهة برمجة التطبيقات لتكون بسيطة جدًا ومعيارية. نحن نستخدم تردد لكلا عازلة اعادتها والحاوية متغير و TF DistributionStrategy API للتدريب موزعة على وحدات معالجة الرسومات وTPUs.
إذا لم تكن قد قمت بتثبيت التبعيات التالية ، فقم بتشغيل:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybullet
اقامة
أولاً سنقوم باستيراد الأدوات المختلفة التي نحتاجها.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
Hyperparameters
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
بيئة
تمثل البيئات في RL المهمة أو المشكلة التي نحاول حلها. البيئات القياسية يمكن أن تنشأ بسهولة في وكلاء TF باستخدام suites . لدينا مختلف suites لتحميل البيئات من مصادر مثل OpenAI رياضة، أتاري، تحكم DM، وما إلى ذلك، يطلق عليها اسم بيئة السلسلة.
لنقم الآن بتحميل بيئة Minituar من مجموعة Pybullet.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Oct 11 2021 20:59:00
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/gym/spaces/box.py:74: UserWarning: WARN: Box bound precision lowered by casting to float32
"Box bound precision lowered by casting to {}".format(self.dtype)
current_dir=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data

في هذه البيئة ، الهدف هو أن يقوم الوكيل بتدريب سياسة من شأنها التحكم في روبوت Minitaur وجعله يتحرك للأمام بأسرع ما يمكن. تدوم الحلقات 1000 خطوة وسيكون العائد هو مجموع المكافآت طوال الحلقة.
دعونا ننظر المعلومات البيئة يوفر باعتبارها observation التي سوف تستخدم لتوليد سياسة actions .
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
الملاحظة معقدة إلى حد ما. نتلقى 28 قيمة تمثل الزوايا والسرعات وعزم الدوران لجميع المحركات. وفي المقابل تتوقع بيئة 8 القيم عن تصرفات بين [-1, 1] . هذه هي الزوايا الحركية المرغوبة.
عادة نقوم بإنشاء بيئتين: واحدة لجمع البيانات أثناء التدريب والأخرى للتقييم. تمت كتابة البيئات بلغة بيثون نقية وتستخدم المصفوفات غير المعقدة ، والتي تستهلكها واجهة برمجة تطبيقات Actor Learner مباشرة.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pybullet_data
أستراتيجية التوزيع
نحن نستخدم DistributionStrategy API لتمكين تشغيل حساب خطوة القطار عبر أجهزة متعددة مثل وحدات معالجة الرسومات المتعددة أو وحدات المعالجة المركزية باستخدام توازي البيانات. خطوة القطار:
- يتلقى دفعة من بيانات التدريب
- يقسمها عبر الأجهزة
- يحسب الخطوة إلى الأمام
- يجمع ويحسب متوسط الخسارة
- يحسب الخطوة الخلفية ويقوم بتحديث متغير التدرج
مع TF-Agents Learner API و DistributionStrategy API ، من السهل جدًا التبديل بين تشغيل خطوة القطار على وحدات معالجة الرسومات (باستخدام MirroredStrategy) إلى TPU (باستخدام TPUStrategy) دون تغيير أي من منطق التدريب أدناه.
تمكين GPU
إذا كنت ترغب في تجربة التشغيل على وحدة معالجة الرسومات (GPU) ، فستحتاج أولاً إلى تمكين وحدات معالجة الرسومات للكمبيوتر الدفتري:
- انتقل إلى تحرير ← إعدادات الكمبيوتر المحمول
- حدد GPU من القائمة المنسدلة Hardware Accelerator
اختيار استراتيجية
استخدام strategy_utils لوضع استراتيجية. تحت الغطاء ، تمرير المعلمة:
-
use_gpu = Falseعوائدtf.distribute.get_strategy()، والذي يستخدم وحدة المعالجة المركزية -
use_gpu = Trueعوائدtf.distribute.MirroredStrategy()، والذي يستخدم جميع وحدات معالجة الرسومات التي هي واضحة إلى TensorFlow على آلة واحدة
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0',)
ويتعين على جميع المتغيرات وكلاء المراد إنشاؤها تحت strategy.scope() ، كما سترى أدناه.
وكيلات
لإنشاء وكيل SAC ، نحتاج أولاً إلى إنشاء الشبكات التي سيقوم بتدريبها. SAC هو وكيل ممثل وناقد ، لذلك سنحتاج إلى شبكتين.
فإن الناقد تعطينا تقديرات قيمة Q(s,a) . أي أنها ستتلقى كمدخل ملاحظة وإجراء ، وستعطينا تقديرًا لمدى جودة هذا الإجراء بالنسبة إلى حالة معينة.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
سوف نستخدم هذا الناقد لتدريب actor الشبكة التي تسمح لنا لتوليد الإجراءات إعطاء الملاحظة.
و ActorNetwork ويتوقع المعلمات عن سحق تان MultivariateNormalDiag التوزيع. سيتم بعد ذلك أخذ عينات من هذا التوزيع ، بشرط الملاحظة الحالية ، كلما احتجنا إلى إنشاء إجراءات.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
مع وجود هذه الشبكات في متناول اليد ، يمكننا الآن إنشاء مثيل للوكيل.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
إعادة العازلة
من أجل تتبع البيانات التي تم جمعها من البيئة، وسوف نستخدم تردد ، ونظام إعادة كفاءة، للمد، وسهلة الاستخدام من قبل Deepmind. يقوم بتخزين بيانات الخبرة التي يجمعها الفاعلون ويستهلكها المتعلم أثناء التدريب.
في هذا البرنامج التعليمي، وهذا هو أقل أهمية من max_size - ولكن في إطار توزيعها مع مجموعة المتزامن والتدريب، وربما كنت ترغب في تجربة rate_limiters.SampleToInsertRatio ، وذلك باستخدام ما samples_per_insert بين 2 و 1000. على سبيل المثال:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpl579aohk. [reverb/cc/platform/tfrecord_checkpointer.cc:386] Loading latest checkpoint from /tmp/tmpl579aohk [reverb/cc/platform/default/server.cc:71] Started replay server on port 15652
يتم إنشاء المخزن المؤقت إعادة استخدام المواصفات واصفا التنسورات التي سيتم تخزينها، والتي يمكن الحصول عليها من وكيل باستخدام tf_agent.collect_data_spec .
منذ كيل SAC يحتاج كل من التيار والمراقبة القادمة لحساب الخسائر، وضعنا sequence_length=2 .
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
نقوم الآن بإنشاء مجموعة بيانات TensorFlow من المخزن المؤقت لإعادة تشغيل Reverb. سنقوم بتمرير هذا إلى المتعلم لأخذ عينات من الخبرات للتدريب.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
سياسات
في وكلاء TF، تمثل سياسات فكرة القياسية السياسات في RL: إعطاء time_step إنتاج عمل أو توزيع أكثر من الإجراءات. الأسلوب الرئيسي هو policy_step = policy.step(time_step) حيث policy_step هو الصفوف (tuple) اسمه PolicyStep(action, state, info) . و policy_step.action هو action ليتم تطبيقها على البيئة، و state تمثل الدولة لسياسات جليل (RNN) و info قد تحتوي على معلومات المساعدة مثل الاحتمالات سجل من الإجراءات.
الوكلاء تحتوي على سياستين:
-
agent.policy- السياسة الرئيسية التي يتم استخدامها لتقييم والنشر. -
agent.collect_policy- سياسة الثانية التي يتم استخدامها لجمع البيانات.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
يمكن إنشاء السياسات بشكل مستقل عن الوكلاء. على سبيل المثال، استخدم tf_agents.policies.random_py_policy لإنشاء نهج الذي سوف تختار عشوائيا إجراء لكل time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
ممثلين
الفاعل يدير التفاعلات بين السياسة والبيئة.
- تحتوي على مكونات ممثل مثيل للبيئة (كما
py_environment) ونسخة من متغيرات السياسة. - يدير كل عامل فاعل سلسلة من خطوات جمع البيانات بالنظر إلى القيم المحلية لمتغيرات السياسة.
- تتم التحديثات المتغيرة بشكل صريح باستخدام المثيل العميل حاوية متغير في البرنامج النصي التدريب قبل استدعاء
actor.run(). - تتم كتابة التجربة التي تمت ملاحظتها في المخزن المؤقت لإعادة التشغيل في كل خطوة من خطوات جمع البيانات.
أثناء تشغيل الممثلين لخطوات جمع البيانات ، يقومون بتمرير مسارات (الحالة ، الإجراء ، المكافأة) إلى المراقب ، الذي يخزنها مؤقتًا ويكتبها إلى نظام إعادة تشغيل Reverb.
نحن تخزين مسارات للإطارات [(T0، T1) (T1، T2) (T2، T3)، ...] ل stride_length=1 .
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
ننشئ ممثلًا بسياسة عشوائية ونجمع الخبرات لبذر المخزن المؤقت لإعادة التشغيل.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
قم بإنشاء ممثل مع سياسة التجميع لجمع المزيد من الخبرات أثناء التدريب.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
قم بإنشاء ممثل يتم استخدامه لتقييم السياسة أثناء التدريب. نحن نمر في actor.eval_metrics(num_eval_episodes) لتسجيل المقاييس في وقت لاحق.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
المتعلمين
يحتوي مكون المتعلم على العامل ويقوم بإجراء تحديثات خطوة التدرج لمتغيرات السياسة باستخدام بيانات الخبرة من المخزن المؤقت لإعادة التشغيل. بعد خطوة تدريب واحدة أو أكثر ، يمكن للمتعلم دفع مجموعة جديدة من القيم المتغيرة إلى الحاوية المتغيرة.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_probability/python/distributions/distribution.py:342: calling MultivariateNormalDiag.__init__ (from tensorflow_probability.python.distributions.mvn_diag) with scale_identity_multiplier is deprecated and will be removed after 2020-01-01. Instructions for updating: `scale_identity_multiplier` is deprecated; please combine it into `scale_diag` directly instead. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' 2021-12-01 12:19:19.139118: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/policy/assets INFO:tensorflow:Assets written to: /tmp/policies/policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:WARNING: Could not serialize policy.distribution() for policy "<tf_agents.policies.actor_policy.ActorPolicy object at 0x7fe64b86ce90>". Calling saved_model.distribution() will raise the following assertion error: missing a required argument: 'distribution' WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets INFO:tensorflow:Assets written to: /tmp/policies/collect_policy/assets WARNING:absl:Function `function_with_signature` contains input name(s) 0/step_type, 0/reward, 0/discount, 0/observation with unsupported characters which will be renamed to step_type, reward, discount, observation in the SavedModel. WARNING:absl:Found untraced functions such as ActorDistributionNetwork_layer_call_fn, ActorDistributionNetwork_layer_call_and_return_conditional_losses, EncodingNetwork_layer_call_fn, EncodingNetwork_layer_call_and_return_conditional_losses, TanhNormalProjectionNetwork_layer_call_fn while saving (showing 5 of 35). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:561: UserWarning: Encoding a StructuredValue with type tf_agents.policies.greedy_policy.DeterministicWithLogProb_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered. "imported and registered." % type_spec_class_name) INFO:tensorflow:Assets written to: /tmp/policies/greedy_policy/assets WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tf_agents/train/learner.py:151: StrategyBase.experimental_distribute_datasets_from_function (from tensorflow.python.distribute.distribute_lib) is deprecated and will be removed in a future version. Instructions for updating: rename to distribute_datasets_from_function
المقاييس والتقييم
نحن مثيل ممثل حدة التقييم مع actor.eval_metrics أعلاه، مما يخلق المقاييس الأكثر استخداما خلال تقييم السياسات:
- متوسط العائد. العائد هو مجموع المكافآت التي تم الحصول عليها أثناء تشغيل سياسة في بيئة للحلقة ، وعادةً ما نقوم بتوسيط هذا على عدة حلقات.
- متوسط طول الحلقة.
نقوم بتشغيل الممثل لتوليد هذه المقاييس.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.963870, AverageEpisodeLength = 204.100006
تحقق من وحدة المقاييس لتطبيقات القياسية الأخرى لمقاييس مختلفة.
تدريب الوكيل
تتضمن حلقة التدريب كلاً من جمع البيانات من البيئة وتحسين شبكات الوكيل. على طول الطريق ، سنقوم من حين لآخر بتقييم سياسة الوكيل لنرى كيف نفعل ذلك.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (14227) so Table uniform_table is accessed directly without gRPC. step = 5000: loss = -50.77360153198242 step = 10000: AverageReturn = -0.734191, AverageEpisodeLength = 299.399994 step = 10000: loss = -57.17308044433594 step = 15000: loss = -31.02552032470703 step = 20000: AverageReturn = -1.243302, AverageEpisodeLength = 432.200012 step = 20000: loss = -20.673084259033203 step = 25000: loss = -12.919441223144531 step = 30000: AverageReturn = -0.205654, AverageEpisodeLength = 280.049988 step = 30000: loss = -5.420497417449951 step = 35000: loss = -4.320608139038086 step = 40000: AverageReturn = -1.193502, AverageEpisodeLength = 378.000000 step = 40000: loss = -4.375732421875 step = 45000: loss = -3.0430049896240234 step = 50000: AverageReturn = -1.299686, AverageEpisodeLength = 482.549988 step = 50000: loss = -0.8907612562179565 step = 55000: loss = 1.2096503973007202 step = 60000: AverageReturn = -0.949927, AverageEpisodeLength = 365.899994 step = 60000: loss = 1.8157628774642944 step = 65000: loss = -4.9070353507995605 step = 70000: AverageReturn = -0.644635, AverageEpisodeLength = 506.399994 step = 70000: loss = -0.33166465163230896 step = 75000: loss = -0.41273507475852966 step = 80000: AverageReturn = 0.331935, AverageEpisodeLength = 604.299988 step = 80000: loss = 1.5354682207107544 step = 85000: loss = -2.058459997177124 step = 90000: AverageReturn = 0.292840, AverageEpisodeLength = 520.450012 step = 90000: loss = 1.2136361598968506 step = 95000: loss = -1.810737133026123 step = 100000: AverageReturn = 0.835265, AverageEpisodeLength = 515.349976 step = 100000: loss = -2.6997461318969727 [reverb/cc/platform/default/server.cc:84] Shutting down replay server
التصور
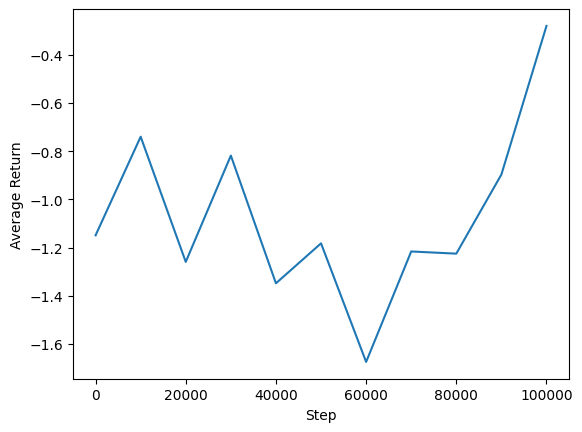
المؤامرات
يمكننا رسم متوسط العائد مقابل الخطوات العامة لمعرفة أداء وكيلنا. في Minitaur ، يستند ظيفة مكافأة على مدى يقطعون minitaur في 1000 خطوات ويعاقب نفقات الطاقة.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.4064332604408265, 0.9420127034187317)
أشرطة فيديو
من المفيد تصور أداء الوكيل عن طريق عرض البيئة في كل خطوة. قبل القيام بذلك ، دعنا أولاً ننشئ وظيفة لتضمين مقاطع الفيديو في هذا الكولاب.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
يوضح الكود التالي سياسة الوكيل لبضع حلقات:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)