
ลิขสิทธิ์ 2021 The TF-Agents Authors.
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทนำ
ตัวอย่างนี้แสดงให้เห็นว่าการฝึกอบรม เสริมสร้าง ตัวแทนในสภาพแวดล้อม Cartpole ใช้ตัวแทน TF ห้องสมุดคล้ายกับ DQN กวดวิชา
เราจะแนะนำคุณเกี่ยวกับองค์ประกอบทั้งหมดในไปป์ไลน์ Reinforcement Learning (RL) สำหรับการฝึกอบรม การประเมิน และการรวบรวมข้อมูล
ติดตั้ง
หากคุณไม่ได้ติดตั้งการพึ่งพาต่อไปนี้ ให้เรียกใช้:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
ไฮเปอร์พารามิเตอร์
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
สิ่งแวดล้อม
สภาพแวดล้อมใน RL แสดงถึงงานหรือปัญหาที่เราพยายามแก้ไข สภาพแวดล้อมมาตรฐานที่สามารถสร้างขึ้นได้อย่างง่ายดายใน TF-ตัวแทนโดยใช้ suites เรามีที่แตกต่างกัน suites สำหรับสภาพแวดล้อมการโหลดจากแหล่งที่มาเช่น OpenAI ยิม, Atari, DM ควบคุม ฯลฯ ได้รับชื่อสภาพแวดล้อมสตริง
ตอนนี้ให้เราโหลดสภาพแวดล้อม CartPole จากชุด OpenAI Gym
env = suite_gym.load(env_name)
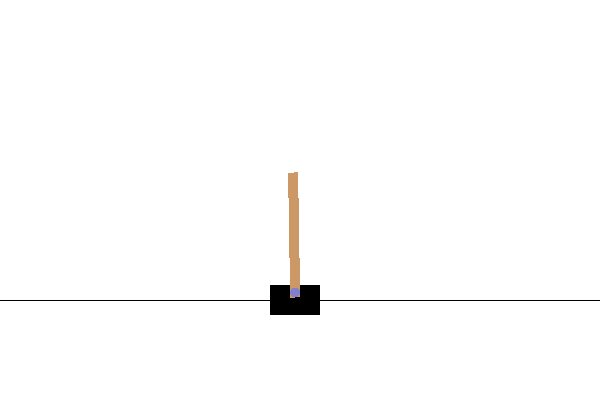
เราสามารถแสดงสภาพแวดล้อมนี้เพื่อดูว่ามีลักษณะอย่างไร มีเสาควงแบบอิสระติดอยู่กับเกวียน เป้าหมายคือการเลื่อนรถเข็นไปทางขวาหรือซ้ายเพื่อให้เสาชี้ขึ้น
env.reset()
PIL.Image.fromarray(env.render())
time_step = environment.step(action) คำสั่งจะใช้เวลา action ในสภาพแวดล้อม TimeStep tuple กลับมามีสภาพแวดล้อมของการสังเกตถัดไปและรางวัลสำหรับการกระทำนั้น time_step_spec() และ action_spec() วิธีการในสภาพแวดล้อมกลับข้อกำหนด (ประเภทรูปร่างขอบเขต) ของ time_step และ action ตามลำดับ
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
ดังนั้นเราจึงเห็นว่าการสังเกตเป็นอาร์เรย์ของ 4 ลอย: ตำแหน่งและความเร็วของเกวียนและตำแหน่งเชิงมุมและความเร็วของเสา ตั้งแต่เพียงสองการกระทำที่เป็นไปได้ (เลื่อนไปทางซ้ายหรือย้ายขวา) action_spec เป็นสเกลาร์ที่ 0 หมายถึง "ย้ายซ้าย" และ 1 หมายถึง "ย้ายขวา."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
โดยปกติเราจะสร้างสองสภาพแวดล้อม: หนึ่งสำหรับการฝึกอบรมและอีกสภาพแวดล้อมสำหรับการประเมิน สภาพแวดล้อมส่วนใหญ่จะเขียนในหลามบริสุทธิ์ แต่พวกเขาสามารถเปลี่ยนได้อย่างง่ายดายเพื่อ TensorFlow ใช้ TFPyEnvironment เสื้อคลุม สภาพแวดล้อมเดิม API ใช้อาร์เรย์ numpy ที่ TFPyEnvironment แปลงเหล่านี้ไปยัง / จาก Tensors สำหรับคุณที่จะได้ง่ายขึ้นโต้ตอบกับนโยบาย TensorFlow และตัวแทน
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
ตัวแทน
ขั้นตอนวิธีการที่เราใช้ในการแก้ปัญหา RL มีการแสดงในฐานะที่เป็น Agent นอกจากนี้ยังมีตัวแทนเสริม, TF-ตัวแทนให้การใช้งานมาตรฐานของความหลากหลายของ Agents เช่น DQN , DDPG , TD3 , PPO และ SAC
เพื่อสร้างเสริมตัวแทนอันดับแรกเราจำเป็นต้องมี Actor Network ที่สามารถเรียนรู้ที่จะคาดการณ์การดำเนินการที่ได้รับการสังเกตจากสภาพแวดล้อม
เราสามารถสร้าง Actor Network โดยใช้รายละเอียดของการสังเกตและการกระทำ เราสามารถระบุชั้นในเครือข่ายซึ่งในตัวอย่างนี้เป็นที่ fc_layer_params ชุดอาร์กิวเมนต์ tuple ของ ints คิดเป็นขนาดของชั้นที่ซ่อนอยู่ในแต่ละ (ดูส่วน Hyperparameters ด้านบน)
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
นอกจากนี้เรายังจำเป็นต้องมีการ optimizer ในการฝึกอบรมเครือข่ายที่เราเพิ่งสร้างและ train_step_counter ตัวแปรในการติดตามของจำนวนครั้งที่เครือข่ายได้รับการปรับปรุง
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
นโยบาย
ในตัวแทน TF, นโยบายการเป็นตัวแทนของความคิดมาตรฐานของนโยบายใน RL: รับ time_step ผลิตการกระทำหรือการกระจายมากกว่าการกระทำ วิธีการหลักคือ policy_step = policy.action(time_step) ที่ policy_step เป็น tuple ชื่อ PolicyStep(action, state, info) policy_step.action คือ action ที่จะนำไปใช้กับสภาพแวดล้อมที่ state เป็นตัวแทนของรัฐในการ stateful (RNN) นโยบายและ info อาจมีข้อมูลเสริมเช่นความน่าจะล็อกการทำงาน
เอเจนต์ประกอบด้วยสองนโยบาย: นโยบายหลักที่ใช้สำหรับการประเมิน/การปรับใช้ (agent.policy) และนโยบายอื่นที่ใช้สำหรับการรวบรวมข้อมูล (agent.collect_policy)
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
ตัวชี้วัดและการประเมินผล
เมตริกที่ใช้บ่อยที่สุดในการประเมินนโยบายคือผลตอบแทนเฉลี่ย การคืนคือผลรวมของรางวัลที่ได้รับขณะดำเนินนโยบายในสภาพแวดล้อมสำหรับตอนหนึ่งๆ และโดยปกติแล้วเราจะเฉลี่ยสิ่งนี้ในช่วงสองสามตอน เราสามารถคำนวณผลตอบแทนเฉลี่ยได้ดังนี้
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
รีเพลย์บัฟเฟอร์
เพื่อที่จะติดตามข้อมูลที่รวบรวมจากสภาพแวดล้อมที่เราจะใช้ พัดโบก , ที่มีประสิทธิภาพ, ขยายและง่ายต่อการใช้งานระบบการเล่นใหม่โดย Deepmind มันเก็บข้อมูลประสบการณ์เมื่อเรารวบรวมวิถีและบริโภคระหว่างการฝึก
บัฟเฟอร์ replay นี้ถูกสร้างโดยใช้รายละเอียดอธิบายเทนเซอร์ที่จะถูกเก็บไว้ซึ่งสามารถได้รับจากตัวแทนโดยใช้ tf_agent.collect_data_spec
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
สำหรับตัวแทนส่วนใหญ่ collect_data_spec เป็น Trajectory ชื่อ tuple ที่มีการสังเกตการกระทำของรางวัลอื่น ๆ
การเก็บรวบรวมข้อมูล
ในขณะที่ REINFORCE เรียนรู้จากทั้งตอน เรากำหนดฟังก์ชันเพื่อรวบรวมตอนโดยใช้นโยบายการเก็บรวบรวมข้อมูลที่กำหนดและบันทึกข้อมูล (การสังเกต การกระทำ รางวัล ฯลฯ) เป็นวิถีในบัฟเฟอร์การเล่นซ้ำ ที่นี่เราใช้ 'PyDriver' เพื่อเรียกใช้การวนรอบการรวบรวมประสบการณ์ คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับไดรเวอร์ตัวแทน TF ของเรา ไดรเวอร์กวดวิชา
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
อบรมตัวแทน
วงการฝึกอบรมเกี่ยวข้องกับทั้งการรวบรวมข้อมูลจากสภาพแวดล้อมและการเพิ่มประสิทธิภาพเครือข่ายของตัวแทน ในระหว่างนี้ เราจะประเมินนโยบายของตัวแทนเป็นครั้งคราวเพื่อดูว่าเราเป็นอย่างไร
การดำเนินการต่อไปนี้จะใช้เวลา ~3 นาที
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
การสร้างภาพ
พล็อต
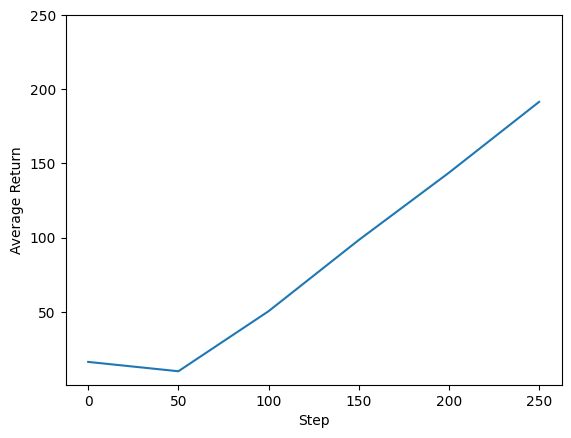
เราสามารถพล็อตผลตอบแทนเทียบกับขั้นตอนระดับโลกเพื่อดูประสิทธิภาพของตัวแทนของเรา ใน Cartpole-v0 สภาพแวดล้อมให้รางวัลของ +1 สำหรับขั้นตอนเวลาทุกการเข้าพักเสาขึ้นและเนื่องจากจำนวนสูงสุดของขั้นตอนคือ 200, ผลตอบแทนที่เป็นไปได้สูงสุดยังเป็น 200
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
วิดีโอ
เป็นประโยชน์ในการแสดงภาพประสิทธิภาพของเอเจนต์ด้วยการแสดงสภาพแวดล้อมในแต่ละขั้นตอน ก่อนที่เราจะทำอย่างนั้น ให้เราสร้างฟังก์ชันเพื่อฝังวิดีโอใน colab นี้ก่อน
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
โค้ดต่อไปนี้แสดงภาพนโยบายของเอเจนต์สำหรับบางตอน:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss