
Copyright 2021 Os autores do TF-Agents.
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Introdução
Este exemplo mostra como treinar um REFORÇAR agente no ambiente Cartpole usando a biblioteca TF-agentes, semelhante ao tutorial DQN .
Vamos guiá-lo por todos os componentes em um pipeline de Reinforcement Learning (RL) para treinamento, avaliação e coleta de dados.
Configurar
Se você não instalou as seguintes dependências, execute:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Hiperparâmetros
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Ambiente
Os ambientes em RL representam a tarefa ou problema que estamos tentando resolver. Ambientes padrão podem ser facilmente criados em TF-agentes usando suites . Temos diferentes suites para carregar ambientes de fontes como o Ginásio OpenAI, Atari, Controle DM, etc., dado um nome de ambiente string.
Agora, vamos carregar o ambiente CartPole da suíte OpenAI Gym.
env = suite_gym.load(env_name)
Podemos renderizar este ambiente para ver como fica. Uma vara de balanço livre é presa a um carrinho. O objetivo é mover o carrinho para a direita ou para a esquerda para manter o mastro apontando para cima.
env.reset()
PIL.Image.fromarray(env.render())
O time_step = environment.step(action) declaração leva action no ambiente. O TimeStep tupla retornada contém próxima observação e de recompensa do ambiente para essa ação. O time_step_spec() e action_spec() métodos no ambiente retornar as especificações (tipos, formas, os limites) do time_step e action respectivamente.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Portanto, vemos que a observação é uma matriz de 4 flutuadores: a posição e a velocidade do carrinho e a posição angular e a velocidade do mastro. Uma vez que apenas duas ações são possíveis (mover para a esquerda ou mover para a direita), o action_spec é um escalar, onde 0 significa "mover para a esquerda" e 1 significa "movimento direito."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Normalmente criamos dois ambientes: um para treinamento e outro para avaliação. A maioria dos ambientes são escritos em python puro, mas eles podem ser facilmente convertidos em TensorFlow usando o TFPyEnvironment wrapper. API do ambiente original usa matrizes numpy, o TFPyEnvironment converte-los para / de Tensors para que você possa mais facilmente interagir com as políticas e agentes TensorFlow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agente
O algoritmo que usamos para resolver um problema RL é representado como um Agent . Em adição ao agente REFORÇAR, TF-Agentes fornece implementações padrão de uma variedade de Agents , tais como DQN , DDPG , TD3 , PPO e SAC .
Para criar um REFORÇAR Agent, primeiro precisamos de um Actor Network que podem aprender a prever a ação dada uma observação do ambiente.
Podemos facilmente criar uma Actor Network usando as especificações das observações e ações. Podemos especificar as camadas em que a rede, neste exemplo, é o fc_layer_params conjunto argumento a um tuplo de ints que representam os tamanhos de cada camada escondida (ver a secção hiperparâmetros acima).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Precisamos também de um optimizer para treinar a rede que acabou de criar, e uma train_step_counter variável para manter o controle de quantas vezes a rede foi atualizado.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Políticas
Em TF-agentes, políticas representam a noção padrão de políticas em RL: dado um time_step produzir uma ação ou distribuição sobre ações. O método principal é policy_step = policy.action(time_step) onde policy_step é uma tupla chamado PolicyStep(action, state, info) . O policy_step.action é a action a ser aplicada ao ambiente, state representa o estado para políticas e stateful (RNN) info podem conter informações auxiliares, tais como probabilidades de registo das acções.
Os agentes contêm duas políticas: a política principal que é usada para avaliação / implementação (agent.policy) e outra política que é usada para coleta de dados (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Métricas e Avaliação
A métrica mais comum usada para avaliar uma política é o retorno médio. O retorno é a soma das recompensas obtidas durante a execução de uma política em um ambiente para um episódio, e normalmente fazemos a média disso em alguns episódios. Podemos calcular a métrica de retorno médio da seguinte maneira.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Replay Buffer
A fim de manter o controle dos dados coletados a partir do ambiente, vamos usar Reverb , um sistema de replay eficiente, extensível e de fácil uso por Deepmind. Ele armazena dados de experiência quando coletamos trajetórias e é consumido durante o treinamento.
Este tampão de repetição é construído utilizando características que descrevem os tensores que são para serem armazenados, os quais podem ser obtidos a partir do agente utilizando tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Para a maioria dos agentes, o collect_data_spec é uma Trajectory denominada tupla contendo a observação, a acção, recompensar etc.
Coleção de dados
Conforme o REINFORCE aprende com episódios inteiros, definimos uma função para coletar um episódio usando a política de coleta de dados fornecida e salvamos os dados (observações, ações, recompensas etc.) como trajetórias no buffer de reprodução. Aqui, estamos usando 'PyDriver' para executar o loop de coleta de experiência. Você pode aprender mais sobre TF agentes motorista na nossa motoristas tutorial .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Treinando o agente
O loop de treinamento envolve a coleta de dados do ambiente e a otimização das redes do agente. Ao longo do caminho, avaliaremos ocasionalmente a política do agente para ver como estamos nos saindo.
O procedimento a seguir levará cerca de 3 minutos para ser executado.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
Visualização
Enredos
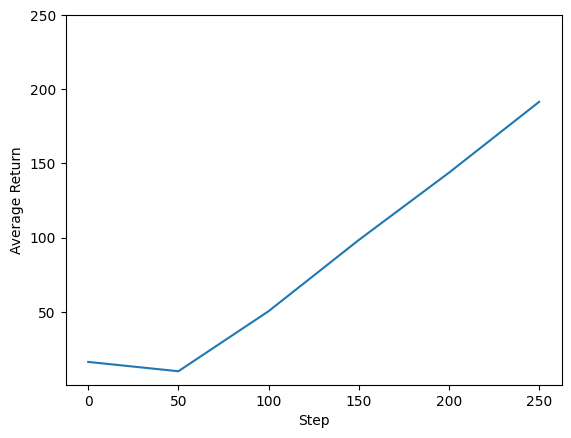
Podemos traçar o retorno versus as etapas globais para ver o desempenho de nosso agente. Em Cartpole-v0 , o ambiente dá uma recompensa de +1 para cada passo de tempo as estadias pólo, e uma vez que o número máximo de etapas é de 200, o máximo retorno possível é também 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Vídeos
É útil visualizar o desempenho de um agente, renderizando o ambiente em cada etapa. Antes de fazermos isso, vamos primeiro criar uma função para incorporar vídeos neste colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
O código a seguir visualiza a política do agente para alguns episódios:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss