
Copyright 2021 Gli autori degli agenti TF.
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
introduzione
Questo esempio mostra come addestrare un rinforzare agente sull'ambiente Cartpole utilizzando la libreria TF-agenti, simile alla esercitazione DQN .
Ti guideremo attraverso tutti i componenti di una pipeline di Reinforcement Learning (RL) per la formazione, la valutazione e la raccolta dei dati.
Impostare
Se non hai installato le seguenti dipendenze, esegui:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Iperparametri
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Ambiente
Gli ambienti in RL rappresentano il compito o il problema che stiamo cercando di risolvere. Ambienti standard possono essere create facilmente in TF-agenti che usano suites . Abbiamo diverse suites per il caricamento di ambienti da fonti come l'OpenAI palestra, Atari, DM di controllo, ecc, dato un nome ambiente stringa.
Ora carichiamo l'ambiente CartPole dalla suite OpenAI Gym.
env = suite_gym.load(env_name)
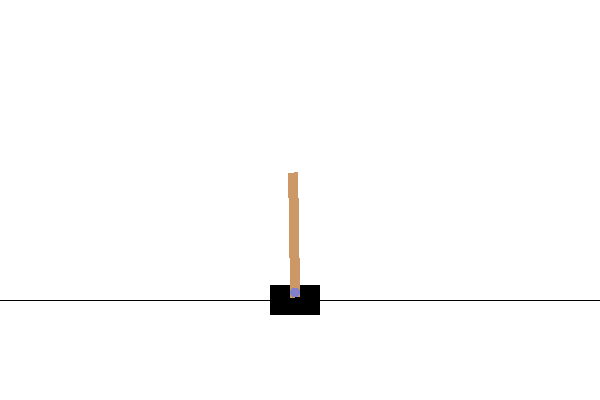
Possiamo renderizzare questo ambiente per vedere come appare. Un palo oscillante è fissato a un carrello. L'obiettivo è spostare il carrello a destra oa sinistra per mantenere il palo rivolto verso l'alto.
env.reset()
PIL.Image.fromarray(env.render())
Il time_step = environment.step(action) dichiarazione prende action per l'ambiente. Il TimeStep tupla restituita contiene successiva osservazione dell'ambiente e la ricompensa per l'azione. Il time_step_spec() e action_spec() metodi nell'ambiente restituiscono specifiche (tipi, forme, bounds) del time_step e action rispettivamente.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Quindi, vediamo che l'osservazione è una matrice di 4 galleggianti: la posizione e la velocità del carrello e la posizione angolare e la velocità del palo. Poiché solo due azioni sono possibili (spostamento a sinistra oa destra muoversi), action_spec è uno scalare dove 0 significa "spostarsi a sinistra" e 1 significa "mossa giusta."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Solitamente creiamo due ambienti: uno per la formazione e uno per la valutazione. La maggior parte degli ambienti sono scritti in puro python, ma possono essere facilmente convertiti in tensorflow utilizzando il TFPyEnvironment involucro. API del contesto originale utilizza matrici numpy, il TFPyEnvironment converte questi per / da Tensors per poter più facilmente interagire con le politiche e gli agenti tensorflow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agente
L'algoritmo che usiamo per risolvere un problema di RL è rappresentato come un Agent . Oltre all'agente REINFORCE, TF-Agenti fornisce implementazioni standard di una varietà di Agents come DQN , DDPG , TD3 , PPO e SAC .
Per creare una rafforzare agente, abbiamo prima bisogno di un Actor Network in grado di imparare a prevedere l'azione data un'osservazione dall'ambiente.
Siamo in grado di creare facilmente una Actor Network utilizzando le specifiche delle osservazioni e delle azioni. Possiamo specificare gli strati della rete che, in questo esempio, è il fc_layer_params impostato argomento ad una tupla di ints che rappresentano le dimensioni di ciascuno strato nascosto (vedere la sezione iperparametri sopra).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Abbiamo anche bisogno di un optimizer per addestrare la rete che abbiamo appena creato, e un train_step_counter variabile per tenere traccia di quante volte è stata aggiornata la rete.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Politiche
Nel TF-agenti, politiche rappresentano la nozione di serie di politiche in RL: dato un time_step produrre un'azione o una distribuzione su azioni. Il metodo principale è policy_step = policy.action(time_step) dove policy_step è una tupla di nome PolicyStep(action, state, info) . Il policy_step.action è l' action da applicare per l'ambiente, state rappresenta lo stato delle politiche stateful (RNN) e info possono contenere informazioni ausiliarie, come le probabilità di registro delle azioni.
Gli agenti contengono due criteri: il criterio principale utilizzato per la valutazione/distribuzione (agent.policy) e un altro criterio utilizzato per la raccolta dei dati (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Metriche e valutazione
La metrica più comune utilizzata per valutare una polizza è il rendimento medio. Il rendimento è la somma delle ricompense ottenute durante l'esecuzione di una politica in un ambiente per un episodio e di solito ne facciamo una media su alcuni episodi. Possiamo calcolare la metrica del rendimento medio come segue.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Replay Buffer
Al fine di tenere traccia dei dati raccolti dall'ambiente, useremo riverbero , un sistema di riproduzione efficiente, estensibile, e di facile utilizzo da Deepmind. Memorizza i dati dell'esperienza quando raccogliamo le traiettorie e viene consumata durante l'allenamento.
Questo buffer di riproduzione è costruito utilizzando specifiche descrivono i tensori che devono essere memorizzati, che possono essere ottenuti con l'agente utilizzando tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Per la maggior parte degli agenti, il collect_data_spec è una Trajectory di nome tupla contenente l'osservazione, azione, ecc premiare
Raccolta dati
Poiché REINFORCE apprende da interi episodi, definiamo una funzione per raccogliere un episodio utilizzando la politica di raccolta dati data e salvare i dati (osservazioni, azioni, ricompense, ecc.) come traiettorie nel buffer di riproduzione. Qui stiamo usando 'PyDriver' per eseguire il ciclo di raccolta dell'esperienza. Potete saperne di più sul driver di agenti TF nel nostro driver esercitazione .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Formazione dell'agente
Il ciclo di addestramento prevede sia la raccolta di dati dall'ambiente sia l'ottimizzazione delle reti dell'agente. Lungo la strada, valuteremo occasionalmente la politica dell'agente per vedere come stiamo andando.
L'esecuzione di quanto segue richiederà ~3 minuti.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
Visualizzazione
trame
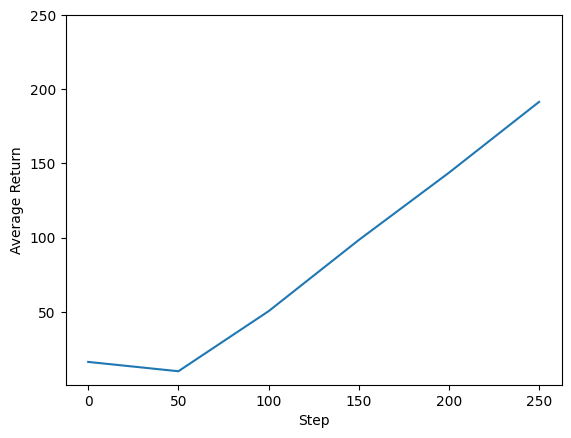
Possiamo tracciare il reso rispetto ai passaggi globali per vedere le prestazioni del nostro agente. In Cartpole-v0 , l'ambiente dà una taglia di +1 per ogni istante soggiorni polari, e poiché il numero massimo di passi è 200, il massimo rendimento possibile anche 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Video
È utile visualizzare le prestazioni di un agente eseguendo il rendering dell'ambiente a ogni passaggio. Prima di farlo, creiamo prima una funzione per incorporare i video in questa colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Il codice seguente visualizza la politica dell'agente per alcuni episodi:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss