
Hak Cipta 2021 The TF-Agents Authors.
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
pengantar
Contoh ini menunjukkan bagaimana untuk melatih MEMPERKUAT agen di lingkungan Cartpole menggunakan perpustakaan TF-Agen, mirip dengan tutorial DQN .
Kami akan memandu Anda melalui semua komponen dalam alur Pembelajaran Penguatan (RL) untuk pelatihan, evaluasi, dan pengumpulan data.
Mempersiapkan
Jika Anda belum menginstal dependensi berikut, jalankan:
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet xvfbwrapper
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.reinforce import reinforce_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import py_tf_eager_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
Hyperparameter
env_name = "CartPole-v0" # @param {type:"string"}
num_iterations = 250 # @param {type:"integer"}
collect_episodes_per_iteration = 2 # @param {type:"integer"}
replay_buffer_capacity = 2000 # @param {type:"integer"}
fc_layer_params = (100,)
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 25 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 50 # @param {type:"integer"}
Lingkungan
Lingkungan di RL mewakili tugas atau masalah yang kami coba selesaikan. Lingkungan standar dapat dengan mudah dibuat di TF-Agen menggunakan suites . Kami memiliki berbagai suites untuk memuat lingkungan dari sumber-sumber seperti OpenAI Gym, Atari, DM Control, dll, diberi nama lingkungan tali.
Sekarang mari kita memuat lingkungan CartPole dari suite OpenAI Gym.
env = suite_gym.load(env_name)
Kita dapat membuat lingkungan ini untuk melihat tampilannya. Sebuah tiang yang berayun bebas dipasang pada sebuah kereta. Tujuannya adalah untuk menggerakkan gerobak ke kanan atau ke kiri agar tiang tetap mengarah ke atas.
env.reset()
PIL.Image.fromarray(env.render())
The time_step = environment.step(action) pernyataan mengambil action di lingkungan. The TimeStep tuple kembali mengandung pengamatan berikutnya lingkungan dan hadiah untuk tindakan itu. The time_step_spec() dan action_spec() metode dalam lingkungan kembali spesifikasi (jenis, bentuk, batas) dari time_step dan action masing-masing.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Jadi, kita melihat bahwa pengamatan adalah susunan 4 pelampung: posisi dan kecepatan kereta, dan posisi sudut dan kecepatan tiang. Karena hanya dua tindakan yang mungkin (bergerak ke kiri atau bergerak ke kanan), yang action_spec adalah skalar di mana 0 berarti "bergerak ke kiri" dan 1 berarti "tindakan yang benar."
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02284177, -0.04785635, 0.04171623, 0.04942273], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.02188464, 0.14664337, 0.04270469, -0.22981201], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
Biasanya kami membuat dua lingkungan: satu untuk pelatihan dan satu untuk evaluasi. Kebanyakan lingkungan ditulis dalam python murni, tetapi mereka dapat dengan mudah dikonversi ke TensorFlow menggunakan TFPyEnvironment pembungkus. API lingkungan asli menggunakan array numpy, yang TFPyEnvironment mengkonversi ini ke / dari Tensors bagi Anda untuk lebih mudah berinteraksi dengan kebijakan dan agen TensorFlow.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
Agen
Algoritma yang kita gunakan untuk memecahkan masalah RL diwakili sebagai Agent . Selain MEMPERKUAT agen, TF-Agen menyediakan implementasi standar dari berbagai Agents seperti DQN , DDPG , TD3 , PPO dan SAC .
Untuk membuat MEMPERKUAT Agen, pertama kita perlu Actor Network yang dapat belajar untuk memprediksi tindakan diberikan pengamatan dari lingkungan.
Kita dapat dengan mudah membuat Actor Network menggunakan spesifikasi dari pengamatan dan tindakan. Kita dapat menentukan lapisan dalam jaringan yang, dalam contoh ini, adalah fc_layer_params argumen set untuk tupel dari ints mewakili ukuran setiap lapisan tersembunyi (lihat bagian Hyperparameters atas).
actor_net = actor_distribution_network.ActorDistributionNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
Kami juga membutuhkan optimizer untuk melatih jaringan yang baru kita buat, dan train_step_counter variabel untuk melacak berapa kali jaringan telah diupdate.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
tf_agent = reinforce_agent.ReinforceAgent(
train_env.time_step_spec(),
train_env.action_spec(),
actor_network=actor_net,
optimizer=optimizer,
normalize_returns=True,
train_step_counter=train_step_counter)
tf_agent.initialize()
Kebijakan
Dalam TF-Agen, kebijakan mewakili gagasan standar kebijakan di RL: diberi time_step menghasilkan suatu tindakan atau distribusi melalui tindakan. Metode utama adalah policy_step = policy.action(time_step) di mana policy_step adalah bernama tuple PolicyStep(action, state, info) . The policy_step.action adalah action yang akan diterapkan untuk lingkungan, state mewakili negara untuk stateful (RNN) kebijakan dan info mungkin berisi informasi tambahan seperti probabilitas log tindakan.
Agen berisi dua kebijakan: kebijakan utama yang digunakan untuk evaluasi/penyebaran (agent.policy) dan kebijakan lain yang digunakan untuk pengumpulan data (agent.collect_policy).
eval_policy = tf_agent.policy
collect_policy = tf_agent.collect_policy
Metrik dan Evaluasi
Metrik yang paling umum digunakan untuk mengevaluasi kebijakan adalah pengembalian rata-rata. Pengembaliannya adalah jumlah hadiah yang diperoleh saat menjalankan kebijakan di lingkungan untuk sebuah episode, dan kami biasanya menghitung rata-rata ini selama beberapa episode. Kita dapat menghitung metrik pengembalian rata-rata sebagai berikut.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# Please also see the metrics module for standard implementations of different
# metrics.
Buffer Putar Ulang
Dalam rangka untuk melacak data yang dikumpulkan dari lingkungan, kita akan menggunakan Reverb , sistem ulangan efisien, extensible, dan mudah digunakan oleh Deepmind. Ini menyimpan data pengalaman saat kami mengumpulkan lintasan dan dikonsumsi selama pelatihan.
Penyangga ulangan ini dibangun menggunakan spesifikasi menggambarkan tensor yang akan disimpan, yang dapat diperoleh dari agen menggunakan tf_agent.collect_data_spec .
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
tf_agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
table_name=table_name,
sequence_length=None,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddEpisodeObserver(
replay_buffer.py_client,
table_name,
replay_buffer_capacity
)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpem6la471. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpem6la471 [reverb/cc/platform/default/server.cc:71] Started replay server on port 19822
Bagi kebanyakan agen, collect_data_spec adalah Trajectory bernama tuple mengandung pengamatan, tindakan, penghargaan dll
Pengumpulan data
Saat REINFORCE belajar dari seluruh episode, kami mendefinisikan fungsi untuk mengumpulkan episode menggunakan kebijakan pengumpulan data yang diberikan dan menyimpan data (pengamatan, tindakan, penghargaan, dll.) sebagai lintasan dalam buffer pemutaran ulang. Di sini kami menggunakan 'PyDriver' untuk menjalankan loop pengumpulan pengalaman. Anda dapat mempelajari lebih lanjut tentang pengemudi TF Agen di kami tutorial driver .
def collect_episode(environment, policy, num_episodes):
driver = py_driver.PyDriver(
environment,
py_tf_eager_policy.PyTFEagerPolicy(
policy, use_tf_function=True),
[rb_observer],
max_episodes=num_episodes)
initial_time_step = environment.reset()
driver.run(initial_time_step)
Melatih agen
Loop pelatihan melibatkan pengumpulan data dari lingkungan dan mengoptimalkan jaringan agen. Sepanjang jalan, kami sesekali akan mengevaluasi kebijakan agen untuk melihat bagaimana kinerja kami.
Berikut ini akan memakan waktu ~3 menit untuk dijalankan.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
tf_agent.train = common.function(tf_agent.train)
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few episodes using collect_policy and save to the replay buffer.
collect_episode(
train_py_env, tf_agent.collect_policy, collect_episodes_per_iteration)
# Use data from the buffer and update the agent's network.
iterator = iter(replay_buffer.as_dataset(sample_batch_size=1))
trajectories, _ = next(iterator)
train_loss = tf_agent.train(experience=trajectories)
replay_buffer.clear()
step = tf_agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss.loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
[reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 25: loss = 0.8549901247024536 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 50: loss = 1.0025296211242676 step = 50: Average Return = 23.200000762939453 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 75: loss = 1.1377763748168945 step = 100: loss = 1.318871021270752 step = 100: Average Return = 159.89999389648438 step = 125: loss = 1.5053682327270508 [reverb/cc/client.cc:163] Sampler and server are owned by the same process (20164) so Table uniform_table is accessed directly without gRPC. step = 150: loss = 0.8051948547363281 step = 150: Average Return = 184.89999389648438 step = 175: loss = 0.6872963905334473 step = 200: loss = 2.7238712310791016 step = 200: Average Return = 186.8000030517578 step = 225: loss = 0.7495002746582031 step = 250: loss = -0.3333401679992676 step = 250: Average Return = 200.0
visualisasi
Plot
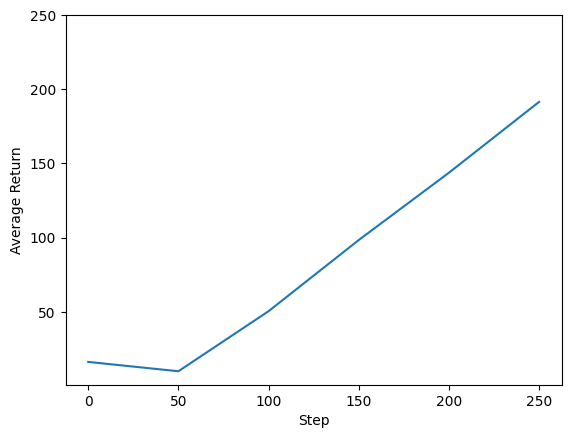
Kami dapat merencanakan langkah pengembalian vs global untuk melihat kinerja agen kami. Dalam Cartpole-v0 , lingkungan memberikan hadiah 1 untuk setiap kali langkah tiang tetap up, dan karena jumlah maksimum langkah adalah 200, kemungkinan kembali maksimum adalah juga 200.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim(top=250)
(-0.2349997997283939, 250.0)
Video
Sangat membantu untuk memvisualisasikan kinerja agen dengan memberikan lingkungan pada setiap langkah. Sebelum itu, mari kita buat dulu fungsi untuk menyematkan video di colab ini.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
Kode berikut memvisualisasikan kebijakan agen untuk beberapa episode:
num_episodes = 3
video_filename = 'imageio.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = tf_agent.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
embed_mp4(video_filename)
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x5604d224f3c0] Warning: data is not aligned! This can lead to a speed loss