
Copyright 2021 TF 에이전트 작성자.
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
소개
기차하는 방법이 예제 프로그램 DQN (깊은 Q 네트워크) TF-에이전트 라이브러리를 사용하여 Cartpole 환경에 에이전트를.

교육, 평가 및 데이터 수집을 위한 강화 학습(RL) 파이프라인의 모든 구성 요소를 안내합니다.
이 코드를 실시간으로 실행하려면 위의 'Google Colab에서 실행' 링크를 클릭하세요.
설정
다음 종속성을 설치하지 않은 경우 다음을 실행합니다.
sudo apt-get updatesudo apt-get install -y xvfb ffmpeg freeglut3-devpip install 'imageio==2.4.0'pip install pyvirtualdisplaypip install tf-agents[reverb]pip install pyglet
from __future__ import absolute_import, division, print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import reverb
import tensorflow as tf
from tf_agents.agents.dqn import dqn_agent
from tf_agents.drivers import py_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import sequential
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.trajectories import trajectory
from tf_agents.specs import tensor_spec
from tf_agents.utils import common
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
tf.version.VERSION
'2.6.0'
초매개변수
num_iterations = 20000 # @param {type:"integer"}
initial_collect_steps = 100 # @param {type:"integer"}
collect_steps_per_iteration = 1# @param {type:"integer"}
replay_buffer_max_length = 100000 # @param {type:"integer"}
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 200 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
환경
강화 학습(RL)에서 환경은 해결해야 할 작업이나 문제를 나타냅니다. 표준 환경을 사용하여 TF-에이전트에서 생성 할 수 있습니다 tf_agents.environments 스위트 룸. TF-Agents에는 OpenAI Gym, Atari 및 DM Control과 같은 소스에서 환경을 로드하기 위한 제품군이 있습니다.
OpenAI 체육관 제품군에서 CartPole 환경을 로드합니다.
env_name = 'CartPole-v0'
env = suite_gym.load(env_name)
이 환경을 렌더링하여 어떻게 보이는지 확인할 수 있습니다. 자유롭게 흔들리는 기둥이 카트에 부착되어 있습니다. 목표는 막대가 위를 향하도록 카트를 오른쪽이나 왼쪽으로 움직이는 것입니다.
env.reset()
PIL.Image.fromarray(env.render())
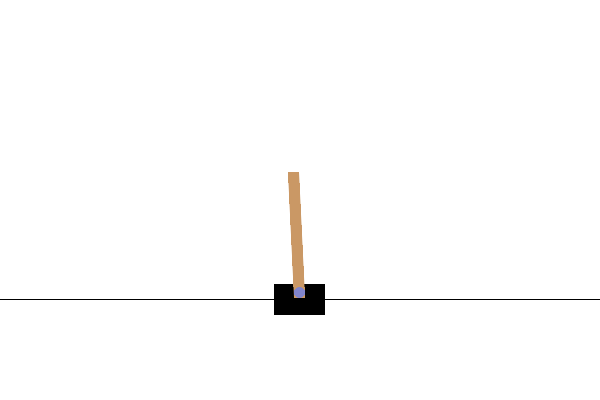
environment.step 방법은 걸리는 action 환경에서을하고 반환 TimeStep 환경의 다음 관찰 및 행동에 대한 보상을 포함하는 튜플을.
time_step_spec() 메소드에 대한 사양 반환 TimeStep 튜플. 그 observation 속성 방송 관측 형상 데이터 유형 및 허용 값의 범위이다. reward 속성은 보상에 대해 동일한 정보를 보여줍니다.
print('Observation Spec:')
print(env.time_step_spec().observation)
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
print('Reward Spec:')
print(env.time_step_spec().reward)
Reward Spec:
ArraySpec(shape=(), dtype=dtype('float32'), name='reward')
action_spec() 메소드는 형상, 데이터 유형, 및 유효한 조치 허용 값을 반환한다.
print('Action Spec:')
print(env.action_spec())
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
Cartpole 환경에서:
-
observation4 플로트 배열이다 :- 카트의 위치와 속도
- 극의 각 위치와 속도
-
reward스칼라 플로트 값 -
action오직 두 가지 값을 갖는 스칼라 정수이다 :-
0- "이동 왼쪽" -
1- "이동 오른쪽"
-
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([-0.02109759, -0.00062286, 0.04167245, -0.03825747], dtype=float32),
'reward': array(0., dtype=float32),
'step_type': array(0, dtype=int32)})
Next time step:
TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([-0.02111005, 0.1938775 , 0.0409073 , -0.31750655], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)})
일반적으로 두 가지 환경이 인스턴스화됩니다. 하나는 교육용이고 다른 하나는 평가용입니다.
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
Cartpole 환경은 대부분의 환경과 마찬가지로 순수한 Python으로 작성되었습니다. 이것은 사용 TensorFlow로 변환됩니다 TFPyEnvironment 래퍼.
원래 환경의 API는 Numpy 배열을 사용합니다. TFPyEnvironment 로 변환이 Tensors Tensorflow 에이전트 및 정책에 호환되도록합니다.
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
에이전트
RL 문제를 해결하는 데 사용되는 알고리즘은으로 표시됩니다 Agent . TF-에이전트의 다양한 표준 구현 제공 Agents 포함 :
DQN 에이전트는 개별 작업 공간이 있는 모든 환경에서 사용할 수 있습니다.
DQN 에이전트의 핵심은입니다 QNetwork , 예측 배울 수있는 신경망 모델 QValues 환경에서 관찰 주어진 모든 작업 (기대 수익률)를.
우리는 사용 tf_agents.networks. 만들 수 QNetwork . 네트워크는 일련의 구성된다 tf.keras.layers.Dense 최종 층은 각각의 가능한 작용에 대한 1 개 출력을 가질 것이다 층.
fc_layer_params = (100, 50)
action_tensor_spec = tensor_spec.from_spec(env.action_spec())
num_actions = action_tensor_spec.maximum - action_tensor_spec.minimum + 1
# Define a helper function to create Dense layers configured with the right
# activation and kernel initializer.
def dense_layer(num_units):
return tf.keras.layers.Dense(
num_units,
activation=tf.keras.activations.relu,
kernel_initializer=tf.keras.initializers.VarianceScaling(
scale=2.0, mode='fan_in', distribution='truncated_normal'))
# QNetwork consists of a sequence of Dense layers followed by a dense layer
# with `num_actions` units to generate one q_value per available action as
# its output.
dense_layers = [dense_layer(num_units) for num_units in fc_layer_params]
q_values_layer = tf.keras.layers.Dense(
num_actions,
activation=None,
kernel_initializer=tf.keras.initializers.RandomUniform(
minval=-0.03, maxval=0.03),
bias_initializer=tf.keras.initializers.Constant(-0.2))
q_net = sequential.Sequential(dense_layers + [q_values_layer])
지금 사용 tf_agents.agents.dqn.dqn_agent 인스턴스화 DqnAgent . 또한받는 time_step_spec , action_spec 및 QNetwork 에이전트 생성자는 (이 경우, 최적화가 필요 AdamOptimizer ) 손실 함수 및 정수 스텝 카운터.
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = dqn_agent.DqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network=q_net,
optimizer=optimizer,
td_errors_loss_fn=common.element_wise_squared_loss,
train_step_counter=train_step_counter)
agent.initialize()
정책
정책은 에이전트가 환경에서 작동하는 방식을 정의합니다. 일반적으로 강화 학습의 목표는 정책이 원하는 결과를 생성할 때까지 기본 모델을 훈련하는 것입니다.
이 튜토리얼에서:
- 원하는 결과는 장대를 카트 위에서 수직으로 균형을 유지하는 것입니다.
- 이 정책은 각 (왼쪽 또는 오른쪽) 액션 반환
time_step관찰.
에이전트에는 두 가지 정책이 포함됩니다.
-
agent.policy- 평가 및 배포에 사용되는 주요 정책. -
agent.collect_policy- 데이터 수집에 사용되는 제 2 정책.
eval_policy = agent.policy
collect_policy = agent.collect_policy
정책은 에이전트와 독립적으로 생성할 수 있습니다. 예를 들어, 사용 tf_agents.policies.random_tf_policy 무작위로 각에 대한 작업을 선택하는 정책을 만들 수 time_step .
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
정책에서 작업을 얻으려면, 전화 policy.action(time_step) 방법을. time_step 환경에서 관찰이 포함되어 있습니다. 이 방법은 반환 PolicyStep 세 가지 구성 요소로 명명 된 튜플입니다 :
-
action- 취해질 액션 (이 경우,0또는1) -
state- 상태 사용 정책 (이다 RNN은 기반) -
info- 같은 행동의 로그 확률로 보조 데이터,
example_environment = tf_py_environment.TFPyEnvironment(
suite_gym.load('CartPole-v0'))
time_step = example_environment.reset()
random_policy.action(time_step)
PolicyStep(action=<tf.Tensor: shape=(1,), dtype=int64, numpy=array([1])>, state=(), info=())
측정항목 및 평가
정책을 평가하는 데 사용되는 가장 일반적인 지표는 평균 수익률입니다. 수익은 에피소드에 대한 환경에서 정책을 실행하는 동안 얻은 보상의 합계입니다. 여러 에피소드가 실행되어 평균 수익을 창출합니다.
다음 함수는 정책, 환경 및 에피소드 수를 고려하여 정책의 평균 수익을 계산합니다.
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# See also the metrics module for standard implementations of different metrics.
# https://github.com/tensorflow/agents/tree/master/tf_agents/metrics
이 계산상의 실행 random_policy 환경에서 기본 성능을 나타낸다.
compute_avg_return(eval_env, random_policy, num_eval_episodes)
20.7
재생 버퍼
환경에서 수집 된 데이터를 추적하기 위해, 우리는 사용하는 리버브 (Reverb) , Deepmind하여, 효율적으로 확장, 사용하기 쉬운 재생 시스템. 궤적을 수집할 때 경험 데이터를 저장하고 훈련 중에 소비합니다.
이 재생 버퍼는 저장될 텐서를 설명하는 사양을 사용하여 구성되며 이는 agent.collect_data_spec을 사용하여 에이전트에서 얻을 수 있습니다.
table_name = 'uniform_table'
replay_buffer_signature = tensor_spec.from_spec(
agent.collect_data_spec)
replay_buffer_signature = tensor_spec.add_outer_dim(
replay_buffer_signature)
table = reverb.Table(
table_name,
max_size=replay_buffer_max_length,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1),
signature=replay_buffer_signature)
reverb_server = reverb.Server([table])
replay_buffer = reverb_replay_buffer.ReverbReplayBuffer(
agent.collect_data_spec,
table_name=table_name,
sequence_length=2,
local_server=reverb_server)
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
replay_buffer.py_client,
table_name,
sequence_length=2)
[reverb/cc/platform/tfrecord_checkpointer.cc:150] Initializing TFRecordCheckpointer in /tmp/tmpcz7e0i7c. [reverb/cc/platform/tfrecord_checkpointer.cc:385] Loading latest checkpoint from /tmp/tmpcz7e0i7c [reverb/cc/platform/default/server.cc:71] Started replay server on port 21909
대부분의 에이전트의 경우, collect_data_spec 라고 명명 된 튜플 Trajectory 관찰, 행동, 보상 및 기타 항목에 대한 사양을 포함하는가.
agent.collect_data_spec
Trajectory(
{'action': BoundedTensorSpec(shape=(), dtype=tf.int64, name='action', minimum=array(0), maximum=array(1)),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': BoundedTensorSpec(shape=(4,), dtype=tf.float32, name='observation', minimum=array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38],
dtype=float32), maximum=array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38],
dtype=float32)),
'policy_info': (),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type')})
agent.collect_data_spec._fields
('step_type',
'observation',
'action',
'policy_info',
'next_step_type',
'reward',
'discount')
데이터 수집
이제 몇 단계 동안 환경에서 임의 정책을 실행하여 재생 버퍼에 데이터를 기록합니다.
여기서 우리는 경험 수집 루프를 실행하기 위해 'PyDriver'를 사용하고 있습니다. 당신은 우리의 더 많은 TF 에이전트 드라이버에 대한 배울 수있는 드라이버 튜토리얼 .
py_driver.PyDriver(
env,
py_tf_eager_policy.PyTFEagerPolicy(
random_policy, use_tf_function=True),
[rb_observer],
max_steps=initial_collect_steps).run(train_py_env.reset())
(TimeStep(
{'discount': array(1., dtype=float32),
'observation': array([ 0.04100575, 0.16847703, -0.12718087, -0.6300714 ], dtype=float32),
'reward': array(1., dtype=float32),
'step_type': array(1, dtype=int32)}),
())
재생 버퍼는 이제 궤적 모음입니다.
# For the curious:
# Uncomment to peel one of these off and inspect it.
# iter(replay_buffer.as_dataset()).next()
에이전트는 재생 버퍼에 액세스해야 합니다. 이것은 반복 가능 만들어서 제공 tf.data.Dataset 에이전트로 데이터를 공급한다 파이프 라인.
재생 버퍼의 각 행은 단일 관찰 단계만 저장합니다. DQN 에이전트가 손실을 계산하기 위해 모두 현재와 다음의 관찰을 필요로하지만 이후, 데이터 세트 파이프 라인은 배치 (각 항목에 대한 두 개의 인접한 행을 샘플링합니다 num_steps=2 ).
이 데이터 세트는 병렬 호출을 실행하고 데이터를 미리 가져옴으로써 최적화됩니다.
# Dataset generates trajectories with shape [Bx2x...]
dataset = replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=batch_size,
num_steps=2).prefetch(3)
dataset
<PrefetchDataset shapes: (Trajectory(
{action: (64, 2),
discount: (64, 2),
next_step_type: (64, 2),
observation: (64, 2, 4),
policy_info: (),
reward: (64, 2),
step_type: (64, 2)}), SampleInfo(key=(64, 2), probability=(64, 2), table_size=(64, 2), priority=(64, 2))), types: (Trajectory(
{action: tf.int64,
discount: tf.float32,
next_step_type: tf.int32,
observation: tf.float32,
policy_info: (),
reward: tf.float32,
step_type: tf.int32}), SampleInfo(key=tf.uint64, probability=tf.float64, table_size=tf.int64, priority=tf.float64))>
iterator = iter(dataset)
print(iterator)
<tensorflow.python.data.ops.iterator_ops.OwnedIterator object at 0x7f3cec38cd90>
# For the curious:
# Uncomment to see what the dataset iterator is feeding to the agent.
# Compare this representation of replay data
# to the collection of individual trajectories shown earlier.
# iterator.next()
에이전트 교육
훈련 루프 동안 두 가지 일이 발생해야 합니다.
- 환경에서 데이터 수집
- 해당 데이터를 사용하여 에이전트의 신경망 훈련
이 예에서는 정기적으로 정책을 평가하고 현재 점수를 인쇄합니다.
다음은 실행하는 데 ~5분 정도 걸립니다.
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step.
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
# Reset the environment.
time_step = train_py_env.reset()
# Create a driver to collect experience.
collect_driver = py_driver.PyDriver(
env,
py_tf_eager_policy.PyTFEagerPolicy(
agent.collect_policy, use_tf_function=True),
[rb_observer],
max_steps=collect_steps_per_iteration)
for _ in range(num_iterations):
# Collect a few steps and save to the replay buffer.
time_step, _ = collect_driver.run(time_step)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience).loss
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/util/dispatch.py:206: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. [reverb/cc/client.cc:163] Sampler and server are owned by the same process (15446) so Table uniform_table is accessed directly without gRPC. step = 200: loss = 27.080341339111328 step = 400: loss = 3.0314550399780273 step = 600: loss = 470.9187927246094 step = 800: loss = 548.7870483398438 step = 1000: loss = 4315.17578125 step = 1000: Average Return = 48.400001525878906 step = 1200: loss = 5297.24853515625 step = 1400: loss = 11601.296875 step = 1600: loss = 60482.578125 step = 1800: loss = 802764.8125 step = 2000: loss = 1689283.0 step = 2000: Average Return = 63.400001525878906 step = 2200: loss = 4928921.0 step = 2400: loss = 5508345.0 step = 2600: loss = 17888162.0 step = 2800: loss = 23993148.0 step = 3000: loss = 10192765.0 step = 3000: Average Return = 74.0999984741211 step = 3200: loss = 88318176.0 step = 3400: loss = 77485728.0 step = 3600: loss = 3236693504.0 step = 3800: loss = 102289840.0 step = 4000: loss = 168594496.0 step = 4000: Average Return = 73.5999984741211 step = 4200: loss = 348990528.0 step = 4400: loss = 101819664.0 step = 4600: loss = 136486208.0 step = 4800: loss = 133454864.0 step = 5000: loss = 592934784.0 step = 5000: Average Return = 71.5999984741211 step = 5200: loss = 216909120.0 step = 5400: loss = 181369648.0 step = 5600: loss = 600455680.0 step = 5800: loss = 551183744.0 step = 6000: loss = 368749824.0 step = 6000: Average Return = 83.5 step = 6200: loss = 1010418176.0 step = 6400: loss = 171257856.0 step = 6600: loss = 115424904.0 step = 6800: loss = 144941152.0 step = 7000: loss = 257932752.0 step = 7000: Average Return = 107.0 step = 7200: loss = 854109248.0 step = 7400: loss = 95970128.0 step = 7600: loss = 325583744.0 step = 7800: loss = 858134016.0 step = 8000: loss = 197960128.0 step = 8000: Average Return = 124.19999694824219 step = 8200: loss = 310187552.0 step = 8400: loss = 572293760.0 step = 8600: loss = 2338323456.0 step = 8800: loss = 384659392.0 step = 9000: loss = 676924544.0 step = 9000: Average Return = 200.0 step = 9200: loss = 946199168.0 step = 9400: loss = 605189504.0 step = 9600: loss = 768988928.0 step = 9800: loss = 508231776.0 step = 10000: loss = 526518016.0 step = 10000: Average Return = 200.0 step = 10200: loss = 1461528704.0 step = 10400: loss = 709822016.0 step = 10600: loss = 2770553344.0 step = 10800: loss = 496421504.0 step = 11000: loss = 1822116864.0 step = 11000: Average Return = 200.0 step = 11200: loss = 744854208.0 step = 11400: loss = 778800384.0 step = 11600: loss = 667049216.0 step = 11800: loss = 586587648.0 step = 12000: loss = 2586833920.0 step = 12000: Average Return = 200.0 step = 12200: loss = 1002041472.0 step = 12400: loss = 1526919552.0 step = 12600: loss = 1670877056.0 step = 12800: loss = 1857608704.0 step = 13000: loss = 1040727936.0 step = 13000: Average Return = 200.0 step = 13200: loss = 1807798656.0 step = 13400: loss = 1457996544.0 step = 13600: loss = 1322671616.0 step = 13800: loss = 22940983296.0 step = 14000: loss = 1556422912.0 step = 14000: Average Return = 200.0 step = 14200: loss = 2488473600.0 step = 14400: loss = 46558289920.0 step = 14600: loss = 1958968960.0 step = 14800: loss = 4677744640.0 step = 15000: loss = 1648418304.0 step = 15000: Average Return = 200.0 step = 15200: loss = 46132723712.0 step = 15400: loss = 2189093888.0 step = 15600: loss = 1204941056.0 step = 15800: loss = 1578462080.0 step = 16000: loss = 1695949312.0 step = 16000: Average Return = 200.0 step = 16200: loss = 19554553856.0 step = 16400: loss = 2857277184.0 step = 16600: loss = 5782225408.0 step = 16800: loss = 2294467072.0 step = 17000: loss = 2397877248.0 step = 17000: Average Return = 200.0 step = 17200: loss = 2910329088.0 step = 17400: loss = 6317301760.0 step = 17600: loss = 2733602048.0 step = 17800: loss = 32502740992.0 step = 18000: loss = 6295858688.0 step = 18000: Average Return = 200.0 step = 18200: loss = 2564860160.0 step = 18400: loss = 76450430976.0 step = 18600: loss = 6347636736.0 step = 18800: loss = 6258629632.0 step = 19000: loss = 8091572224.0 step = 19000: Average Return = 200.0 step = 19200: loss = 3860335616.0 step = 19400: loss = 3552561152.0 step = 19600: loss = 4175943424.0 step = 19800: loss = 5975838720.0 step = 20000: loss = 4709884928.0 step = 20000: Average Return = 200.0
심상
플롯
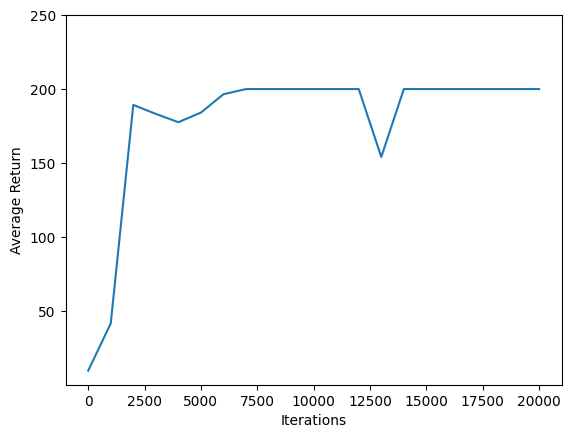
사용 matplotlib.pyplot 정책이 교육 과정 개선하는 방법을 도표로.
하나의 반복 Cartpole-v0 200 시간 단계로 구성되어 있습니다. 환경은의 보상을주는 +1 하나 개의 에피소드에 대한 최대의 수익은 200 차트 쇼가 최대쪽으로 훈련 중에 평가 될 때마다 증가 반환하므로, 각 단계에 대한 극 숙박을. (조금 불안정하고 매번 단조롭게 증가하지 않을 수 있습니다.)
iterations = range(0, num_iterations + 1, eval_interval)
plt.plot(iterations, returns)
plt.ylabel('Average Return')
plt.xlabel('Iterations')
plt.ylim(top=250)
(40.82000160217285, 250.0)
비디오
차트가 좋습니다. 그러나 더 흥미로운 것은 에이전트가 실제로 환경에서 작업을 수행하는 것을 보는 것입니다.
먼저 노트북에 동영상을 삽입하는 함수를 만듭니다.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
이제 에이전트와 함께 Cartpole 게임의 몇 가지 에피소드를 반복합니다. 기저 파이썬 환경합니다 (TensorFlow 환경 랩퍼 "내부"하나)을 제공 render() 환경 상태의 화상을 출력하는 방법. 이것들은 비디오로 수집될 수 있습니다.
def create_policy_eval_video(policy, filename, num_episodes=5, fps=30):
filename = filename + ".mp4"
with imageio.get_writer(filename, fps=fps) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
return embed_mp4(filename)
create_policy_eval_video(agent.policy, "trained-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x55d99fdf83c0] Warning: data is not aligned! This can lead to a speed loss
재미를 위해 훈련된 에이전트(위)를 무작위로 움직이는 에이전트와 비교하십시오. (역시 그렇지 않습니다.)
create_policy_eval_video(random_policy, "random-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned. [swscaler @ 0x55ffa7fe73c0] Warning: data is not aligned! This can lead to a speed loss