
कॉपीराइट 2021 टीएफ-एजेंट लेखक।
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
परिचय
रीइन्फोर्समेंट लर्निंग (आरएल) एक सामान्य ढांचा है जहां एजेंट एक ऐसे वातावरण में कार्रवाई करना सीखते हैं जिससे इनाम को अधिकतम किया जा सके। दो मुख्य घटक हैं पर्यावरण, जो हल की जाने वाली समस्या का प्रतिनिधित्व करता है, और एजेंट, जो लर्निंग एल्गोरिदम का प्रतिनिधित्व करता है।
एजेंट और पर्यावरण लगातार एक दूसरे के साथ बातचीत करते हैं। हर बार कदम पर, एजेंट अपनी नीति के आधार पर पर्यावरण पर कोई ऐसा कार्य करता \(\pi(a_t|s_t)\), जहां \(s_t\) पर्यावरण से वर्तमान अवलोकन है, और एक इनाम प्राप्त \(r_{t+1}\) और अगले अवलोकन \(s_{t+1}\) वातावरण से . लक्ष्य नीति में सुधार करना है ताकि पुरस्कारों के योग (वापसी) को अधिकतम किया जा सके।
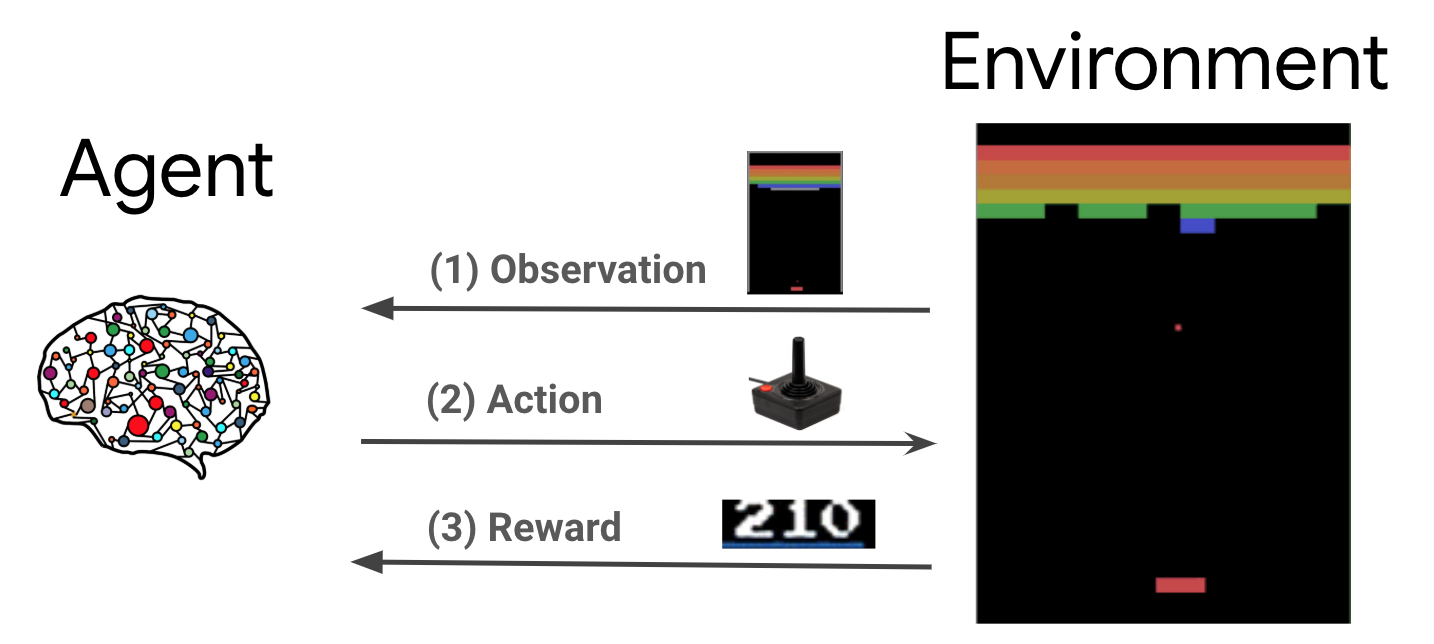
यह एक बहुत ही सामान्य ढांचा है और खेल, रोबोटिक्स आदि जैसे विभिन्न अनुक्रमिक निर्णय लेने की समस्याओं को मॉडल कर सकता है।
कार्टपोल पर्यावरण
Cartpole वातावरण सबसे प्रसिद्ध क्लासिक सुदृढीकरण सीखने समस्याओं में से एक (आर एल की "नमस्कार, दुनिया!") है। एक गाड़ी से एक खंभा जुड़ा हुआ है, जो एक घर्षण रहित ट्रैक के साथ आगे बढ़ सकता है। पोल सीधा शुरू होता है और लक्ष्य गाड़ी को नियंत्रित करके इसे गिरने से रोकना है।
- पर्यावरण से अवलोकन \(s_t\) स्थिति और गाड़ी के वेग, और कोण और ध्रुव का कोणीय वेग को दिखाने वाला 4D वेक्टर है।
- एजेंट 2 क्रियाओं में से एक लेने के द्वारा प्रणाली को नियंत्रित कर सकते \(a_t\): धक्का गाड़ी सही (+1) या छोड़ दिया (-1)।
- एक इनाम \(r_{t+1} = 1\) हर timestep कि ध्रुव ईमानदार रहता है के लिए प्रदान की जाती है। एपिसोड तब समाप्त होता है जब निम्न में से कोई एक सत्य होता है:
- कुछ कोण सीमा पर ध्रुव युक्तियाँ
- गाड़ी दुनिया के किनारों के बाहर चलती है
- 200 बार कदम गुजरते हैं।
एजेंट के लक्ष्य के लिए एक नीति सीखना है \(\pi(a_t|s_t)\) इतनी के रूप में एक प्रकरण में पुरस्कार की राशि को अधिकतम करने के \(\sum_{t=0}^{T} \gamma^t r_t\)। यहाँ \(\gamma\) में छूट कारक है \([0, 1]\) कि छूट भविष्य तत्काल पुरस्कार के सापेक्ष पुरस्कार। यह पैरामीटर हमें नीति पर ध्यान केंद्रित करने में मदद करता है, जिससे यह जल्दी से पुरस्कार प्राप्त करने के बारे में अधिक ध्यान रखता है।
डीक्यूएन एजेंट
DQN (दीप क्यू नेटवर्क) एल्गोरिथ्म 2015 में DeepMind द्वारा विकसित किया गया यह बड़े पैमाने पर सुदृढीकरण सीखने और गहरी तंत्रिका नेटवर्क संयोजन से अटारी खेल की एक विस्तृत श्रृंखला (अलौकिक स्तर पर कुछ) का समाधान करने में सक्षम था। एल्गोरिथ्म गहरी तंत्रिका नेटवर्क और नामक तकनीक अनुभव की पुनरावृत्ति के साथ क्यू-लर्निंग नामक एक क्लासिक आर एल एल्गोरिथ्म को बेहतर बना कर विकसित किया गया था।
क्यू-लर्निंग
क्यू-लर्निंग क्यू-फ़ंक्शन की धारणा पर आधारित है। एक नीति के क्यू समारोह (उर्फ राज्य कार्रवाई मूल्य समारोह) \(\pi\), \(Q^{\pi}(s, a)\), उपायों की उम्मीद वापसी या रियायती राशि राज्य से प्राप्त पुरस्कार की \(s\) कार्रवाई कर \(a\) पहली और नीति का पालन \(\pi\) उसके बाद। हम इष्टतम क्यू समारोह को परिभाषित \(Q^*(s, a)\) अधिकतम वापसी कि अवलोकन से शुरू प्राप्त किया जा सकता के रूप में \(s\), कार्रवाई करने \(a\) और उसके बाद इष्टतम नीति का पालन। इष्टतम क्यू समारोह का अनुसरण करता है निम्नलिखित बेल्लमान optimality समीकरण:
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
इसका मतलब है कि राज्य से अधिकतम लाभ \(s\) और कार्रवाई \(a\) तत्काल इनाम का योग है \(r\) और वापसी (द्वारा रियायती \(\gamma\)) प्रकरण के अंत तक उसके बाद इष्टतम नीति का पालन करके प्राप्त ( यानी, अगले राज्य से अधिकतम इनाम \(s'\))। उम्मीद दोनों तत्काल पुरस्कार के वितरण पर गणना की जाती है \(r\) और संभव अगले राज्यों \(s'\)।
क्यू-लर्निंग के पीछे मूल विचार एक सतत अद्यतन के रूप में बेल्लमान optimality समीकरण का उपयोग है \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\), और यह दिखाया जा सकता है कि इष्टतम को यह converges \(Q\)समारोह, यानी \(Q_i \rightarrow Q^*\) रूप \(i \rightarrow \infty\) (देखें DQN कागज )।
डीप क्यू-लर्निंग
सबसे समस्याओं के लिए, यह प्रतिनिधित्व करने के लिए अव्यावहारिक है \(Q\)के प्रत्येक संयोजन के मूल्यों से युक्त एक तालिका के रूप में समारोह \(s\) और \(a\)। इसके बजाय, हम इस तरह के मानकों के साथ एक तंत्रिका नेटवर्क के रूप में एक समारोह approximator प्रशिक्षित, \(\theta\), क्यू मूल्यों, यानी अनुमान लगाने के लिए \(Q(s, a; \theta) \approx Q^*(s, a)\)। यह हर कदम पर निम्न नुकसान को कम करने के द्वारा किया जा सकता है \(i\):
\(\begin{equation}L_i(\theta_i) = \mathbb{E}_{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) जहां \(y_i = r + \gamma \max_{a'} Q(s', a'; \theta_{i-1})\)
इधर, \(y_i\) टीडी (अस्थायी अंतर) लक्ष्य कहा जाता है, और \(y_i - Q\) टीडी त्रुटि कहा जाता है। \(\rho\) व्यवहार वितरण, संक्रमण से अधिक वितरण का प्रतिनिधित्व करता है \(\{s, a, r, s'\}\) पर्यावरण से एकत्र।
ध्यान दें कि पिछले यात्रा से मानकों \(\theta_{i-1}\) तय कर रहे हैं और अद्यतन नहीं। व्यवहार में हम पिछले पुनरावृत्ति के बजाय कुछ पुनरावृत्तियों से पहले नेटवर्क मापदंडों के एक स्नैपशॉट का उपयोग करते हैं। यह प्रतिलिपि लक्ष्य नेटवर्क कहा जाता है।
क्यू-लर्निंग एक ऑफ नीति एल्गोरिथ्म है कि लालची नीति के बारे में सीखता है \(a = \max_{a} Q(s, a; \theta)\) / वातावरण में अभिनय डेटा इकट्ठा करने के लिए एक अलग व्यवहार नीति का उपयोग करते समय। यह व्यवहार नीति आम तौर पर एक है \(\epsilon\)-greedy नीति है कि चयन संभावना के साथ लालची कार्रवाई \(1-\epsilon\) और संभावना के साथ एक यादृच्छिक कार्रवाई \(\epsilon\) राज्य कार्रवाई अंतरिक्ष का अच्छा कवरेज सुनिश्चित करने के लिए।
अनुभव फिर से खेलना
DQN हानि में पूर्ण अपेक्षा की गणना से बचने के लिए, हम स्टोकेस्टिक ग्रेडिएंट डिसेंट का उपयोग करके इसे कम कर सकते हैं। नुकसान अभी पिछले संक्रमण का उपयोग गणना की जाती है, तो \(\{s, a, r, s'\}\), इस मानक क्यू-लर्निंग को कम करता है।
अटारी डीक्यूएन काम ने नेटवर्क अपडेट को और अधिक स्थिर बनाने के लिए एक्सपीरियंस रिप्ले नामक एक तकनीक पेश की। डेटा संग्रह के लिए हर बार कदम पर, संक्रमण एक परिपत्र बफर पुनरावृत्ति बफर कहा जाता है के लिए जोड़ रहे हैं। फिर प्रशिक्षण के दौरान, नुकसान और इसकी ढाल की गणना करने के लिए केवल नवीनतम संक्रमण का उपयोग करने के बजाय, हम रीप्ले बफर से नमूना किए गए संक्रमणों के मिनी-बैच का उपयोग करके उनकी गणना करते हैं। इसके दो फायदे हैं: कई अद्यतनों में प्रत्येक संक्रमण का पुन: उपयोग करके बेहतर डेटा दक्षता, और बैच में असंबद्ध संक्रमणों का उपयोग करके बेहतर स्थिरता।
TF-Agents में कार्टपोल पर DQN
TF-Agents DQN एजेंट को प्रशिक्षित करने के लिए आवश्यक सभी घटक प्रदान करता है, जैसे स्वयं एजेंट, पर्यावरण, नीतियां, नेटवर्क, रीप्ले बफ़र्स, डेटा संग्रह लूप और मेट्रिक्स। इन घटकों को पायथन फ़ंक्शन या TensorFlow ग्राफ़ ऑप्स के रूप में कार्यान्वित किया जाता है, और हमारे पास उनके बीच कनवर्ट करने के लिए रैपर भी हैं। इसके अतिरिक्त, TF-Agents TensorFlow 2.0 मोड का समर्थन करता है, जो हमें TF को अनिवार्य मोड में उपयोग करने में सक्षम बनाता है।
इसके बाद, पर एक नज़र डालें TF-एजेंटों का उपयोग कर Cartpole पर्यावरण पर एक DQN एजेंट प्रशिक्षण के लिए ट्यूटोरियल ।