
حق چاپ 2021 نویسندگان TF-Agents.
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
معرفی
یادگیری تقویتی (RL) یک چارچوب کلی است که در آن عوامل یاد میگیرند تا اقداماتی را در یک محیط انجام دهند تا پاداش را به حداکثر برسانند. دو مؤلفه اصلی عبارتند از محیط که معرف مسئله ای است که باید حل شود و عاملی که نشان دهنده الگوریتم یادگیری است.
عامل و محیط به طور پیوسته با یکدیگر تعامل دارند. در هر مرحله زمان، عامل طول می کشد یک عمل بر محیط زیست بر اساس سیاست خود \(\pi(a_t|s_t)\)، که در آن \(s_t\) مشاهده در حال حاضر از محیط زیست است، و دریافت پاداش \(r_{t+1}\) و مشاهدات بعدی \(s_{t+1}\) از محیط . هدف بهبود خط مشی است تا مجموع پاداش ها (بازده) به حداکثر برسد.
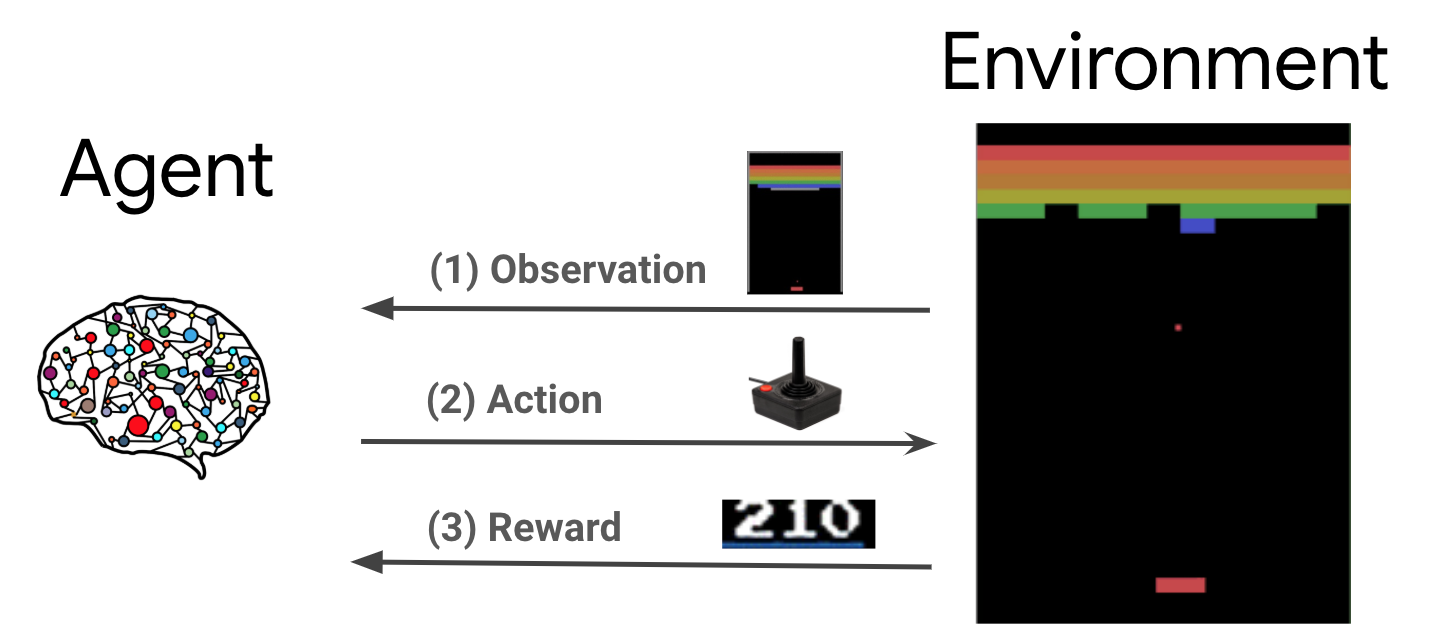
این یک چارچوب بسیار کلی است و می تواند انواع مختلفی از مشکلات تصمیم گیری متوالی مانند بازی ها، رباتیک و غیره را مدل کند.
محیط Cartpole
محیط Cartpole یکی از مشکلات یادگیری تقویتی کلاسیک شناخته شده ترین (از "سلام جهان!" از RL) است. یک قطب به یک گاری متصل است که می تواند در امتداد یک مسیر بدون اصطکاک حرکت کند. میله به صورت عمودی شروع می شود و هدف این است که با کنترل گاری از سقوط آن جلوگیری کنید.
- مشاهده از محیط \(s_t\) یک بردار 4D به نمایندگی از موقعیت و سرعت از سبد خرید، و زاویه و سرعت زاویه ای از قطب است.
- عامل می تواند سیستم با در نظر گرفتن یکی از 2 اقدامات کنترل \(a_t\): حق سبد خرید (1) یا چپ (-1) فشار.
- پاداش \(r_{t+1} = 1\) برای هر timestep که قطب راست قامت باقی مانده است ارائه شده است. این قسمت زمانی به پایان می رسد که یکی از موارد زیر درست باشد:
- نوک قطب بیش از حد زاویه است
- گاری در خارج از لبه های جهان حرکت می کند
- 200 گام زمانی می گذرد.
هدف از این عامل است که برای یادگیری یک سیاست \(\pi(a_t|s_t)\) به طوری که برای به حداکثر رساندن مجموع پاداش در یک قسمت \(\sum_{t=0}^{T} \gamma^t r_t\). در اینجا \(\gamma\) یک عامل تخفیف در است \([0, 1]\) که تخفیف آینده پاداش نسبت به پاداش های فوری. این پارامتر به ما کمک میکند خطمشی را متمرکز کنیم، و باعث میشود بیشتر به دریافت سریع پاداشها اهمیت دهد.
عامل DQN
DQN (عمیق Q-شبکه) الگوریتم های DeepMind در سال 2015. توسعه داده شد این است که قادر به حل یک طیف گسترده ای از بازی های آتاری (برخی به سطح مافوق انسانی) با ترکیب یادگیری تقویتی و شبکه های عصبی عمیق در مقیاس بود. الگوریتم با افزایش یک الگوریتم RL کلاسیک به نام Q-آموزش با شبکه های عصبی عمیق و یک تکنیک به نام تجربه پخش توسعه داده شد.
Q-Learning
Q-Learning مبتنی بر مفهوم تابع Q است. پرسش تابع (با نام مستعار تابع ارزش حالت و عمل) از یک سیاست \(\pi\)، \(Q^{\pi}(s, a)\)، اقدامات بازده مورد انتظار و یا مبلغ تخفیف از پاداش به دست آمده از دولت \(s\) با اقدام \(a\) اول و زیر سیاست \(\pi\) پس از آن. بهینه Q-تابع تعریف می کنیم \(Q^*(s, a)\) به عنوان بازگشت حداکثر است که می تواند به دست آمده با شروع از مشاهده \(s\)، اقدام \(a\) و زیر سیاست مطلوب پس از آن. بهینه Q-تابع اطاعت معادله بهینه بلمن زیر است:
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
این بدان معناست که حداکثر بازگشت از دولت \(s\) و عمل \(a\) از مجموع پاداش فوری است \(r\) و بازگشت (با تخفیف های \(\gamma\)) به دست آمده توسط زیر سیاست مطلوب پس از آن تا پایان قسمت ( به عنوان مثال، حداکثر پاداش از دولت بعدی \(s'\)). انتظار می رود هر دو بر سر توزیع پاداش های فوری محاسبه \(r\) و کشورهای بعدی ممکن \(s'\).
ایده اصلی Q-یادگیری به استفاده از معادله بهینه بلمن به عنوان یک به روز رسانی تکراری \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\)، و می توان آن نشان داده شده است که این همگرایی به مطلوب \(Q\)تابع، یعنی \(Q_i \rightarrow Q^*\) عنوان \(i \rightarrow \infty\) (نگاه کنید به مقاله DQN ).
Deep Q-Learning
برای بسیاری از مشکلات، غیر عملی است برای نشان دادن \(Q\)تابع به عنوان یک جدول حاوی مقادیر برای هر ترکیبی از \(s\) و \(a\). در عوض، ما آموزش approximator تابع، مانند یک شبکه عصبی با پارامترهای \(\theta\)، به منظور برآورد Q-ارزش ها، به عنوان مثال \(Q(s, a; \theta) \approx Q^*(s, a)\). این می تواند با به حداقل رساندن از دست دادن زیر در هر مرحله انجام \(i\):
\(\begin{equation}L_i(\theta_i) = \mathbb{E}_{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) که در آن \(y_i = r + \gamma \max_{a'} Q(s', a'; \theta_{i-1})\)
در اینجا، \(y_i\) نامیده می شود TD (تفاوت زمانی) هدف، و \(y_i - Q\) است خطا TD نامیده می شود. \(\rho\) نشان دهنده توزیع رفتار، توزیع بیش از انتقال \(\{s, a, r, s'\}\) جمع آوری شده از محیط زیست است.
توجه داشته باشید که از پارامترهای تکرار قبلی \(\theta_{i-1}\) ثابت و به روز نیست. در عمل ما به جای آخرین تکرار از یک عکس فوری از پارامترهای شبکه از چند تکرار قبل استفاده می کنیم. این نسخه به نام شبکه مورد نظر است.
Q-آموزش الگوریتم خارج از سیاست است که می آموزد درباره سیاست حریص است \(a = \max_{a} Q(s, a; \theta)\) در حالی که با استفاده از یک سیاست رفتار متفاوت برای اقدام در محیط زیست / جمع آوری داده ها. این سیاست رفتار است که معمولا یک \(\epsilon\)سیاست -greedy که انتخاب عمل حریص با احتمال \(1-\epsilon\) و یک عمل تصادفی با احتمال \(\epsilon\) برای اطمینان از پوشش خوبی از فضای حالت و عمل.
تکرار را تجربه کنید
برای جلوگیری از محاسبه انتظارات کامل در از دست دادن DQN، میتوانیم آن را با استفاده از نزول گرادیان تصادفی به حداقل برسانیم. اگر از دست دادن فقط با استفاده از آخرین گذار محاسبه شده است \(\{s, a, r, s'\}\)، این کاهش به استاندارد Q-آموزش.
کار Atari DQN تکنیکی به نام Experience Replay را معرفی کرد تا بهروزرسانیهای شبکه پایدارتر شود. در هر مرحله زمانی از جمع آوری داده ها، انتقال به یک بافر مدور به نام بافر پخش اضافه شده است. سپس در طول آموزش، بهجای استفاده از آخرین انتقال برای محاسبه ضرر و گرادیان آن، آنها را با استفاده از یک دسته کوچک از انتقالهای نمونهبرداری شده از بافر پخش مجدد محاسبه میکنیم. این دو مزیت دارد: کارایی داده بهتر با استفاده مجدد از هر انتقال در بسیاری از بهروزرسانیها، و پایداری بهتر با استفاده از انتقالهای نامرتبط در یک دسته.
DQN در Cartpole در TF-Agents
TF-Agents تمام اجزای لازم برای آموزش یک عامل DQN را فراهم می کند، مانند خود عامل، محیط، سیاست ها، شبکه ها، بافرهای پخش مجدد، حلقه های جمع آوری داده ها و معیارها. این کامپوننتها بهعنوان توابع پایتون یا عملیات گراف TensorFlow پیادهسازی میشوند، و ما همچنین wrapperهایی برای تبدیل بین آنها داریم. علاوه بر این، TF-Agents از حالت TensorFlow 2.0 پشتیبانی می کند که ما را قادر می سازد از TF در حالت امری استفاده کنیم.
بعد، نگاهی به در آموزش برای آموزش یک عامل DQN بر محیط زیست با استفاده از Cartpole TF-نمایندگی .