
Copyright 2018 The TF-Agents Authors.
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
소개
강화 학습(RL)은 에이전트가 보상을 극대화하기 위해 환경에서 행동을 취하는 방법을 배우는 일반적인 프레임워크입니다. 두 가지 주요 구성 요소는 해결해야 할 문제를 나타내는 환경과 학습 알고리즘을 나타내는 에이전트입니다.
에이전트와 환경은 지속해서 상호 작용합니다. 각 타임스텝에서 에이전트는 정책 \(\pi(a_t|s_t)\)를 기반으로 환경에 대한 행동을 취합니다. \(s_t\)는 환경에서 얻은 현재 관측 값이며 환경으로부터 보상 \(r_{t+1}\) 및 다음 관측 값 \(s_{t+1}\)을 받습니다. 목표는 보상의 합계(이익)이 최대가 되도록 정책을 개선하는 것입니다.
참고: 환경의 state와 에이전트가 볼 수 있는 환경 state의 일부인 observation을 구분하는 것이 중요합니다. 예를 들어, 포커 게임에서 환경 상태는 모든 플레이어에 속한 카드와 커뮤니티 카드로 구성되지만, 에이전트는 자신의 카드와 몇 개의 커뮤니티 카드만 관찰할 수 있습니다. 대부분의 문헌에서 이들 용어는 같은 의미로 사용되며, 관측 값은 \(s\)로 표시됩니다.
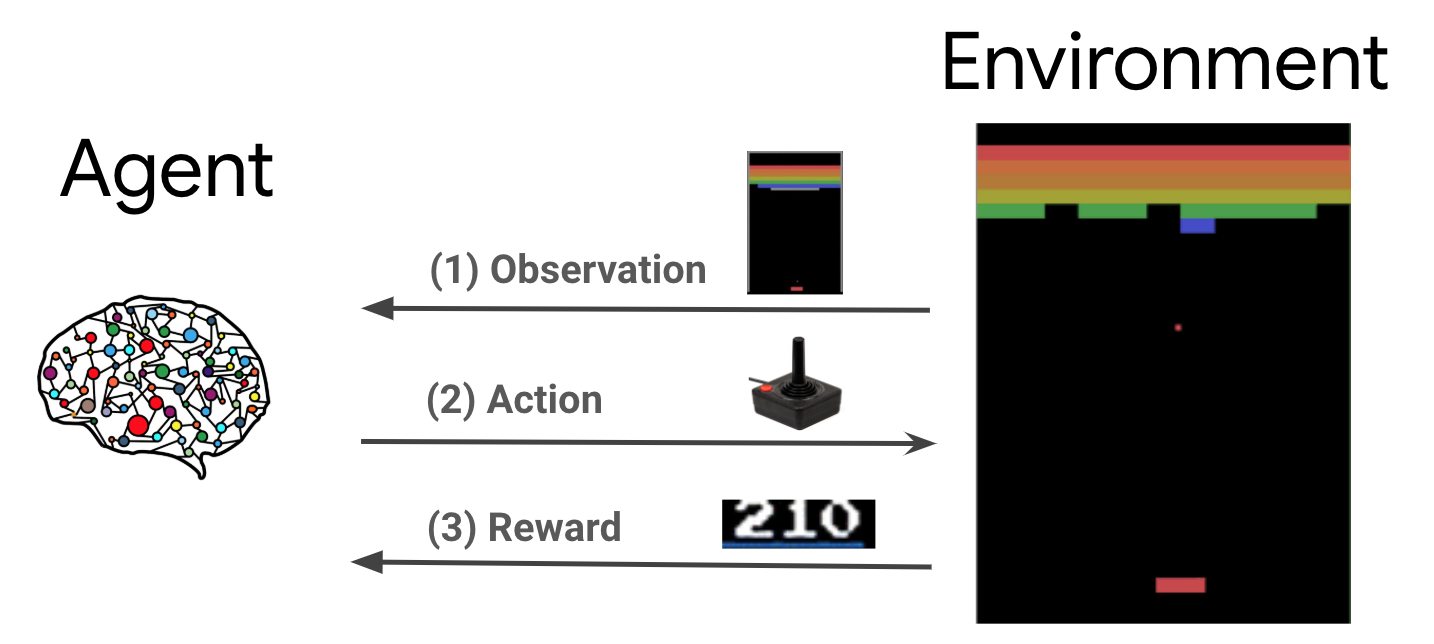
다음은 매우 일반적인 프레임워크이며 게임, 로봇 공학 등과 같은 다양한 순차적 의사 결정 문제를 모델링할 수 있습니다.
Cartpole 환경
Cartpole 환경은 가장 잘 알려진 고전적인 강화 학습 문제 중 하나입니다 (RL의 "Hello, World!" ). 카트에 막대가 부착되어 마찰이 없는 트랙을 따라 움직일 수 있습니다. 막대는 똑바로 선 채로 시작하고, 목표는 카트를 제어하여 막대가 넘어지지 않도록 하는 것입니다.
- 환경 \(s_t\)의 관측 값은 카트의 위치 및 속도, 막대의 각도 및 각속도를 나타내는 4D 벡터입니다.
- 에이전트는 두 가지 행동 \(a_t\) 중 하나를 취하여 시스템을 제어할 수 있습니다. 카트를 오른쪽 (+1) 또는 왼쪽 (-1)으로 밉니다.
- 막대가 똑바로 유지되는 모든 타임스텝 동안 보상 \(r_{t+1} = 1\)가 제공됩니다. 다음 중 하나에 해당하면 에피소드가 종료됩니다.
- 일부 각도 제한을 넘어가면 막대가 쓰러집니다.
- 카트가 가장자리 밖으로 움직입니다.
- 200개 타임스텝이 경과합니다.
에이전트의 목표는 에피소드 \(\sum_{t=0}^{T} \gamma^t r_t\)에서 보상의 합계가 최대가 되도록 하기 위해 정책 \(\pi(a_t|s_t)\)을 학습하는 것입니다. 여기서 \(\gamma\)는 \([0, 1]\)의 할인 요소로, 즉각적인 보상에 대해 미래 보상을 할인합니다. 이 매개변수를 통해 정책에 집중하여 보상을 신속하게 얻는 데 더 집중할 수 있습니다.
DQN 에이전트
DQN(Deep Q-Network) 알고리즘은 2015년 DeepMind에서 개발했습니다. 강화 학습과 심층 신경망을 대규모로 결합하여 광범위한 Atari 게임(일부 수퍼휴먼 수준)을 해결할 수 있었습니다. 이 알고리즘은 심층 신경망을 사용한 Q-Learning이라는 고전적인 RL 알고리즘과 경험 재현(experience replay)이라는 기법을 향상하여 개발되었습니다.
Q-Learning
Q-Learning은 Q-function의 개념을 기반으로 합니다. 정책 \(\pi\), \(Q^{\pi}(s, a)\)의 Q-function(일명 state-action value function)는 먼저 행동 \(a\)를 취한 후에 정책 \(\pi\)을 따름으로써 상태 \(s\)로부터 얻은 예상 이익 또는 보상의 할인된 합계를 측정합니다. 최적의 Q-function \(Q^*(s, a)\)를 관찰 값 \(s\)부터 시작하여 행동 \(a\)를 취하고 그 이후의 최적 정책에 따름으로써 얻을 수 있는 최대 이익으로 정의합니다. 최적의 Q-function은 다음 Bellman optimality 수식을 따릅니다.
\(\begin{equation}Q^\ast(s, a) = \mathbb{E}[ r + \gamma \max_{a'} Q^\ast(s', a') ]\end{equation}\)
상태 \(s\)와 행동 \(a\)에서의 최대 이익은 즉각적인 보상 \(r\)과 에피소드가 끝날 때까지 최적 정책을 따름으로써 얻은 이익(\(\gamma\) 만큼 할인됨)의 합계입니다(즉, 다음 상태 \(s'\)의 최대 보상). 즉각적인 보상 \(r\)과 가능한 다음 상태 \(s'\)의 분산에 대해 기대치가 계산됩니다.
Q-Learning의 기본 개념은 Bellman optimality 수식을 반복 업데이트 \(Q_{i+1}(s, a) \leftarrow \mathbb{E}\left[ r + \gamma \max_{a'} Q_{i}(s', a')\right]\)로 사용하는 것이며, 최적의 \(Q\)-function, 즉, \(i \rightarrow \infty\)로서 최적 \(Q_i \rightarrow Q^*\)로 수렴한다는 것을 알 수 있습니다(DQN 논문을 참조하세요).
Deep Q-Learning
대부분의 문제에서 \(Q\)-function을 \(s\)와 \(a\)의 각 조합에 대한 값을 포함하는 표로 나타내는 것은 비현실적입니다. 대신, 매개변수 \(\theta\)를 가진 신경망과 같은 함수 근사기를 훈련하여 Q-values, 즉 \(Q(s, a; \theta) \approx Q^*(s, a)\)를 추정합니다. 각 단계 \(i\)에서 다음 손실을 최소화하면 됩니다.
\(\begin{equation}L_i(\theta_i) = \mathbb{E}*{s, a, r, s'\sim \rho(.)} \left[ (y_i - Q(s, a; \theta_i))^2 \right]\end{equation}\) where \(y_i = r + \gamma \max*{a'} Q(s', a'; \theta_{i-1})\)
여기서 \(y_i \)를 TD(시간 차이) 대상이라고 하고, \(y_i-Q \)를 TD 오류라고 합니다. \(\rho\)는 행동 분포, 환경으로부터 수집된 전환 \({s, a, r, s'}\)에 대한 분포를 나타냅니다.
이전 반복 \(\theta_ {i-1}\)의 매개변수는 고정되어 업데이트되지 않습니다. 실제로 마지막 반복 대신 몇 번의 반복 이전의 네트워크 매개변수의 스냅샷을 사용합니다. 이 사본을 대상 네트워크라고 합니다.
Q-Learning은 환경/수집 데이터에서 행동에 대한 다른 행동 정책을 사용하면서 최대 정책(greedy policy) \(a = \max_{a} Q(s, a; \ theta)\)에 대해 학습하는 정책 외 알고리즘입니다. 이 행동 정책은 일반적으로 확률 \(1-\epsilon\)인 최대 행동(greedy action)과 확률 \(\epsilon\)인 무작위 행동을 선택하여 상태-행동 공간을 잘 처리하는 \(\epsilon\)-greedy 정책입니다.
경험 재현
DQN 손실에서 전체 기대치를 계산하지 않기 위해 확률적 경사 하강을 사용하여 전체 기대치를 최소화할 수 있습니다. 마지막 전환 \({s, a, r, s'}\)만 사용하여 손실을 계산하면 표준 Q-Learning으로 감소합니다.
Atari DQN에는 네트워크 업데이트를 보다 안정적으로 만들기 위해 Experience Replay라는 기법이 도입되었습니다. 데이터 수집의 각 타임스텝에서 전환이 재현 버퍼라는 원형 버퍼에 추가됩니다. 그런 다음, 훈련 중에 최신 전환만 사용하여 손실과 그래디언트를 계산하는 대신 재현 버퍼에서 샘플링된 전환의 미니 배치를 사용하여 계산합니다. 여기에는 두 가지 장점이 있습니다. 즉, 다수의 업데이트에서 각 전환을 재사용하여 데이터 효율성을 높이고 배치에서 관련 없는 전환을 사용하여 안정성을 향상하는 것입니다.
TF-Agents에서 Cartpole의 DQN
TF-Agents는 에이전트 자체, 환경, 정책, 네트워크, 재현 버퍼, 데이터 수집 루프 및 메트릭과 같이 DQN 에이전트를 훈련하는 데 필요한 모든 구성 요소를 제공합니다. 이들 구성 요소는 Python 함수 또는 TensorFlow 그래프 ops로 구현되며, 이들 사이를 변환하기 위한 래퍼도 있습니다. 또한, TF-Agents는 TensorFlow 2.0 모드를 지원하므로 명령 모드에서 TF를 사용할 수 있습니다.
다음으로, TF-Agents를 사용하여 Cartpole 환경에서 DQN 에이전트를 훈련하기 위한 튜토리얼을 읽어 보세요.