
 Xem nguồn trên GitHub
Xem nguồn trên GitHubTổng quat
Hướng dẫn này trình bày việc sử dụng Tỷ lệ học theo chu kỳ từ gói Addons.
Tỷ lệ học tập theo chu kỳ
Nó đã được chứng minh là có lợi khi điều chỉnh tốc độ học tập khi tiến trình đào tạo đối với mạng nơ-ron. Nó có nhiều lợi ích khác nhau, từ việc khôi phục điểm yên ngựa đến ngăn ngừa các bất ổn số có thể phát sinh trong quá trình nhân giống ngược. Nhưng làm thế nào người ta biết cần điều chỉnh bao nhiêu đối với một dấu thời gian đào tạo cụ thể? Vào năm 2015, Leslie Smith nhận thấy rằng bạn muốn tăng tỷ lệ học tập để vượt qua cảnh mất mát nhanh hơn nhưng bạn cũng muốn giảm tỷ lệ học tập khi tiếp cận hội tụ. Để hiện thực hóa ý tưởng này, ông đề nghị Cyclical Learning giá (CLR), nơi bạn sẽ điều chỉnh tỷ lệ học đối với các chu kỳ của một hàm với. Đối với một cuộc biểu tình thị giác, bạn có thể kiểm tra blog này . CLR hiện có sẵn dưới dạng API TensorFlow. Để biết thêm chi tiết, hãy kiểm tra các giấy gốc ở đây .
Cài đặt
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
Tải và chuẩn bị tập dữ liệu
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
Xác định siêu tham số
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
Xác định các tiện ích xây dựng mô hình và đào tạo mô hình
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
Vì lợi ích của khả năng tái lập, các trọng số của mô hình ban đầu được xếp theo thứ tự mà bạn sẽ sử dụng để tiến hành các thí nghiệm của chúng tôi.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
Đào tạo một mô hình không có CLR
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
Xác định lịch CLR
Các tfa.optimizers.CyclicalLearningRate mô-đun trả về một lịch trình trực tiếp có thể được chuyển đến một ưu. Lịch trình thực hiện một bước khi đầu vào và đầu ra của nó một giá trị được tính bằng công thức CLR như được trình bày trong bài báo.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
Ở đây, bạn chỉ định cận dưới và trên của tỷ lệ học và lịch trình sẽ dao động ở giữa phạm vi đó ([1e-4, 1e-2] trong trường hợp này). scale_fn được sử dụng để xác định các chức năng đó sẽ mở rộng quy mô và mở rộng xuống tỷ lệ học trong vòng một chu kỳ nhất định. step_size xác định thời gian của một chu trình đơn. Một step_size của 2 phương tiện bạn cần tổng cộng 4 lần lặp để hoàn thành một chu kỳ. Giá trị đề nghị cho step_size là như sau:
factor * steps_per_epoch nơi yếu tố dối trá trong [2, 8] phạm vi.
Trong cùng một giấy CLR , Leslie cũng trình bày một cách đơn giản và phương pháp đơn giản để lựa chọn giới hạn đối với tỷ lệ học. Bạn cũng được khuyến khích để kiểm tra nó ra. Bài viết trên blog này cung cấp một giới thiệu tốt đẹp để phương pháp này.
Dưới đây, bạn hình dung như thế nào clr vẻ lịch thích.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
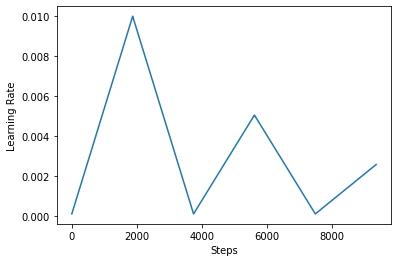
Để hình dung rõ hơn tác dụng của CLR, bạn có thể vẽ lịch trình với số lượng bước tăng lên.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
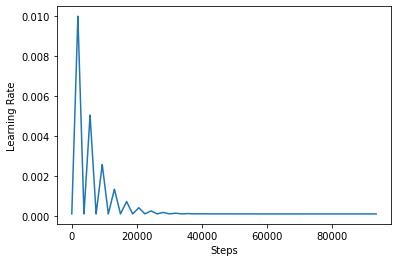
Các chức năng bạn đang sử dụng trong hướng dẫn này được gọi là triangular2 phương pháp trong các giấy CLR. Có hai chức năng khác có được khám phá cụ thể là triangular và exp (viết tắt của mũ).
Đào tạo người mẫu với CLR
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
Như mong đợi, sự mất mát bắt đầu cao hơn bình thường và sau đó nó ổn định khi các chu kỳ tiến triển. Bạn có thể xác nhận điều này một cách trực quan với các lô bên dưới.
Hình dung các khoản lỗ
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
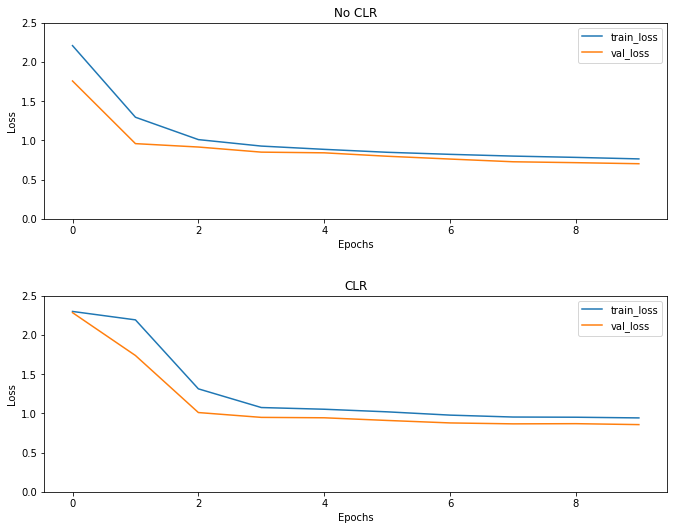
Mặc dù ví dụ đồ chơi này, bạn không thấy những tác động của CLR nhiều nhưng lưu ý rằng nó là một trong những thành phần chính đằng sau siêu tụ và có thể có một tác động thực sự tốt khi huấn luyện trong môi trường quy mô lớn.