
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
บทช่วยสอนนี้สาธิตการใช้ Cyclical Learning Rate จากแพ็คเกจ Addons
อัตราการเรียนรู้วัฏจักร
พบว่าการปรับอัตราการเรียนรู้ในขณะที่การฝึกอบรมดำเนินไปสำหรับโครงข่ายประสาทเทียมนั้นมีประโยชน์ มีประโยชน์มากมายตั้งแต่การกู้คืนจุดอานไปจนถึงการป้องกันความไม่แน่นอนของตัวเลขที่อาจเกิดขึ้นระหว่างการขยายพันธุ์ด้านหลัง แต่เราจะทราบได้อย่างไรว่าควรปรับเปลี่ยนตามการประทับเวลาการฝึกอบรมโดยเฉพาะมากน้อยเพียงใด ในปี 2015 เลสลี่ สมิธสังเกตเห็นว่าคุณต้องการเพิ่มอัตราการเรียนรู้เพื่อสำรวจให้เร็วขึ้นผ่านแนวการสูญเสีย แต่คุณยังต้องการลดอัตราการเรียนรู้เมื่อเข้าใกล้การบรรจบกัน ที่จะตระหนักถึงความคิดนี้เขาเสนอ การเรียนรู้ราคาวัฏจักร (CLR) ซึ่งคุณจะปรับอัตราการเรียนรู้เกี่ยวกับวงจรของฟังก์ชัน สำหรับการสาธิตภาพคุณสามารถตรวจสอบ บล็อกนี้ CLR พร้อมใช้งานในรูปแบบ TensorFlow API แล้ว สำหรับรายละเอียดเพิ่มเติมตรวจสอบกระดาษต้นฉบับ ที่นี่
ติดตั้ง
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
โหลดและเตรียมชุดข้อมูล
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
กำหนดไฮเปอร์พารามิเตอร์
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
กำหนดรูปแบบการสร้างแบบจำลองและยูทิลิตี้การฝึกอบรมแบบจำลอง
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
เพื่อประโยชน์ในการทำซ้ำ น้ำหนักของแบบจำลองเริ่มต้นจะถูกจัดลำดับซึ่งคุณจะใช้เพื่อดำเนินการทดลองของเรา
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
ฝึกโมเดลที่ไม่มี CLR
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
กำหนดตารางเวลา CLR
tfa.optimizers.CyclicalLearningRate โมดูลกลับกำหนดการโดยตรงที่สามารถส่งผ่านไปยังเพิ่มประสิทธิภาพ กำหนดการใช้เวลาขั้นตอนหนึ่งในการป้อนข้อมูลและส่งออกค่าที่คำนวณโดยใช้สูตร CLR ตามที่ระบุในกระดาษ
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
ที่นี่คุณระบุขอบเขตบนและล่างของอัตราการเรียนรู้และช่วงเวลาที่จะสั่นในระหว่างช่วงนั้น ([1E-4, 1e-2] ในกรณีนี้) scale_fn ใช้เพื่อกำหนดฟังก์ชั่นที่จะไต่ขึ้นและขนาดลงอัตราการเรียนรู้ภายในรอบที่กำหนด step_size กำหนดระยะเวลาของรอบเดียว step_size 2 หมายความว่าคุณต้องรวม 4 ซ้ำครบรอบหนึ่งรอบ ค่าที่แนะนำสำหรับ step_size เป็นดังนี้:
factor * steps_per_epoch ที่ปัจจัยที่อยู่ใน [2, 8] ช่วง
ในเดียวกัน กระดาษ CLR เลสลี่ยังนำเสนอวิธีการที่เรียบง่ายและสง่างามในการเลือกขอบเขตสำหรับอัตราการเรียนรู้ ขอแนะนำให้คุณลองดูเช่นกัน บล็อกโพสต์นี้ ยังมีการแนะนำที่ดีกับวิธีการ
ด้านล่างนี้คุณเห็นภาพว่า clr กำหนดการดูเหมือนว่า
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
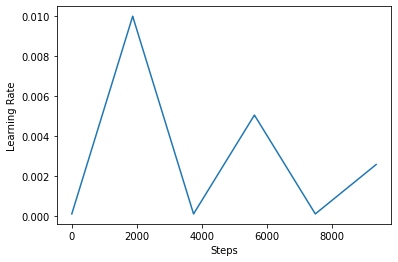
เพื่อให้เห็นภาพผลของ CLR ได้ดีขึ้น คุณสามารถพล็อตกำหนดการด้วยจำนวนขั้นตอนที่เพิ่มขึ้นได้
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
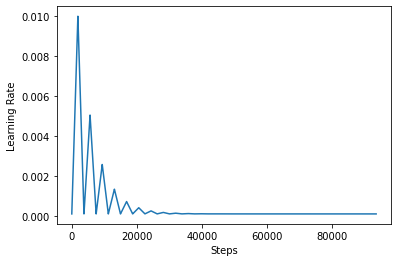
ฟังก์ชั่นที่คุณใช้ในการกวดวิชานี้จะเรียกว่า triangular2 วิธีการในการ CLR กระดาษ มีสองฟังก์ชั่นอื่น ๆ ที่มีการสำรวจคือเป็น triangular และ exp (ย่อมาชี้แจง)
ฝึกโมเดลด้วย CLR
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
ตามที่คาดไว้การสูญเสียจะเริ่มสูงกว่าปกติและจากนั้นจะทรงตัวเมื่อวัฏจักรดำเนินไป คุณสามารถยืนยันสิ่งนี้ได้ด้วยแผนภาพด้านล่าง
เห็นภาพความสูญเสีย
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
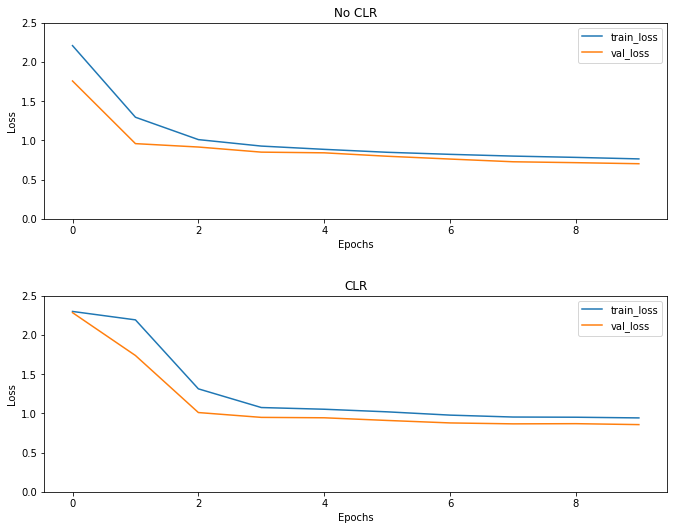
แม้ว่าเช่นของเล่นนี้คุณไม่ได้เห็นผลของ CLR มาก แต่จะสังเกตเห็นว่ามันเป็นหนึ่งในส่วนผสมหลักที่อยู่เบื้องหลัง ซูเปอร์ Convergence และสามารถมี ผลกระทบที่ดีจริงๆ เมื่อการฝึกอบรมในการตั้งค่าขนาดใหญ่