
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Panoramica
Questo tutorial dimostra l'uso di Cyclical Learning Rate dal pacchetto Addons.
Tassi di apprendimento ciclici
È stato dimostrato che è utile regolare il tasso di apprendimento man mano che l'addestramento procede per una rete neurale. Ha molteplici vantaggi che vanno dal ripristino del punto di sella alla prevenzione delle instabilità numeriche che possono sorgere durante la retropropagazione. Ma come si fa a sapere quanto adeguarsi rispetto a un particolare timestamp di allenamento? Nel 2015, Leslie Smith ha notato che avresti voluto aumentare il tasso di apprendimento per attraversare più velocemente il panorama delle perdite, ma avresti anche voluto ridurre il tasso di apprendimento quando ti avvicini alla convergenza. Per realizzare questa idea, ha proposto ciclica Learning Tariffe (CLR) in cui si desidera regolare il tasso di apprendimento rispetto ai cicli di una funzione. Per una dimostrazione visiva, è possibile controllare questo blog . CLR è ora disponibile come API TensorFlow. Per ulteriori dettagli, controllare la carta originale qui .
Impostare
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
Carica e prepara il set di dati
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
Definire iperparametri
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
Definire le utilità di creazione e addestramento del modello
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
Nell'interesse della riproducibilità, vengono serializzati i pesi del modello iniziale che utilizzerai per condurre i nostri esperimenti.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
Addestra una modella senza CLR
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
Definisci la pianificazione CLR
Il tfa.optimizers.CyclicalLearningRate modulo di ritorno una pianificazione diretta che può essere passato ad un ottimizzatore. La pianificazione esegue un passaggio come input e restituisce un valore calcolato utilizzando la formula CLR come illustrato nel documento.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
Qui, si specificano i limiti inferiore e superiore del tasso di apprendimento e il programma oscillerà tra tale intervallo ([1e-4, 1e-2] in questo caso). scale_fn viene utilizzato per definire la funzione che scalare e ridimensionare il tasso di apprendimento all'interno di un dato ciclo. step_size definisce la durata di un singolo ciclo. Uno step_size di 2 significa che è necessario un totale di 4 iterazioni per completare un ciclo. Il valore consigliato per step_size è la seguente:
factor * steps_per_epoch dove si trova all'interno del fattore [2, 8] gamma.
Nello stesso documento CLR , Leslie ha anche presentato una semplice ed elegante metodo per scegliere i limiti per tasso di apprendimento. Sei incoraggiato a dare un'occhiata anche tu. Questo post del blog fornisce una bella introduzione al metodo.
Qui di seguito, a visualizzare come i clr sguardi di pianificazione piace.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
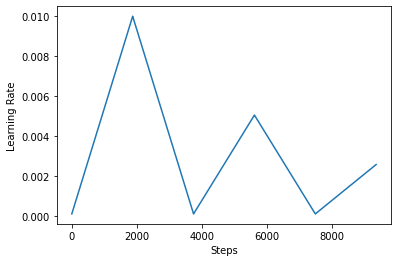
Per visualizzare meglio l'effetto di CLR, è possibile tracciare la pianificazione con un numero maggiore di passaggi.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
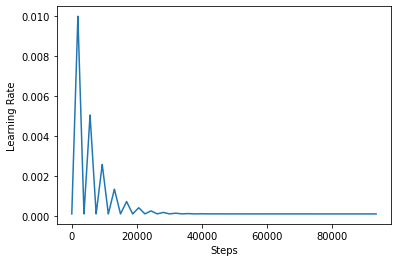
La funzione si utilizza in questo tutorial si riferisce a come il triangular2 metodo nel documento CLR. Ci sono altre due funzioni non sono state esplorate cioè triangular e exp (abbreviazione di esponenziale).
Addestra una modella con CLR
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
Come previsto, la perdita inizia più in alto del solito e poi si stabilizza con l'avanzare dei cicli. Puoi confermarlo visivamente con i grafici sottostanti.
Visualizza le perdite
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
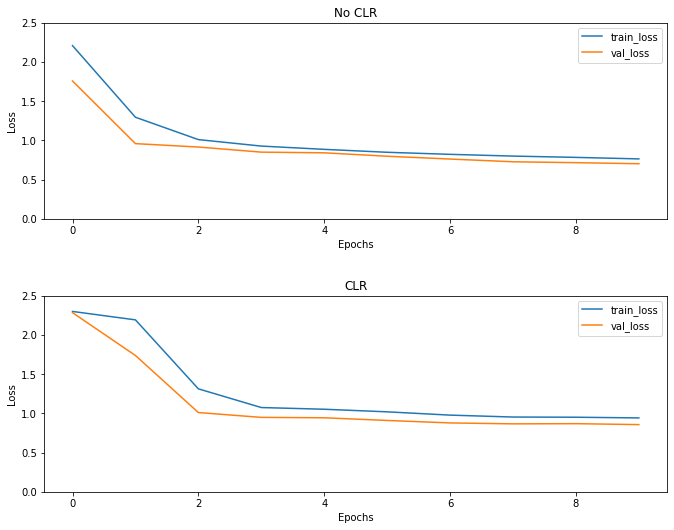
Anche se per questo esempio giocattolo, non hai visto gli effetti del CLR molto, ma va notato che è uno degli ingredienti principali dietro Super Convergenza e può avere un davvero un buon impatto quando ci si allena in ambienti di grandi dimensioni.