
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
این آموزش استفاده از نرخ یادگیری چرخه ای را از بسته Addons نشان می دهد.
نرخ یادگیری چرخه ای
نشان داده شده است که تنظیم نرخ یادگیری با پیشرفت آموزش برای یک شبکه عصبی مفید است. مزایای متعددی دارد، از بازیابی نقطه زینی گرفته تا جلوگیری از ناپایداری های عددی که ممکن است در طول انتشار پس از انتشار به وجود آیند. اما چگونه می توان فهمید که چقدر باید با توجه به یک زمان آموزشی خاص تنظیم شود؟ در سال 2015، لزلی اسمیت متوجه شد که شما می خواهید نرخ یادگیری را افزایش دهید تا سریعتر از چشم انداز ضرر عبور کنید، اما همچنین می خواهید نرخ یادگیری را هنگام نزدیک شدن به همگرایی کاهش دهید. برای تحقق این ایده، به او پیشنهاد نرخ یادگیری ادواری (CLR) که در آن شما می توانید نرخ یادگیری با توجه به چرخه از یک تابع را تنظیم کنید. برای یک تظاهرات بصری، شما می توانید از این وبلاگ . CLR اکنون به عنوان یک API TensorFlow در دسترس است. برای جزئیات بیشتر، لطفا مقاله اصلی در اینجا .
برپایی
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
مجموعه داده را بارگیری و آماده کنید
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
فراپارامترها را تعریف کنید
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
ساخت مدل و ابزارهای آموزشی مدل را تعریف کنید
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
بهمنظور تکرارپذیری، وزنهای مدل اولیه سریالسازی شدهاند که شما از آنها برای انجام آزمایشهای ما استفاده خواهید کرد.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
یک مدل بدون CLR آموزش دهید
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
برنامه CLR را تعریف کنید
tfa.optimizers.CyclicalLearningRate ماژول یک برنامه مستقیم که می تواند به بهینه ساز تصویب بازگشت. برنامه یک مرحله را به عنوان ورودی خود می گیرد و مقداری را که با استفاده از فرمول CLR محاسبه می شود، همانطور که در مقاله ارائه شده است، خروجی می دهد.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
در اینجا، شما از مرزهای بالا و پایین از نرخ یادگیری را مشخص و برنامه در بین آن محدوده نوسان ([1E-4، 1E-2] در این مورد). scale_fn استفاده شده است برای تعریف تابع که مقیاس و مقیاس پایین نرخ یادگیری در چرخه داده شود. step_size مدت زمان یک سیکل است تعریف می کند. step_size از 2 معنی است که شما نیاز به یک مجموع از 4 تکرار برای تکمیل یک چرخه. ارزش توصیه می شود برای step_size شرح زیر است:
factor * steps_per_epoch که در آن دروغ عامل در [2، 8] محدوده.
در همان مقاله CLR ، لسلی نیز ارائه ساده و روش زیبا برای انتخاب از مرزهای برای نرخ یادگیری است. شما تشویق می شوید که آن را نیز بررسی کنید. این وبلاگ یک مقدمه خوب به روش فراهم می کند.
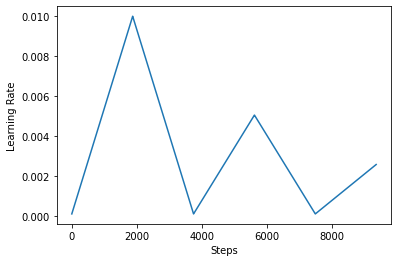
در زیر، شما تجسم چگونه clr به نظر می رسد برنامه را دوست دارم.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
به منظور تجسم بهتر اثر CLR، می توانید برنامه را با تعداد مراحل افزایش یافته ترسیم کنید.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
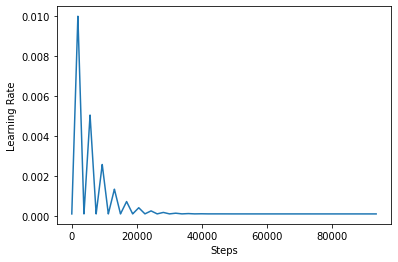
تابع شما در این آموزش با استفاده از به عنوان مراجعه کننده triangular2 روش در مقاله CLR است. دو تابع دیگر وجود دارد یعنی بررسی قرار گرفته وجود دارد triangular و exp (کوتاه برای نمایی).
یک مدل را با CLR آموزش دهید
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
همانطور که انتظار می رود ضرر بیشتر از حد معمول شروع می شود و سپس با پیشرفت چرخه ها تثبیت می شود. شما می توانید این را به صورت بصری با طرح های زیر تأیید کنید.
تجسم ضررها
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
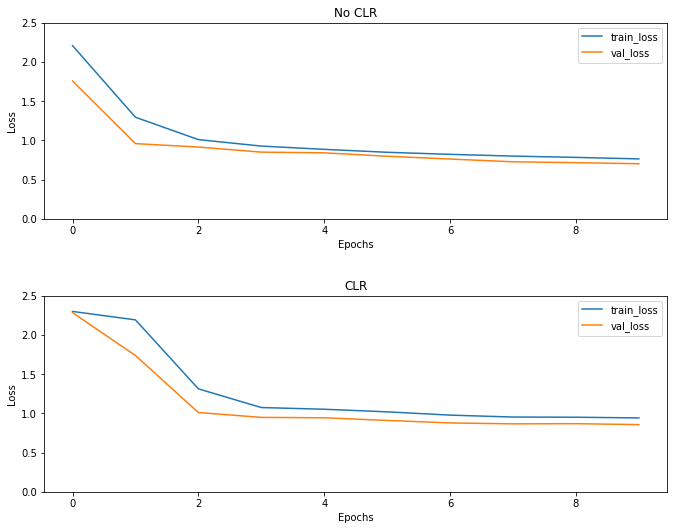
حتی اگر برای این مثال اسباب بازی، شما اثرات CLR را مشاهده نمی کند اما به ذکر است که آن را یکی از مواد تشکیل دهنده اصلی است سوپر همگرایی و می تواند دارند تاثیر واقعا خوب زمانی که آموزش در تنظیمات در مقیاس بزرگ.