
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই টিউটোরিয়ালটি অ্যাডঅন প্যাকেজ থেকে সাইক্লিক্যাল লার্নিং রেট ব্যবহার প্রদর্শন করে।
চক্রাকার শিক্ষার হার
এটি দেখানো হয়েছে যে একটি নিউরাল নেটওয়ার্কের জন্য প্রশিক্ষণের অগ্রগতির সাথে সাথে শেখার হার সামঞ্জস্য করা উপকারী। স্যাডল পয়েন্ট রিকভারি থেকে শুরু করে ব্যাকপ্রোপাগেশনের সময় দেখা দিতে পারে এমন সংখ্যাগত অস্থিরতা প্রতিরোধ পর্যন্ত এর বহুগুণ সুবিধা রয়েছে। কিন্তু একটি নির্দিষ্ট প্রশিক্ষণ টাইমস্ট্যাম্পের সাথে কতটা সামঞ্জস্য করতে হবে তা কীভাবে কেউ জানে? 2015 সালে, লেসলি স্মিথ লক্ষ্য করেছেন যে আপনি ক্ষতির ল্যান্ডস্কেপ জুড়ে দ্রুত গতিতে চলার জন্য শেখার হার বাড়াতে চান কিন্তু অভিসারে যাওয়ার সময় আপনি শেখার হার কমাতেও চান। এই ধারণা বুঝতে হলে তিনি প্রস্তাবিত চক্রাকার শিক্ষণ হার (CLR) যেখানে আপনি একটি ফাংশন চক্র থেকে সম্মান সঙ্গে শেখার হার সমন্বয় করবে। একটি চাক্ষুষ বিক্ষোভের জন্য, আপনি চেক আউট করতে পারেন এই ব্লগে । CLR এখন একটি TensorFlow API হিসাবে উপলব্ধ। অধিক বিবরণের জন্য, মূল কাগজ চেক আউট এখানে ।
সেটআপ
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
ডেটাসেট লোড করুন এবং প্রস্তুত করুন
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
হাইপারপ্যারামিটার সংজ্ঞায়িত করুন
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
মডেল বিল্ডিং এবং মডেল প্রশিক্ষণ ইউটিলিটি সংজ্ঞায়িত করুন
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
পুনরুত্পাদনযোগ্যতার স্বার্থে, প্রাথমিক মডেলের ওজনগুলি ক্রমিক করা হয় যা আপনি আমাদের পরীক্ষাগুলি পরিচালনা করতে ব্যবহার করবেন।
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
CLR ছাড়া একটি মডেল প্রশিক্ষণ
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
CLR সময়সূচী সংজ্ঞায়িত করুন
tfa.optimizers.CyclicalLearningRate সরাসরি সময়তালিকা একটি অপটিমাইজার প্রেরণ যেতে পারে যে আসতে মডিউল। সময়সূচীটি তার ইনপুট হিসাবে একটি পদক্ষেপ নেয় এবং কাগজে দেওয়া CLR সূত্র ব্যবহার করে গণনা করা একটি মান আউটপুট করে।
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
এখানে, আপনি শেখার হার আপার এবং লোয়ার বাউন্ড নির্দিষ্ট করতে ও সময়সূচী যে পরিসর মধ্যে দুলা হবে ([1e -4, 1e-2] এই ক্ষেত্রে)। scale_fn ফাংশন যা আনুপাতিক হারে বাড়ান এবং একটি প্রদত্ত চক্র মধ্যে শেখার হার আনুপাতিক হারে কমান যাবে সংজ্ঞায়িত করতে ব্যবহৃত হয়। step_size একটি একক চক্র সময়কালের সংজ্ঞা দেয়। একজন step_size 2 উপায়ে আপনি এক চক্র সম্পূর্ণ করতে 4 পুনরাবৃত্তিও মোট প্রয়োজন। জন্য প্রস্তাবিত মূল্য step_size নিম্নরূপ:
factor * steps_per_epoch যেখানে [2, 8] পরিসীমা মধ্যে ফ্যাক্টর মিথ্যা।
একই সালে CLR কাগজ , লেসলি এছাড়াও হার শেখার জন্যে সীমা চয়ন করতে একটি সহজ এবং মার্জিত পদ্ধতি উপস্থাপন করেছে। আপনি পাশাপাশি এটি পরীক্ষা করার জন্য উত্সাহিত করা হয়. এই ব্লগ পোস্ট পদ্ধতি একটা চমৎকার ভূমিকা প্রদান করে।
নীচে, আপনি ঠাহর কিভাবে clr সময়তালিকা দেখে মনে হচ্ছে।
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
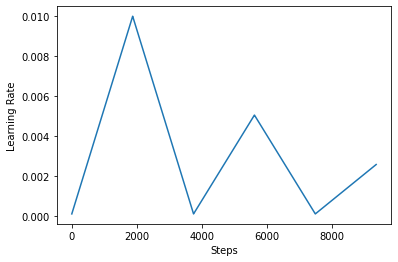
CLR-এর প্রভাবকে আরও ভালভাবে কল্পনা করার জন্য, আপনি একটি বর্ধিত সংখ্যক ধাপ সহ সময়সূচী প্লট করতে পারেন।
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
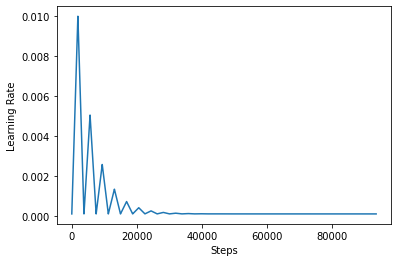
ফাংশন আপনি এই টিউটোরিয়াল ব্যবহার করছেন হিসাবে উল্লেখ করা হয় triangular2 CLR কাগজে পদ্ধতি। অন্যান্য দুটি ফাংশন যথা সেখানে অন্বেষণ করা হয়েছে triangular এবং exp (ছোট সূচকীয় জন্য)।
CLR দিয়ে একটি মডেলকে প্রশিক্ষণ দিন
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
প্রত্যাশিত হিসাবে ক্ষতি স্বাভাবিকের চেয়ে বেশি শুরু হয় এবং তারপর চক্র অগ্রগতির সাথে সাথে এটি স্থিতিশীল হয়। আপনি নীচের প্লটগুলির সাথে এটি দৃশ্যত নিশ্চিত করতে পারেন।
ক্ষতি কল্পনা করুন
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
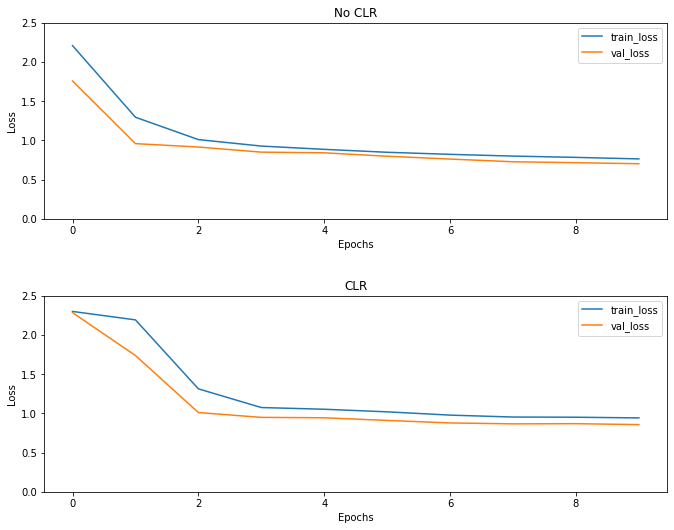
যদিও এই খেলনা উদাহরণস্বরূপ, যদি আপনি CLR প্রভাব অনেক দেখতে পাইনি কিন্তু উল্লেখ করা এটি পিছনে মূল উপাদানগুলো এক সুপার কনভার্জেন্স এবং থাকতে পারে সত্যিই ভাল প্রভাব যখন বড় মাপের সেটিংসে প্রশিক্ষণ নেন।