
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
يوضح هذا البرنامج التعليمي استخدام معدل التعلم الدوري من حزمة الإضافات.
معدلات التعلم الدوري
لقد ثبت أنه من المفيد تعديل معدل التعلم مع تقدم التدريب للشبكة العصبية. له فوائد متعددة تتراوح من استعادة نقطة السرج إلى منع عدم الاستقرار العددي الذي قد ينشأ أثناء الانتشار العكسي. ولكن كيف يمكن للمرء أن يعرف مقدار التعديل فيما يتعلق بطابع زمني معين للتدريب؟ في عام 2015 ، لاحظت ليزلي سميث أنك قد ترغب في زيادة معدل التعلم للانتقال بشكل أسرع عبر مشهد الخسارة ولكنك قد ترغب أيضًا في تقليل معدل التعلم عند الاقتراب من التقارب. لتحقيق هذه الفكرة، واقترح الدورية التعلم الاسعار (CLR) حيث كنت ضبط معدل التعلم فيما يتعلق دورات وظيفة. للمشاركة في مظاهرة البصرية، ويمكنك التحقق من هذا بلوق . CLR متاح الآن كواجهة برمجة تطبيقات TensorFlow. لمزيد من التفاصيل، راجع الورقة الأصلية هنا .
اقامة
pip install -q -U tensorflow_addons
from tensorflow.keras import layers
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.random.set_seed(42)
np.random.seed(42)
قم بتحميل وتحضير مجموعة البيانات
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
حدد المعلمات الفوقية
BATCH_SIZE = 64
EPOCHS = 10
INIT_LR = 1e-4
MAX_LR = 1e-2
تحديد بناء النموذج ونموذج مرافق التدريب
def get_training_model():
model = tf.keras.Sequential(
[
layers.InputLayer((28, 28, 1)),
layers.experimental.preprocessing.Rescaling(scale=1./255),
layers.Conv2D(16, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(32, (5, 5), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.SpatialDropout2D(0.2),
layers.GlobalAvgPool2D(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax"),
]
)
return model
def train_model(model, optimizer):
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
validation_data=(x_test, y_test),
epochs=EPOCHS)
return history
من أجل التكاثر ، يتم إجراء تسلسل لأوزان النموذج الأولي والتي ستستخدمها لإجراء تجاربنا.
initial_model = get_training_model()
initial_model.save("initial_model")
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2021-11-12 19:14:52.355642: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: initial_model/assets
تدريب نموذج بدون CLR
standard_model = tf.keras.models.load_model("initial_model")
no_clr_history = train_model(standard_model, optimizer="sgd")
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 5s 4ms/step - loss: 2.2089 - accuracy: 0.2180 - val_loss: 1.7581 - val_accuracy: 0.4137 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 1.2951 - accuracy: 0.5136 - val_loss: 0.9583 - val_accuracy: 0.6491 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 1.0096 - accuracy: 0.6189 - val_loss: 0.9155 - val_accuracy: 0.6588 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.9269 - accuracy: 0.6572 - val_loss: 0.8495 - val_accuracy: 0.7011 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8855 - accuracy: 0.6722 - val_loss: 0.8361 - val_accuracy: 0.6685 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8482 - accuracy: 0.6852 - val_loss: 0.7975 - val_accuracy: 0.6830 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.8219 - accuracy: 0.6941 - val_loss: 0.7630 - val_accuracy: 0.6990 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7995 - accuracy: 0.7011 - val_loss: 0.7280 - val_accuracy: 0.7263 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7830 - accuracy: 0.7059 - val_loss: 0.7156 - val_accuracy: 0.7445 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.7636 - accuracy: 0.7136 - val_loss: 0.7026 - val_accuracy: 0.7462
تحديد جدول CLR
و tfa.optimizers.CyclicalLearningRate حدة بإرجاع جدول المباشر التي يمكن أن تنتقل إلى محسن. يأخذ الجدول خطوة كمدخلات وإخراج قيمة محسوبة باستخدام صيغة CLR كما هو موضح في الورقة.
steps_per_epoch = len(x_train) // BATCH_SIZE
clr = tfa.optimizers.CyclicalLearningRate(initial_learning_rate=INIT_LR,
maximal_learning_rate=MAX_LR,
scale_fn=lambda x: 1/(2.**(x-1)),
step_size=2 * steps_per_epoch
)
optimizer = tf.keras.optimizers.SGD(clr)
هنا، يمكنك تحديد الحدود الدنيا والعليا من معدل التعلم وسوف جدول تتذبذب بين أن مجموعة ([1E-4، 1E-2] في هذه الحالة). scale_fn يستخدم لتحديد وظيفة التي من شأنها رفع مستوى وتقليص معدل التعلم ضمن دورة معينة. step_size يحدد مدة دورة واحدة. A step_size من 2 الوسائل تحتاج ما مجموعه 4 مرات التكرار لإتمام دورة واحدة. قيمة المستحسنة لل step_size هي على النحو التالي:
factor * steps_per_epoch حيث يكمن عامل داخل [2، 8] مجموعة.
في نفس ورقة CLR ، قدم ليزلي أيضا بسيطة وطريقة أنيقة لاختيار حدود لمعدل التعلم. أنت مدعو للتحقق من ذلك أيضًا. هذا بلوق وظيفة يوفر مقدمة لطيفة إلى الأسلوب.
أدناه، على تصور كيف clr مثل الجدول الزمني يبدو.
step = np.arange(0, EPOCHS * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
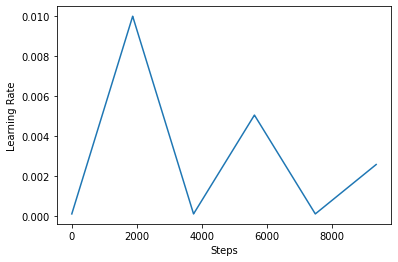
من أجل تصور تأثير CLR بشكل أفضل ، يمكنك رسم الجدول بعدد متزايد من الخطوات.
step = np.arange(0, 100 * steps_per_epoch)
lr = clr(step)
plt.plot(step, lr)
plt.xlabel("Steps")
plt.ylabel("Learning Rate")
plt.show()
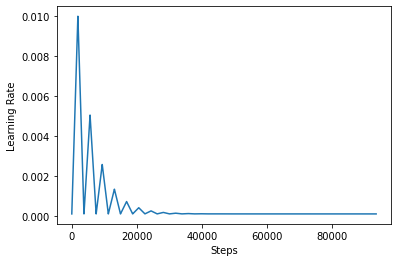
ويشار إلى الوظيفة التي تستخدم في هذا البرنامج التعليمي على أنها triangular2 الأسلوب في ورقة CLR. وهناك غيرها من وظيفتين هناك استكشفت وهي triangular و exp (قصيرة لالأسي).
تدريب نموذج باستخدام CLR
clr_model = tf.keras.models.load_model("initial_model")
clr_history = train_model(clr_model, optimizer=optimizer)
WARNING:tensorflow:No training configuration found in save file, so the model was *not* compiled. Compile it manually. Epoch 1/10 938/938 [==============================] - 4s 4ms/step - loss: 2.3005 - accuracy: 0.1165 - val_loss: 2.2852 - val_accuracy: 0.2378 Epoch 2/10 938/938 [==============================] - 3s 4ms/step - loss: 2.1931 - accuracy: 0.2398 - val_loss: 1.7386 - val_accuracy: 0.4530 Epoch 3/10 938/938 [==============================] - 3s 4ms/step - loss: 1.3132 - accuracy: 0.5052 - val_loss: 1.0110 - val_accuracy: 0.6482 Epoch 4/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0746 - accuracy: 0.5933 - val_loss: 0.9492 - val_accuracy: 0.6622 Epoch 5/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0528 - accuracy: 0.6028 - val_loss: 0.9439 - val_accuracy: 0.6519 Epoch 6/10 938/938 [==============================] - 3s 4ms/step - loss: 1.0198 - accuracy: 0.6172 - val_loss: 0.9096 - val_accuracy: 0.6620 Epoch 7/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9778 - accuracy: 0.6339 - val_loss: 0.8784 - val_accuracy: 0.6746 Epoch 8/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9535 - accuracy: 0.6487 - val_loss: 0.8665 - val_accuracy: 0.6903 Epoch 9/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9510 - accuracy: 0.6497 - val_loss: 0.8691 - val_accuracy: 0.6857 Epoch 10/10 938/938 [==============================] - 3s 4ms/step - loss: 0.9424 - accuracy: 0.6529 - val_loss: 0.8571 - val_accuracy: 0.6917
كما هو متوقع تبدأ الخسارة أعلى من المعتاد ثم تستقر مع تقدم الدورات. يمكنك تأكيد ذلك بصريًا باستخدام المؤامرات أدناه.
تصور الخسائر
(fig, ax) = plt.subplots(2, 1, figsize=(10, 8))
ax[0].plot(no_clr_history.history["loss"], label="train_loss")
ax[0].plot(no_clr_history.history["val_loss"], label="val_loss")
ax[0].set_title("No CLR")
ax[0].set_xlabel("Epochs")
ax[0].set_ylabel("Loss")
ax[0].set_ylim([0, 2.5])
ax[0].legend()
ax[1].plot(clr_history.history["loss"], label="train_loss")
ax[1].plot(clr_history.history["val_loss"], label="val_loss")
ax[1].set_title("CLR")
ax[1].set_xlabel("Epochs")
ax[1].set_ylabel("Loss")
ax[1].set_ylim([0, 2.5])
ax[1].legend()
fig.tight_layout(pad=3.0)
fig.show()
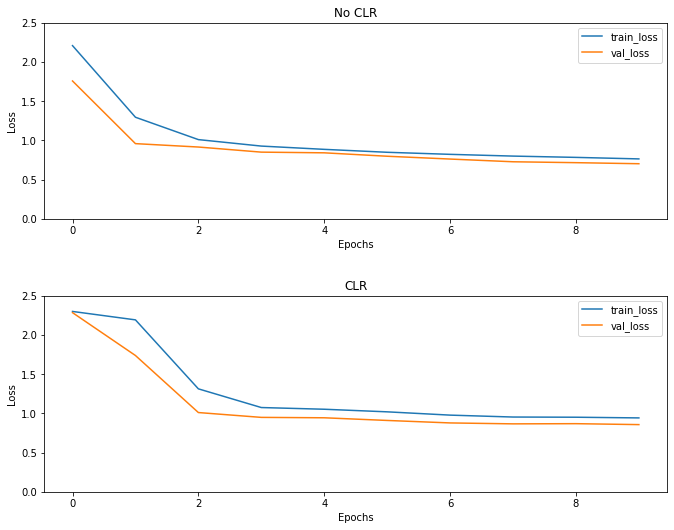
على الرغم من أن لهذه اللعبة سبيل المثال، كنت لا ترى آثار CLR بكثير ولكن تجدر الإشارة إلى أن أنها هي واحدة من المكونات الرئيسية وراء سوبر التقارب ويمكن أن يكون لها تأثير جيد حقا عندما تدريب في إعدادات نطاق واسع.