| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
این نوت بوک نحوه استفاده از Conditional Graident Optimizer از بسته Addons را نشان می دهد.
ConditionalGradient
نشان داده شده است که محدود کردن پارامترهای یک شبکه عصبی در آموزش به دلیل اثرات منظم سازی اساسی مفید است. اغلب، پارامترها از طریق یک جریمه نرم (که هرگز رضایت محدودیت را تضمین نمی کند) یا از طریق یک عملیات طرح ریزی (که از نظر محاسباتی گران است) محدود می شوند. از سوی دیگر، بهینهساز گرادیان شرطی (CG)، محدودیتها را به شدت بدون نیاز به یک مرحله طرح ریزی گران قیمت اعمال میکند. با به حداقل رساندن تقریب خطی هدف در مجموعه محدودیت کار می کند. در این نوت بوک، اعمال محدودیت هنجار Frobenius را از طریق بهینه ساز CG در مجموعه داده MNIST نشان می دهید. CG اکنون به عنوان یک API تنسورفلو در دسترس است. جزئیات بیشتر از بهینه ساز در دسترس هستند https://arxiv.org/pdf/1803.06453.pdf
برپایی
pip install -q -U tensorflow-addons
import tensorflow as tf
import tensorflow_addons as tfa
from matplotlib import pyplot as plt
# Hyperparameters
batch_size=64
epochs=10
مدل را بسازید
model_1 = tf.keras.Sequential([
tf.keras.layers.Dense(64, input_shape=(784,), activation='relu', name='dense_1'),
tf.keras.layers.Dense(64, activation='relu', name='dense_2'),
tf.keras.layers.Dense(10, activation='softmax', name='predictions'),
])
داده ها را آماده کنید
# Load MNIST dataset as NumPy arrays
dataset = {}
num_validation = 10000
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Preprocess the data
x_train = x_train.reshape(-1, 784).astype('float32') / 255
x_test = x_test.reshape(-1, 784).astype('float32') / 255
یک تابع تماس سفارشی را تعریف کنید
def frobenius_norm(m):
"""This function is to calculate the frobenius norm of the matrix of all
layer's weight.
Args:
m: is a list of weights param for each layers.
"""
total_reduce_sum = 0
for i in range(len(m)):
total_reduce_sum = total_reduce_sum + tf.math.reduce_sum(m[i]**2)
norm = total_reduce_sum**0.5
return norm
CG_frobenius_norm_of_weight = []
CG_get_weight_norm = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda batch, logs: CG_frobenius_norm_of_weight.append(
frobenius_norm(model_1.trainable_weights).numpy()))
آموزش و ارزیابی: استفاده از CG به عنوان بهینه ساز
به سادگی بهینه ساز keras معمولی را با بهینه ساز جدید tfa جایگزین کنید
# Compile the model
model_1.compile(
optimizer=tfa.optimizers.ConditionalGradient(
learning_rate=0.99949, lambda_=203), # Utilize TFA optimizer
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history_cg = model_1.fit(
x_train,
y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
callbacks=[CG_get_weight_norm])
Epoch 1/10 938/938 [==============================] - 4s 3ms/step - loss: 0.6034 - accuracy: 0.8162 - val_loss: 0.2282 - val_accuracy: 0.9313 Epoch 2/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1968 - accuracy: 0.9411 - val_loss: 0.1865 - val_accuracy: 0.9411 Epoch 3/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1502 - accuracy: 0.9552 - val_loss: 0.1356 - val_accuracy: 0.9590 Epoch 4/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1349 - accuracy: 0.9598 - val_loss: 0.1084 - val_accuracy: 0.9679 Epoch 5/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1261 - accuracy: 0.9609 - val_loss: 0.1162 - val_accuracy: 0.9648 Epoch 6/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1119 - accuracy: 0.9662 - val_loss: 0.1277 - val_accuracy: 0.9567 Epoch 7/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1096 - accuracy: 0.9671 - val_loss: 0.1009 - val_accuracy: 0.9685 Epoch 8/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1045 - accuracy: 0.9687 - val_loss: 0.1015 - val_accuracy: 0.9698 Epoch 9/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1011 - accuracy: 0.9688 - val_loss: 0.1180 - val_accuracy: 0.9627 Epoch 10/10 938/938 [==============================] - 3s 3ms/step - loss: 0.1029 - accuracy: 0.9689 - val_loss: 0.1590 - val_accuracy: 0.9516
آموزش و ارزیابی: استفاده از SGD به عنوان بهینه ساز
model_2 = tf.keras.Sequential([
tf.keras.layers.Dense(64, input_shape=(784,), activation='relu', name='dense_1'),
tf.keras.layers.Dense(64, activation='relu', name='dense_2'),
tf.keras.layers.Dense(10, activation='softmax', name='predictions'),
])
SGD_frobenius_norm_of_weight = []
SGD_get_weight_norm = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda batch, logs: SGD_frobenius_norm_of_weight.append(
frobenius_norm(model_2.trainable_weights).numpy()))
# Compile the model
model_2.compile(
optimizer=tf.keras.optimizers.SGD(0.01), # Utilize SGD optimizer
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history_sgd = model_2.fit(
x_train,
y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
callbacks=[SGD_get_weight_norm])
Epoch 1/10 938/938 [==============================] - 3s 3ms/step - loss: 1.4885 - accuracy: 0.5945 - val_loss: 0.4230 - val_accuracy: 0.8838 Epoch 2/10 938/938 [==============================] - 2s 2ms/step - loss: 0.4087 - accuracy: 0.8875 - val_loss: 0.3222 - val_accuracy: 0.9073 Epoch 3/10 938/938 [==============================] - 2s 2ms/step - loss: 0.3267 - accuracy: 0.9075 - val_loss: 0.2867 - val_accuracy: 0.9178 Epoch 4/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2903 - accuracy: 0.9186 - val_loss: 0.2605 - val_accuracy: 0.9259 Epoch 5/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2691 - accuracy: 0.9233 - val_loss: 0.2468 - val_accuracy: 0.9292 Epoch 6/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2466 - accuracy: 0.9291 - val_loss: 0.2265 - val_accuracy: 0.9352 Epoch 7/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2210 - accuracy: 0.9370 - val_loss: 0.2106 - val_accuracy: 0.9404 Epoch 8/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2137 - accuracy: 0.9387 - val_loss: 0.2029 - val_accuracy: 0.9424 Epoch 9/10 938/938 [==============================] - 2s 2ms/step - loss: 0.1996 - accuracy: 0.9429 - val_loss: 0.1937 - val_accuracy: 0.9441 Epoch 10/10 938/938 [==============================] - 2s 2ms/step - loss: 0.1925 - accuracy: 0.9450 - val_loss: 0.1831 - val_accuracy: 0.9469
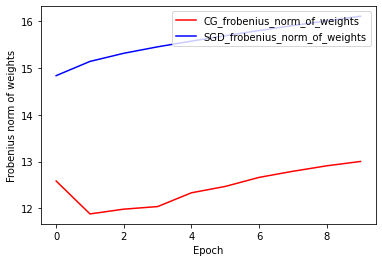
هنجار وزنه های فروبنیوس: CG در مقابل SGD
پیاده سازی فعلی بهینه ساز CG بر اساس Frobenius Norm است، با در نظر گرفتن Frobenius Norm به عنوان تنظیم کننده در تابع هدف. بنابراین، شما اثر منظم CG را با بهینه ساز SGD مقایسه می کنید که تنظیم کننده Frobenius Norm را اعمال نکرده است.
plt.plot(
CG_frobenius_norm_of_weight,
color='r',
label='CG_frobenius_norm_of_weights')
plt.plot(
SGD_frobenius_norm_of_weight,
color='b',
label='SGD_frobenius_norm_of_weights')
plt.xlabel('Epoch')
plt.ylabel('Frobenius norm of weights')
plt.legend(loc=1)
<matplotlib.legend.Legend at 0x7fada7ab12e8>
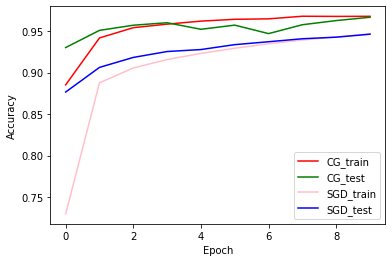
دقت قطار و اعتبارسنجی: CG در مقابل SGD
plt.plot(history_cg.history['accuracy'], color='r', label='CG_train')
plt.plot(history_cg.history['val_accuracy'], color='g', label='CG_test')
plt.plot(history_sgd.history['accuracy'], color='pink', label='SGD_train')
plt.plot(history_sgd.history['val_accuracy'], color='b', label='SGD_test')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc=4)
<matplotlib.legend.Legend at 0x7fada7983e80>