
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Sổ tay này sẽ trình bày cách sử dụng chức năng TripletSemiHardLoss trong TensorFlow Addons.
Tài nguyên:
- FaceNet: Nhúng hợp nhất để nhận dạng và phân cụm khuôn mặt
- Blog của Oliver Moindrot đã thực hiện một công việc xuất sắc trong việc mô tả chi tiết thuật toán
TripletLoss
Như được giới thiệu lần đầu trong bài báo FaceNet, TripletLoss là một hàm tổn thất giúp đào tạo mạng nơ-ron để nhúng chặt chẽ các tính năng của cùng một lớp trong khi tối đa hóa khoảng cách giữa các lần nhúng của các lớp khác nhau. Để làm điều này, một mỏ neo được chọn cùng với một mẫu âm và một mẫu dương. 
Hàm mất mát được mô tả như một hàm khoảng cách Euclide:
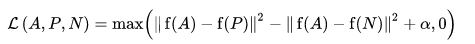
Trong đó A là đầu vào neo của chúng tôi, P là đầu vào mẫu dương, N là đầu vào mẫu âm và alpha là một số lề bạn sử dụng để chỉ định khi một bộ ba trở nên quá "dễ dàng" và bạn không còn muốn điều chỉnh trọng số từ nó nữa .
Học trực tuyến SemiHard
Như được trình bày trong bài báo, kết quả tốt nhất là từ các cặp sinh ba được gọi là "Bán cứng". Chúng được định nghĩa là bộ ba trong đó âm nằm xa mỏ neo hơn dương, nhưng vẫn tạo ra tổn thất dương. Để tìm những bộ ba này một cách hiệu quả, bạn sử dụng học trực tuyến và chỉ đào tạo từ các ví dụ Bán khó trong mỗi đợt.
Cài đặt
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Chuẩn bị dữ liệu
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Xây dựng mô hình

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Đào tạo và đánh giá
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Nhúng máy chiếu
Các file vector và siêu dữ liệu có thể được nạp và hình dung đây: https://projector.tensorflow.org/
Bạn có thể xem kết quả dữ liệu thử nghiệm được nhúng của chúng tôi khi được hiển thị bằng UMAP: 