
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
สมุดบันทึกนี้จะสาธิตวิธีใช้ฟังก์ชัน TripletSemiHardLoss ใน TensorFlow Addons
ทรัพยากร:
- FaceNet: การฝังตัวแบบครบวงจรสำหรับการจดจำใบหน้าและการจัดกลุ่ม
- บล็อกของ Oliver Moindrot อธิบายอัลกอริทึมอย่างละเอียดได้ดีเยี่ยม
TripletLoss
ตามที่แนะนำครั้งแรกในกระดาษของ FaceNet TripletLoss เป็นฟังก์ชันการสูญเสียที่ฝึกโครงข่ายประสาทเทียมเพื่อฝังคุณลักษณะของคลาสเดียวกันอย่างใกล้ชิดในขณะที่เพิ่มระยะห่างระหว่างการฝังของคลาสต่างๆ ในการทำเช่นนี้ สมอจะถูกเลือกพร้อมกับตัวอย่างเชิงลบหนึ่งตัวอย่างและหนึ่งตัวอย่างบวก 
ฟังก์ชันการสูญเสียถูกอธิบายว่าเป็นฟังก์ชันระยะทางแบบยุคลิด:
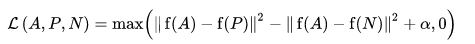
โดยที่ A คืออินพุตสมอของเรา P คืออินพุตตัวอย่างที่เป็นค่าบวก N คืออินพุตตัวอย่างเชิงลบ และอัลฟ่าคือระยะขอบบางส่วนที่คุณใช้เพื่อระบุเมื่อ triplet กลายเป็น "ง่าย" เกินไป และคุณไม่ต้องการปรับน้ำหนักอีกต่อไป .
การเรียนรู้ออนไลน์กึ่งฮาร์ด
ตามที่แสดงในกระดาษ ผลลัพธ์ที่ดีที่สุดมาจากแฝดสามที่เรียกว่า "กึ่งแข็ง" สิ่งเหล่านี้ถูกกำหนดให้เป็นแฝดสามโดยที่ค่าลบอยู่ห่างจากสมอมากกว่าค่าบวก แต่ยังคงก่อให้เกิดการสูญเสียในเชิงบวก ในการค้นหาแฝดสามอย่างมีประสิทธิภาพ คุณใช้การเรียนรู้ออนไลน์และฝึกฝนเฉพาะจากตัวอย่างแบบกึ่งยากในแต่ละชุดงานเท่านั้น
ติดตั้ง
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
เตรียมข้อมูล
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
สร้างแบบจำลอง

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
ฝึกฝนและประเมินผล
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
โปรเจคเตอร์ฝังตัว
เวกเตอร์และเมตาดาต้าไฟล์ที่สามารถโหลดและมองเห็นที่นี่: https://projector.tensorflow.org/
คุณสามารถดูผลลัพธ์ของข้อมูลการทดสอบที่ฝังไว้ของเราเมื่อแสดงผลด้วย UMAP: 