
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
В этом блокноте будет показано, как использовать функцию TripletSemiHardLoss в надстройках TensorFlow.
Ресурсы:
- FaceNet: унифицированное встраивание для распознавания лиц и кластеризации
- Блог Оливера Моиндрота отлично описывает алгоритм в деталях.
TripletLoss
Как впервые было представлено в статье FaceNet, TripletLoss - это функция потерь, которая обучает нейронную сеть тесно встраивать функции одного класса, увеличивая при этом расстояние между встраиваниями разных классов. Для этого выбирается якорь вместе с одним отрицательным и одним положительным образцом. 
Функция потерь описывается как функция евклидова расстояния:
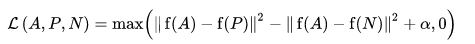
Где A - наш вход привязки, P - вход положительной выборки, N - вход отрицательной выборки, а альфа - некоторый запас, который вы используете, чтобы указать, когда триплет стал слишком "легким", и вы больше не хотите регулировать веса из него. .
Полужесткое онлайн-обучение
Как показано в статье, наилучшие результаты получены от триплетов, известных как «полужесткие». Они определяются как триплеты, где отрицательный элемент дальше от привязки, чем положительный, но все же приводит к положительным потерям. Чтобы эффективно находить эти триплеты, вы используете онлайн-обучение и тренируетесь только на полужестких примерах в каждой партии.
Настраивать
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Подготовьте данные
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Постройте модель

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Тренируй и оценивай
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Встраиваемый проектор
Вектор и метаданные файлы могут быть загружены и визуализировали здесь: https://projector.tensorflow.org/
Вы можете увидеть результаты наших встроенных тестовых данных при визуализации с помощью UMAP: 