
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Ten notatnik pokaże, jak korzystać z funkcji TripletSemiHardLoss w dodatkach TensorFlow.
Zasoby:
- FaceNet: ujednolicone osadzanie do rozpoznawania twarzy i tworzenia klastrów
- Blog Olivera Moindrota znakomicie opisuje szczegółowo algorytm
Przegrana trójka
Jak po raz pierwszy przedstawiono w artykule FaceNet, TripletLoss to funkcja straty, która uczy sieć neuronową, aby ściśle osadzić cechy tej samej klasy, jednocześnie maksymalizując odległość między osadzaniami różnych klas. W tym celu wybiera się kotwicę oraz jedną negatywną i jedną pozytywną próbkę. 
Funkcja straty jest opisana jako funkcja odległości euklidesowej:
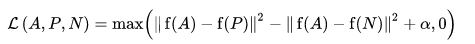
Gdzie A to nasze zakotwiczone dane wejściowe, P to dodatnie dane wejściowe próbki, N to ujemne dane wejściowe próbki, a alfa to pewien margines, którego używasz do określenia, kiedy tryplet stał się zbyt „łatwy” i nie chcesz już na jego podstawie dostosowywać wag .
Półtwarda nauka online
Jak pokazano w artykule, najlepsze wyniki uzyskuje się z trojaczków znanych jako „półtwarde”. Są one definiowane jako trojaczki, w których negatyw jest dalej od kotwicy niż pozytyw, ale nadal powoduje pozytywną stratę. Aby skutecznie znaleźć te trojaczki, wykorzystujesz naukę online i trenujesz tylko z przykładów półtwardych w każdej partii.
Ustawiać
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Przygotuj dane
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Zbuduj model

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Trenuj i oceniaj
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Projektor do osadzania
Pliki wektorowe i metadane mogą być ładowane i wizualizowane tutaj: https://projector.tensorflow.org/
Możesz zobaczyć wyniki naszych osadzonych danych testowych podczas wizualizacji za pomocą UMAP: 