
| |  GitHubでソースを表示 GitHubでソースを表示 | |
概要
このノートブックでは、TensorFlowアドオンでTripletSemiHardLoss関数を使用する方法を示します。
資力:
TripletLoss
FaceNetの論文で最初に紹介されたように、TripletLossは、異なるクラスの埋め込み間の距離を最大化しながら、同じクラスの機能を密接に埋め込むようにニューラルネットワークをトレーニングする損失関数です。これを行うために、1つのネガティブサンプルと1つのポジティブサンプルとともにアンカーが選択されます。 
損失関数は、ユークリッド距離関数として記述されます。
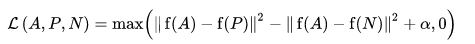
ここで、Aはアンカー入力、Pは正のサンプル入力、Nは負のサンプル入力、アルファはトリプレットが「簡単」になりすぎて重みを調整する必要がなくなったときに指定するマージンです。 。
セミハードオンライン学習
論文に示されているように、最良の結果は「セミハード」として知られているトリプレットからのものです。これらは、ネガティブがポジティブよりもアンカーから遠いが、それでもポジティブな損失を生み出すトリプレットとして定義されます。これらのトリプレットを効率的に見つけるには、オンライン学習を利用し、各バッチのセミハードの例からのみトレーニングします。
設定
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
データを準備する
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
モデルを構築する

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
トレーニングと評価
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
埋め込みプロジェクター
ベクトルおよびメタデータファイルがロードされ、ここで可視化することができる。 https://projector.tensorflow.org/
UMAPで視覚化すると、埋め込まれたテストデータの結果を確認できます。 