
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
यह नोटबुक प्रदर्शित करेगी कि TensorFlow Addons में TriptSemiHardLoss फ़ंक्शन का उपयोग कैसे करें।
साधन:
- फेसनेट: फेस रिकग्निशन और क्लस्टरिंग के लिए एक एकीकृत एंबेडिंग
- ओलिवर मोइंड्रोट का ब्लॉग एल्गोरिथम का विस्तार से वर्णन करने का एक उत्कृष्ट कार्य करता है
ट्रिपल नुकसान
जैसा कि पहली बार फेसनेट पेपर में पेश किया गया था, ट्रिपलटलॉस एक नुकसान फ़ंक्शन है जो विभिन्न वर्गों के एम्बेडिंग के बीच की दूरी को अधिकतम करते हुए एक ही वर्ग की सुविधाओं को बारीकी से एम्बेड करने के लिए एक तंत्रिका नेटवर्क को प्रशिक्षित करता है। ऐसा करने के लिए एक एंकर को एक नकारात्मक और एक सकारात्मक नमूने के साथ चुना जाता है। 
हानि फ़ंक्शन को यूक्लिडियन दूरी फ़ंक्शन के रूप में वर्णित किया गया है:
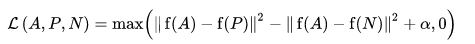
जहां ए हमारा एंकर इनपुट है, पी सकारात्मक नमूना इनपुट है, एन नकारात्मक नमूना इनपुट है, और अल्फा कुछ मार्जिन है जिसे आप निर्दिष्ट करने के लिए उपयोग करते हैं जब एक ट्रिपल बहुत "आसान" हो जाता है और अब आप इससे वजन समायोजित नहीं करना चाहते हैं .
सेमीहार्ड ऑनलाइन लर्निंग
जैसा कि पेपर में दिखाया गया है, सर्वोत्तम परिणाम "सेमी-हार्ड" के रूप में जाने जाने वाले ट्रिपल से होते हैं। इन्हें ट्रिपलेट्स के रूप में परिभाषित किया जाता है जहां नकारात्मक सकारात्मक की तुलना में एंकर से दूर होता है, लेकिन फिर भी एक सकारात्मक नुकसान पैदा करता है। इन तीनों को कुशलता से खोजने के लिए आप ऑनलाइन शिक्षण का उपयोग करते हैं और प्रत्येक बैच में केवल सेमी-हार्ड उदाहरणों से प्रशिक्षण लेते हैं।
सेट अप
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
डेटा तैयार करें
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
मॉडल बनाएं

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
ट्रेन और मूल्यांकन
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
एम्बेडिंग प्रोजेक्टर
वेक्टर और मेटाडाटा फ़ाइलें लोड और यहां देखे जा सकते हैं: https://projector.tensorflow.org/
UMAP के साथ देखे जाने पर आप हमारे एम्बेडेड परीक्षण डेटा के परिणाम देख सकते हैं: 