
 Voir la source sur GitHub
Voir la source sur GitHubAperçu
Ce cahier montrera comment utiliser la fonction TripletSemiHardLoss dans les modules complémentaires TensorFlow.
Ressources:
- FaceNet : une intégration unifiée pour la reconnaissance faciale et le clustering
- Le blog d'Oliver Moindrot fait un excellent travail en décrivant l'algorithme en détail
TripletPerte
Comme présenté pour la première fois dans l'article de FaceNet, TripletLoss est une fonction de perte qui entraîne un réseau de neurones à intégrer étroitement les caractéristiques de la même classe tout en maximisant la distance entre les intégrations de différentes classes. Pour ce faire, une ancre est choisie avec un échantillon négatif et un échantillon positif. 
La fonction de perte est décrite comme une fonction de distance euclidienne :
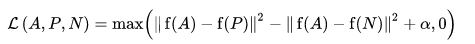
Où A est notre entrée d'ancrage, P est l'entrée d'échantillon positive, N est l'entrée d'échantillon négative et alpha est une marge que vous utilisez pour spécifier quand un triplet est devenu trop "facile" et que vous ne voulez plus ajuster les poids à partir de celui-ci .
Apprentissage en ligne semi-difficile
Comme le montre l'article, les meilleurs résultats proviennent de triplés connus sous le nom de "Semi-Hard". Ceux-ci sont définis comme des triplets où le négatif est plus éloigné de l'ancre que le positif, mais produit toujours une perte positive. Pour trouver efficacement ces triplés, vous utilisez l'apprentissage en ligne et vous vous entraînez uniquement à partir des exemples semi-difficiles de chaque lot.
Installer
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Préparer les données
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Construire le modèle

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Former et évaluer
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Projecteur intégré
Les fichiers vectoriels et métadonnées peuvent être chargés et visualisés ici: https://projector.tensorflow.org/
Vous pouvez voir les résultats de nos données de test intégrées lorsqu'elles sont visualisées avec UMAP : 