
 Ver fuente en GitHub
Ver fuente en GitHubVisión general
Este cuaderno demostrará cómo usar la función TripletSemiHardLoss en los complementos de TensorFlow.
Recursos:
- FaceNet: una incrustación unificada para el reconocimiento facial y la agrupación en clústeres
- El blog de Oliver Moindrot hace un excelente trabajo al describir el algoritmo en detalle
TripletePérdida
Como se introdujo por primera vez en el documento de FaceNet, TripletLoss es una función de pérdida que entrena una red neuronal para integrar de cerca características de la misma clase mientras maximiza la distancia entre incrustaciones de diferentes clases. Para hacer esto, se elige un ancla junto con una muestra negativa y una positiva. 
La función de pérdida se describe como una función de distancia euclidiana:
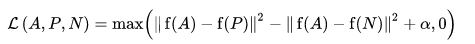
Donde A es nuestra entrada de anclaje, P es la entrada de muestra positiva, N es la entrada de muestra negativa y alfa es un margen que usa para especificar cuando un triplete se ha vuelto demasiado "fácil" y ya no desea ajustar los pesos de él. .
Aprendizaje en línea semi-duro
Como se muestra en el documento, los mejores resultados provienen de los tripletes conocidos como "semiduros". Estos se definen como tripletes en los que lo negativo está más lejos del ancla que lo positivo, pero aún así produce una pérdida positiva. Para encontrar estos trillizos de manera eficiente, utiliza el aprendizaje en línea y solo entrena con los ejemplos semiduros de cada lote.
Configuración
pip install -q -U tensorflow-addons
import io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
Prepare los datos
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset 11.06 MiB (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
Construye el modelo

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
Capacitar y evaluar
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 21s 5ms/step - loss: 0.6983 Epoch 2/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4723 Epoch 3/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4298 Epoch 4/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.4139 Epoch 5/5 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3938
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Proyector de incrustación
Los archivos vectoriales y metadatos pueden ser cargados y visualizados aquí: https://projector.tensorflow.org/
Puede ver los resultados de nuestros datos de prueba integrados cuando se visualizan con UMAP: 