GitHub에서 소스 보기 GitHub에서 소스 보기 |
개요
이 노트북은 가중치 정규화 레이어를 사용하는 방법과 수렴을 향상할 수 있는 방법을 보여줍니다.
WeightNormalization
심층 신경망의 훈련을 가속하기 위한 간단한 재매개변수화:
Tim Salimans, Diederik P. Kingma (2016)
이러한 방식으로 가중치를 재매개변수화함으로써 최적화 문제의 처리를 개선하고 확률적 경사 하강의 수렴을 가속합니다. 재매개변수화는 배치 정규화에서 영감을 얻었지만, 미니 배치의 예제 간에 종속성을 도입하지는 않습니다. 이는 이 방법이 배치 정규화가 덜 적합한 LSTM과 같은 반복 모델과 심층 강화 학습 또는 생성 모델과 같은 노이즈에 민감한 애플리케이션에 성공적으로 적용될 수 있음을 의미합니다. 이 방법은 훨씬 간단하지만, 전체 배치 정규화의 속도를 크게 향상합니다. 또한, 이 방법의 계산 오버헤드가 더 적으므로 같은 시간에 더 많은 최적화 단계를 수행할 수 있습니다.
설정
pip install -q -U tensorflow-addonsimport tensorflow as tf
import tensorflow_addons as tfa
import numpy as np
from matplotlib import pyplot as plt
# Hyper Parameters
batch_size = 32
epochs = 10
num_classes=10
모델 빌드하기
# Standard ConvNet
reg_model = tf.keras.Sequential([
tf.keras.layers.Conv2D(6, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(16, 5, activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation='relu'),
tf.keras.layers.Dense(84, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax'),
])
# WeightNorm ConvNet
wn_model = tf.keras.Sequential([
tfa.layers.WeightNormalization(tf.keras.layers.Conv2D(6, 5, activation='relu')),
tf.keras.layers.MaxPooling2D(2, 2),
tfa.layers.WeightNormalization(tf.keras.layers.Conv2D(16, 5, activation='relu')),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(120, activation='relu')),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(84, activation='relu')),
tfa.layers.WeightNormalization(tf.keras.layers.Dense(num_classes, activation='softmax')),
])
데이터 로드하기
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# Convert class vectors to binary class matrices.
y_train = tf.keras.utils.to_categorical(y_train, num_classes)
y_test = tf.keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step
모델 훈련하기
reg_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
reg_history = reg_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
Epoch 1/10 1563/1563 [==============================] - 5s 3ms/step - loss: 1.6373 - accuracy: 0.4014 - val_loss: 1.4192 - val_accuracy: 0.4774 Epoch 2/10 1563/1563 [==============================] - 4s 3ms/step - loss: 1.3673 - accuracy: 0.5106 - val_loss: 1.3043 - val_accuracy: 0.5369 Epoch 3/10 1563/1563 [==============================] - 4s 3ms/step - loss: 1.2437 - accuracy: 0.5571 - val_loss: 1.2662 - val_accuracy: 0.5441 Epoch 4/10 1563/1563 [==============================] - 4s 3ms/step - loss: 1.1561 - accuracy: 0.5916 - val_loss: 1.1837 - val_accuracy: 0.5858 Epoch 5/10 1563/1563 [==============================] - 4s 3ms/step - loss: 1.0962 - accuracy: 0.6118 - val_loss: 1.1664 - val_accuracy: 0.5898 Epoch 6/10 1563/1563 [==============================] - 4s 3ms/step - loss: 1.0444 - accuracy: 0.6311 - val_loss: 1.1396 - val_accuracy: 0.6047 Epoch 7/10 1563/1563 [==============================] - 4s 3ms/step - loss: 0.9957 - accuracy: 0.6496 - val_loss: 1.1266 - val_accuracy: 0.6101 Epoch 8/10 1563/1563 [==============================] - 4s 3ms/step - loss: 0.9555 - accuracy: 0.6633 - val_loss: 1.1521 - val_accuracy: 0.6028 Epoch 9/10 1563/1563 [==============================] - 4s 3ms/step - loss: 0.9167 - accuracy: 0.6772 - val_loss: 1.1309 - val_accuracy: 0.6132 Epoch 10/10 1563/1563 [==============================] - 4s 3ms/step - loss: 0.8779 - accuracy: 0.6891 - val_loss: 1.1575 - val_accuracy: 0.6045
wn_model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
wn_history = wn_model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
Epoch 1/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.5913 - accuracy: 0.4222 - val_loss: 1.4270 - val_accuracy: 0.4791 Epoch 2/10 1563/1563 [==============================] - 7s 5ms/step - loss: 1.3218 - accuracy: 0.5244 - val_loss: 1.2732 - val_accuracy: 0.5428 Epoch 3/10 1563/1563 [==============================] - 7s 5ms/step - loss: 1.2096 - accuracy: 0.5673 - val_loss: 1.2939 - val_accuracy: 0.5403 Epoch 4/10 1563/1563 [==============================] - 8s 5ms/step - loss: 1.1279 - accuracy: 0.5982 - val_loss: 1.1730 - val_accuracy: 0.5866 Epoch 5/10 1563/1563 [==============================] - 7s 5ms/step - loss: 1.0682 - accuracy: 0.6190 - val_loss: 1.1559 - val_accuracy: 0.5880 Epoch 6/10 1563/1563 [==============================] - 7s 5ms/step - loss: 1.0139 - accuracy: 0.6412 - val_loss: 1.1333 - val_accuracy: 0.6025 Epoch 7/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.9641 - accuracy: 0.6584 - val_loss: 1.1257 - val_accuracy: 0.6100 Epoch 8/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.9190 - accuracy: 0.6736 - val_loss: 1.1275 - val_accuracy: 0.6057 Epoch 9/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.8774 - accuracy: 0.6897 - val_loss: 1.1257 - val_accuracy: 0.6120 Epoch 10/10 1563/1563 [==============================] - 8s 5ms/step - loss: 0.8379 - accuracy: 0.7040 - val_loss: 1.1223 - val_accuracy: 0.6183
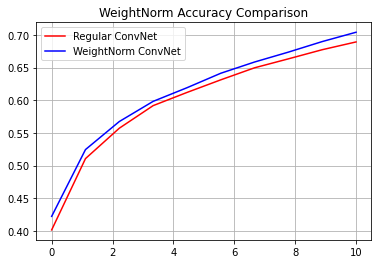
reg_accuracy = reg_history.history['accuracy']
wn_accuracy = wn_history.history['accuracy']
plt.plot(np.linspace(0, epochs, epochs), reg_accuracy,
color='red', label='Regular ConvNet')
plt.plot(np.linspace(0, epochs, epochs), wn_accuracy,
color='blue', label='WeightNorm ConvNet')
plt.title('WeightNorm Accuracy Comparison')
plt.legend()
plt.grid(True)
plt.show()