
tf.function の基礎" />
 GitHub でソースを表示 GitHub でソースを表示 |
概要
このガイドは、TensorFlow の仕組みを説明するために、TensorFlow と Keras 基礎を説明します。今すぐ Keras に取り組みたい方は、Keras のガイド一覧をご覧ください。
このガイドでは、TensorFlow でグラフ取得のための単純なコード変更、格納と表現、およびモデルの高速化とエクスポートを行う方法を説明します。
注意: TensorFlow 1.x のみの知識をお持ちの場合は、このガイドでは、非常に異なるグラフビューが紹介されています。
ここでは、tf.function を使って Eager execution から Graph execution に切り替える方法を概説しています。より詳しい tf.function の仕様については、tf.function によるパフォーマンスの改善ガイドをご覧ください。
グラフとは?
前の 3 つのガイドでは、TensorFlow を Eager で実行する方法を紹介しました。つまり、TensorFlow 演算は、Python によって演算ごとに実行され、Python に結果を戻しました。
Eager execution には特有のメリットがいくつかありますが、Graph execution では Python 外への移植が可能になり、より優れたパフォーマンスを得られる傾向にあります。Graph execution では、テンソルの計算は TensorFlow グラフ(tf.Graph または単に「graph」とも呼ばれます)として実行されます。
グラフとは、計算のユニットを表す一連の tf.Operation オブジェクトと、演算間を流れるデータのユニットを表す tf.Tensor オブジェクトを含むデータ構造です。 tf.Graph コンテキストで定義されます。これらのグラフはデータ構造であるため、元の Python コードがなくても、保存、実行、および復元することができます。
次は、TensorBoard で視覚化された二層ニューラルネットワークを表現する TensorFlow グラフです。
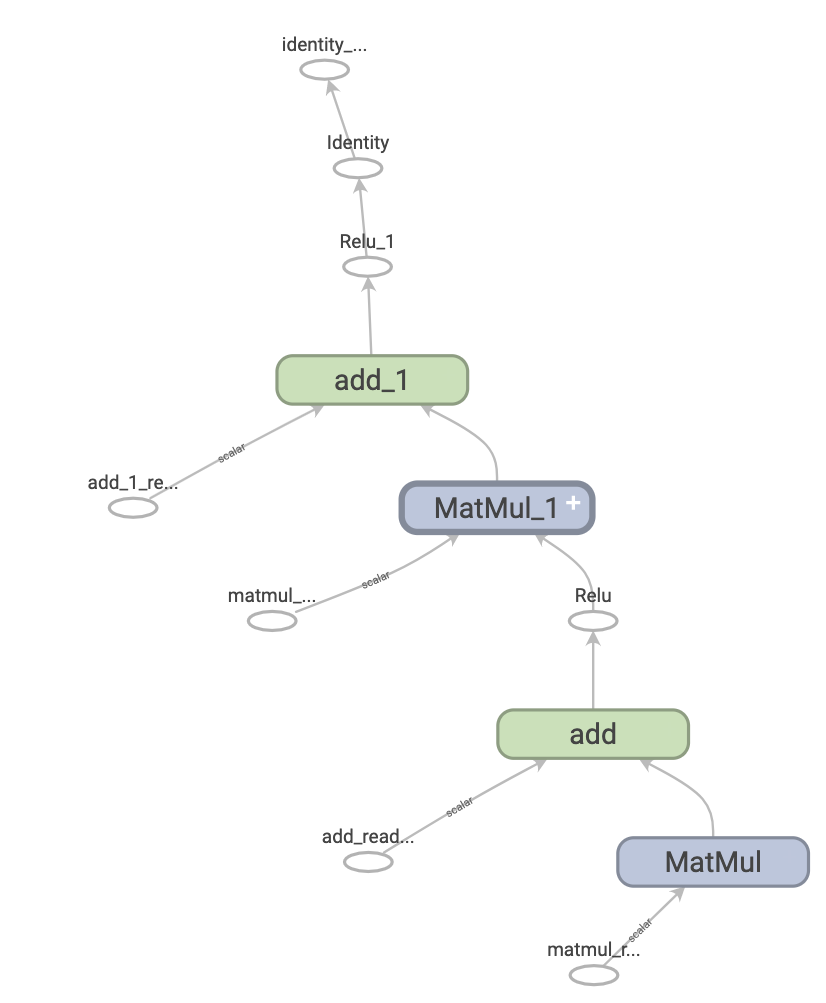
グラフのメリット
グラフを使用すると、柔軟性が大幅に向上し、モバイルアプリケーション、組み込みデバイス、バックエンドサーバーといった Python インタプリタのない環境でも TensorFlow グラフを使用できます。TensorFlow は、Python からエクスポートする場合に、SavedModel の形式としてグラフを使用します。
また、グラフは最適化を簡単に行えるため、コンパイラは次のような変換を行えます。
- 計算に定数ノードを畳み込むで、テンソルの値を統計的に推論します(「定数畳み込み」)。
- 独立した計算のサブパートを分離し、スレッドまたはデバイスに分割します。
- 共通部分式を取り除き、算術演算を単純化します。
これやほかの高速化を実行する Grappler という総合的な最適化システムがあります。
まとめると、グラフは非常に便利なもので、複数のデバイスで、TensorFlow の高速化、並列化、および効率化を期待することができます。
ただし、便宜上、Python で機械学習モデル(またはその他の計算)を定義した後、必要となったときに自動的にグラフを作成することをお勧めします。
セットアップ
いくつかの必要なライブラリをインポートします。
import tensorflow as tf
import timeit
from datetime import datetime
2024-01-11 19:23:34.661930: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 19:23:34.661977: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 19:23:34.663554: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
グラフを利用する
TensorFlow では、tf.function を直接呼出しまたはデコレータとして使用し、グラフを作成して実行します。tf.function は通常の関数を入力として取り、Function を返します。Function は、Python 関数から TensorFlow グラフを構築する Python コーラブルです。Function は 相当する Python 関数と同様に使用します。
# Define a Python function.
def a_regular_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# `a_function_that_uses_a_graph` is a TensorFlow `Function`.
a_function_that_uses_a_graph = tf.function(a_regular_function)
# Make some tensors.
x1 = tf.constant([[1.0, 2.0]])
y1 = tf.constant([[2.0], [3.0]])
b1 = tf.constant(4.0)
orig_value = a_regular_function(x1, y1, b1).numpy()
# Call a `Function` like a Python function.
tf_function_value = a_function_that_uses_a_graph(x1, y1, b1).numpy()
assert(orig_value == tf_function_value)
一方、Function は TensorFlow 演算を使って記述する通常の関数のように見えます。ただし、その根底では非常に異なります。Function は 1 つの API の背後で複数の tf.Graph をカプセル化しています(詳細については、多態性セクションをご覧ください)。Function が速度やデプロイ可能性といった Graph execution のメリットを提供できるのはこのためです。(上記のグラフのメリットをご覧ください)。
tf.function は関数とそれが呼び出すその他すべての関数に次のように適用します。
def inner_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# Use the decorator to make `outer_function` a `Function`.
@tf.function
def outer_function(x):
y = tf.constant([[2.0], [3.0]])
b = tf.constant(4.0)
return inner_function(x, y, b)
# Note that the callable will create a graph that
# includes `inner_function` as well as `outer_function`.
outer_function(tf.constant([[1.0, 2.0]])).numpy()
array([[12.]], dtype=float32)
TensorFlow 1.x を使用したことがある場合は、Placeholder または tf.Sesssion をまったく定義する必要がないことに気づくでしょう。
Python 関数をグラフに変換する
TensorFlow で記述するすべての関数には、組み込みの TF 演算と、if-then 句、ループ、break、return、continue などの Python ロジックが含まれます。TensorFlow 演算は tf.Graph で簡単にキャプチャされますが、Python 固有のロジックがグラフの一部となるには、さらにステップが必要となります。tf.function は、Python コードをグラフが生成するコードに変換するために、AutoGraph(tf.autograph)というライブラリを使用しています。
def simple_relu(x):
if tf.greater(x, 0):
return x
else:
return 0
# `tf_simple_relu` is a TensorFlow `Function` that wraps `simple_relu`.
tf_simple_relu = tf.function(simple_relu)
print("First branch, with graph:", tf_simple_relu(tf.constant(1)).numpy())
print("Second branch, with graph:", tf_simple_relu(tf.constant(-1)).numpy())
First branch, with graph: 1 Second branch, with graph: 0
直接グラフを閲覧する必要があることはほぼありませんが、正確な結果を確認するために出力を検査することは可能です。簡単に読み取れるものではありませんので、精査する必要はありません!
# This is the graph-generating output of AutoGraph.
print(tf.autograph.to_code(simple_relu))
def tf__simple_relu(x):
with ag__.FunctionScope('simple_relu', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:
do_return = False
retval_ = ag__.UndefinedReturnValue()
def get_state():
return (do_return, retval_)
def set_state(vars_):
nonlocal retval_, do_return
(do_return, retval_) = vars_
def if_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = ag__.ld(x)
except:
do_return = False
raise
def else_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = 0
except:
do_return = False
raise
ag__.if_stmt(ag__.converted_call(ag__.ld(tf).greater, (ag__.ld(x), 0), None, fscope), if_body, else_body, get_state, set_state, ('do_return', 'retval_'), 2)
return fscope.ret(retval_, do_return)
# This is the graph itself.
print(tf_simple_relu.get_concrete_function(tf.constant(1)).graph.as_graph_def())
node {
name: "x"
op: "Placeholder"
attr {
key: "_user_specified_name"
value {
s: "x"
}
}
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "shape"
value {
shape {
}
}
}
}
node {
name: "Greater/y"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node {
name: "Greater"
op: "Greater"
input: "x"
input: "Greater/y"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "cond"
op: "StatelessIf"
input: "Greater"
input: "x"
attr {
key: "Tcond"
value {
type: DT_BOOL
}
}
attr {
key: "Tin"
value {
list {
type: DT_INT32
}
}
}
attr {
key: "Tout"
value {
list {
type: DT_BOOL
type: DT_INT32
}
}
}
attr {
key: "_lower_using_switch_merge"
value {
b: true
}
}
attr {
key: "_read_only_resource_inputs"
value {
list {
}
}
}
attr {
key: "else_branch"
value {
func {
name: "cond_false_31"
}
}
}
attr {
key: "output_shapes"
value {
list {
shape {
}
shape {
}
}
}
}
attr {
key: "then_branch"
value {
func {
name: "cond_true_30"
}
}
}
}
node {
name: "cond/Identity"
op: "Identity"
input: "cond"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node {
name: "cond/Identity_1"
op: "Identity"
input: "cond:1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "Identity"
op: "Identity"
input: "cond/Identity_1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
library {
function {
signature {
name: "cond_false_31"
input_arg {
name: "cond_placeholder"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_1"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_2"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Const_3"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const_3:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Const_4"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond/Const_4:output:0"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
}
}
}
function {
signature {
name: "cond_true_30"
input_arg {
name: "cond_identity_1_x"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond_identity_1_x"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
attr {
key: "_user_specified_name"
value {
s: "x"
}
}
}
}
}
}
versions {
producer: 1645
min_consumer: 12
}
ほとんどの場合、tf.function の動作に特別な考慮はいりませんが、いくつかの注意事項があり、これについては tf.function ガイドのほか、詳細な Autograph リファレンスが役立ちます。
ポリモーフィズム: 1 つの Function で複数のグラフを得る
tf.Graph は特定の型の入力(特定の dtype のテンソルまたは同じ id() のオブジェクトなど)に特化しています。
既存のグラフ(新しい dtypes や互換性のない形状の引数など)では処理できない一連の引数を指定して Function を呼び出すたびに、Function はそれらの新しい引数に特化した新しい tf.Graph を作成します。tf.Graph の入力の型指定は、その入力シグネチャ、または単にシグネチャとして知られています。新しい tf.Graph がいつ生成されるか、およびそれをどのように制御できるかに関する詳細については、tf.function ガイドによるパフォーマンスの改善のトレーシングのルールセクションに移動してください。
Function はそのシグネチャに対応する tf.Graph を ConcreteFunction に格納します。ConcreteFunction は tf.Graph を囲むラッパーです。
@tf.function
def my_relu(x):
return tf.maximum(0., x)
# `my_relu` creates new graphs as it observes more signatures.
print(my_relu(tf.constant(5.5)))
print(my_relu([1, -1]))
print(my_relu(tf.constant([3., -3.])))
tf.Tensor(5.5, shape=(), dtype=float32) tf.Tensor([1. 0.], shape=(2,), dtype=float32) tf.Tensor([3. 0.], shape=(2,), dtype=float32)
Function がそのシグネチャですでに呼び出されている場合、Function は新しい tf.Graph を作成しません。
# These two calls do *not* create new graphs.
print(my_relu(tf.constant(-2.5))) # Signature matches `tf.constant(5.5)`.
print(my_relu(tf.constant([-1., 1.]))) # Signature matches `tf.constant([3., -3.])`.
tf.Tensor(0.0, shape=(), dtype=float32) tf.Tensor([0. 1.], shape=(2,), dtype=float32)
複数のグラフでサポートされているため、Function はポリモーフィックです。そのため、単一の tf.Graph が表現できる以上の入力型をサポートし、パフォーマンスが改善されるように tf.Graph ごとに最適化することができます。
# There are three `ConcreteFunction`s (one for each graph) in `my_relu`.
# The `ConcreteFunction` also knows the return type and shape!
print(my_relu.pretty_printed_concrete_signatures())
Input Parameters: x (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.float32, name=None) Output Type: TensorSpec(shape=(), dtype=tf.float32, name=None) Captures: None Input Parameters: x (POSITIONAL_OR_KEYWORD): List[Literal[1], Literal[-1]] Output Type: TensorSpec(shape=(2,), dtype=tf.float32, name=None) Captures: None Input Parameters: x (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(2,), dtype=tf.float32, name=None) Output Type: TensorSpec(shape=(2,), dtype=tf.float32, name=None) Captures: None
tf.function を使用する
ここまでで、tf.function をデコレータまたはラッパーとして使用するだけで、Python 関数をグラフに変換できることを学習しました。しかし実際には、tf.function を正しく動作させるにはコツがいります!以下のセクションでは、tf.function を使って期待通りにコードを動作させるようにする方法を説明します。
Graph execution と Eager execution
Function 内のコードは、Eager と Graph の両方で実行できますが、デフォルトでは、Function は Graph としてコードを実行するようになっています。
@tf.function
def get_MSE(y_true, y_pred):
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
y_true = tf.random.uniform([5], maxval=10, dtype=tf.int32)
y_pred = tf.random.uniform([5], maxval=10, dtype=tf.int32)
print(y_true)
print(y_pred)
tf.Tensor([9 6 8 1 5], shape=(5,), dtype=int32) tf.Tensor([2 4 4 2 3], shape=(5,), dtype=int32)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=14>
Function のグラフがそれに相当する Python 関数と同じように計算していることを確認するには、tf.config.run_functions_eagerly(True) を使って Eager で実行することができます。これは、通常どおりコードを実行するのではなく、グラフを作成して実行する Function の能力をオフにするスイッチです。
tf.config.run_functions_eagerly(True)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=14>
# Don't forget to set it back when you are done.
tf.config.run_functions_eagerly(False)
ただし、Eager execution と Graph execution では Function の動作が異なることがあります。Python の print 関数がその例です。関数に print ステートメントを挿入して、それを繰り返し呼び出すとどうなるかを見てみましょう。
@tf.function
def get_MSE(y_true, y_pred):
print("Calculating MSE!")
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
何が出力されるか観察しましょう。
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE!
この出力に驚きましたか?get_MSE は 3 回呼び出されたにもかかわらず、出力されたのは 1 回だけでした。
説明すると、print ステートメントは Function が「トレーシング」というプロセスでグラフを作成するために元のコードを実行したときに実行されます(tf.function ガイドのトレーシングセクションをご覧ください)。トレーシングは、TensorFlow 演算をグラフにキャプチャしますが、グラフには print はキャプチャされません。以降、そのグラフは Python コードを再実行せずに、3 つのすべての呼び出しに対して実行されます。
サニティーチェックとして、Graph execution をオフにして比較してみましょう。
# Now, globally set everything to run eagerly to force eager execution.
tf.config.run_functions_eagerly(True)
# Observe what is printed below.
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE! Calculating MSE! Calculating MSE!
tf.config.run_functions_eagerly(False)
print は Python の副作用です。違いは他にもあり、関数を Function に変換する場合には注意が必要です。詳細については、tf.function でパフォーマンスを向上ガイドの制限セクションをご覧ください。
注意: Eager execution と Graph execution の両方で値を出力する場合は、代わりに tf.print を使用してください。
Non-strict execution
Graph execution は、観測可能な効果を生成するために必要な演算のみを実行するもので、次が含まれています。
- 関数の戻り値
- 以下のような、文書化された既知の副作用
- 入力/出力演算。
tf.printなど。 - デバッグ演算。
tf.debuggingのアサート関数など。 tf.Variableのミューテーション
- 入力/出力演算。
この動作は、「Non-strict execution」としてよく知られており、Eager execution とは異なり、必要であるかに関係なく、すべてのプログラム演算をステップします。
具体的には、ランタイムエラーチェックは観測可能な効果として考慮されません。演算が不要であるがためにスキップされると、その演算はランタイムエラーをスローできません。
次の例では、Graph execution 中に「不要な」演算 tf.gather がスキップされるため、Eager execution とは異なり、ランタイムエラーの InvalidArgumentError は発生しません。グラフの実行中にはエラーが発生することをあまり信頼しないようにしましょう。
def unused_return_eager(x):
# Get index 1 will fail when `len(x) == 1`
tf.gather(x, [1]) # unused
return x
try:
print(unused_return_eager(tf.constant([0.0])))
except tf.errors.InvalidArgumentError as e:
# All operations are run during eager execution so an error is raised.
print(f'{type(e).__name__}: {e}')
tf.Tensor([0.], shape=(1,), dtype=float32)
@tf.function
def unused_return_graph(x):
tf.gather(x, [1]) # unused
return x
# Only needed operations are run during graph execution. The error is not raised.
print(unused_return_graph(tf.constant([0.0])))
tf.Tensor([0.], shape=(1,), dtype=float32)
tf.function のベストプラクティス
It may take some time to get used to the behavior of Function. To get started quickly, first-time users should play around with decorating toy functions with @tf.function to get experience with going from eager to graph execution.
tf.function の設計は、グラフ互換の TensorFlow プログラムを作成するための最良の策かもしれません。いくつかのヒントを次に示します。
- 早い段階で Eager execution と Graph execution を切り替えながら、2 つのモードで異なる結果を得るかどうか、またはそのタイミングを知るために
tf.config.run_functions_eagerlyを頻繁に使用しましょう。 - Python 関数の外で
tf.Variableを作成し、Python 関数内で変更するようにします。これは、tf.keras.layers、tf.keras.Model、tf.keras.optimizersなどのtf.Variableを使用するオブジェクトでも同じです。 tf.Variableと Keras オブジェクトを除いて、外部の Python 変数に依存する関数を書くことは避けてください。tf.functionガイドの Python のグローバル変数と自由変数に依存するで詳細を確認してください。- テンソルと他の TensorFlow 型を入力として取る関数を記述するようにしましょう。他の型のオブジェクトを渡すことは可能ですが、十分な注意が必要です!
tf.functionガイドの Python オブジェクトに依存するで詳細を確認してください。 - パフォーマンスを最大限に得るには、
tf.functionの下にできるだけ多くの計算を含めるようにしましょう。たとえば、トレーニングステップ全体またはトレーニングループ全体をデコレートすることができます。
高速化の確認
コードのパフォーマンスは通常、tf.function によって改善されますが、改善率は実行する計算によって異なります。 小さな計算であれば、グラフ呼び出しのオーバーヘッドに制約を受ける可能性があります。パフォーマンスの変化は、次のようにして確認することができます。
x = tf.random.uniform(shape=[10, 10], minval=-1, maxval=2, dtype=tf.dtypes.int32)
def power(x, y):
result = tf.eye(10, dtype=tf.dtypes.int32)
for _ in range(y):
result = tf.matmul(x, result)
return result
print("Eager execution:", timeit.timeit(lambda: power(x, 100), number=1000), "seconds")
Eager execution: 4.002248740000141 seconds
power_as_graph = tf.function(power)
print("Graph execution:", timeit.timeit(lambda: power_as_graph(x, 100), number=1000), "seconds")
Graph execution: 0.8218019930000082 seconds
tf.function は一般的にトレーニングループを高速化するために使用されます。詳細については、Keras ガイドのトレーニングループを新規作成するの{nbsp}tf.function を使用してトレーニングステップを高速化するセクションで詳細を確認してください。
注意: パフォーマンスをさらに大きく改善させるには、tf.function(jit_compile=True) を使用することもできます。特に、コードで大量の TensorFlow 制御フローが使用されており、小さなテンソルが多数使用されている場合に最適です。詳細については、XLA の概要の tf.function(jit_compile=True) を使用した明示的なコンパイルセクションをご覧ください。
パフォーマンスとトレードオフ
グラフを使ってコードを高速化することは可能ですが、グラフを作成するプロセスにはオーバーヘッドが伴います。一部の関数の場合、グラフの作成にはグラフを実行するよりも長い時間が掛かることがあります。このオーバーヘッドは、以降の実行においてパフォーマンスが向上するのであれば挽回することができますが、大規模なモデルトレーニングの最初の数ステップではトレーシングにより速度が減少する可能性があることに注意してください。
モデルの規模に関係なく、頻繁にトレースするのは避けたほうがよいでしょう。tf.function ガイドでは、トレーシングを回避できるよう、リトレーシングの制御セクションで入力仕様を設定してテンソル引数を使用する方法を説明しています。パフォーマンスが異常に低下している場合は、リトレーシングをうっかり行っていないかどうかを確認することをお勧めします。
Function がトレーシングしているタイミングを確認するには
Function がトレーシングしているタイミングを確認するには、コードに print ステートメントを追加すれば、Function がトレーシングを行うたびに print ステートメントが実行されるようになります。
@tf.function
def a_function_with_python_side_effect(x):
print("Tracing!") # An eager-only side effect.
return x * x + tf.constant(2)
# This is traced the first time.
print(a_function_with_python_side_effect(tf.constant(2)))
# The second time through, you won't see the side effect.
print(a_function_with_python_side_effect(tf.constant(3)))
Tracing! tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(11, shape=(), dtype=int32)
# This retraces each time the Python argument changes,
# as a Python argument could be an epoch count or other
# hyperparameter.
print(a_function_with_python_side_effect(2))
print(a_function_with_python_side_effect(3))
Tracing! tf.Tensor(6, shape=(), dtype=int32) Tracing! tf.Tensor(11, shape=(), dtype=int32)
新しい Python 引数は、必ず新しいグラフの作成をトリガーするため、追加のトレーシングが行われます。
次のステップ
tf.function についてさらに詳しくは、API リファレンスページをご覧ください。また、tf.function によるパフォーマンスの改善ガイドもお試しください。